


Giant language fashions (LLMs) have revolutionized how machines course of and generate human language, however their capability to purpose successfully throughout numerous duties stays a big problem. Researchers in AI are working to allow these fashions to carry out not simply language understanding but in addition advanced reasoning duties like problem-solving in arithmetic, logic, and normal information. The main focus is creating methods that may carry out reasoning-based duties autonomously and precisely throughout varied domains.
One of many crucial issues confronted by AI researchers is that many present strategies for enhancing LLM reasoning capabilities rely closely on human intervention. These strategies typically require meticulous human-designed reasoning examples or using superior fashions, each of that are pricey and time-consuming. Moreover, when LLMs are examined on duties outdoors their unique coaching area, they lose accuracy, revealing that present methods have to be actually generalists of their reasoning capabilities. This hole in efficiency throughout assorted duties presents a barrier to creating adaptable, general-purpose AI methods.
A number of current strategies purpose to sort out this difficulty. These approaches sometimes immediate LLMs to generate reasoning steps, typically known as chain-of-thought (CoT) reasoning, and filter these steps primarily based on the result or self-consistency. Nonetheless, these strategies, similar to STaR and LMSI, have limitations. They make the most of small, mounted units of human-designed reasoning paths that assist the fashions carry out nicely in duties much like these they had been skilled on however wrestle when utilized to out-of-domain (OOD) duties, limiting their total usefulness. Thus, whereas these fashions can improve reasoning in a managed setting, they should generalize and supply constant efficiency when confronted with new challenges.
In response to those limitations, researchers from Salesforce AI Analysis launched a novel technique known as ReGenesis. This technique permits LLMs to self-improve their reasoning talents with out requiring further human-designed examples. ReGenesis allows fashions to synthesize their reasoning paths as post-training knowledge, serving to them adapt to new duties extra successfully. By progressively refining reasoning from summary tips to task-specific constructions, the tactic addresses the shortcomings of current fashions and helps construct a extra generalized reasoning functionality.
The methodology behind ReGenesis is structured into three key phases. First, it generates broad, task-agnostic reasoning tips which can be normal ideas relevant to varied duties. These tips aren’t tied to any explicit drawback, which permits the mannequin to keep up flexibility in its reasoning. Subsequent, these summary tips are tailored into task-specific reasoning constructions, permitting the mannequin to develop extra centered reasoning methods for explicit issues. Lastly, the LLM makes use of these reasoning constructions to create detailed reasoning paths. As soon as the paths are generated, the mannequin filters them utilizing ground-truth solutions or majority-vote strategies to eradicate incorrect options. This course of, subsequently, enhances the mannequin’s reasoning capabilities with out counting on predefined examples or in depth human enter, making all the course of extra scalable and efficient for a variety of duties.
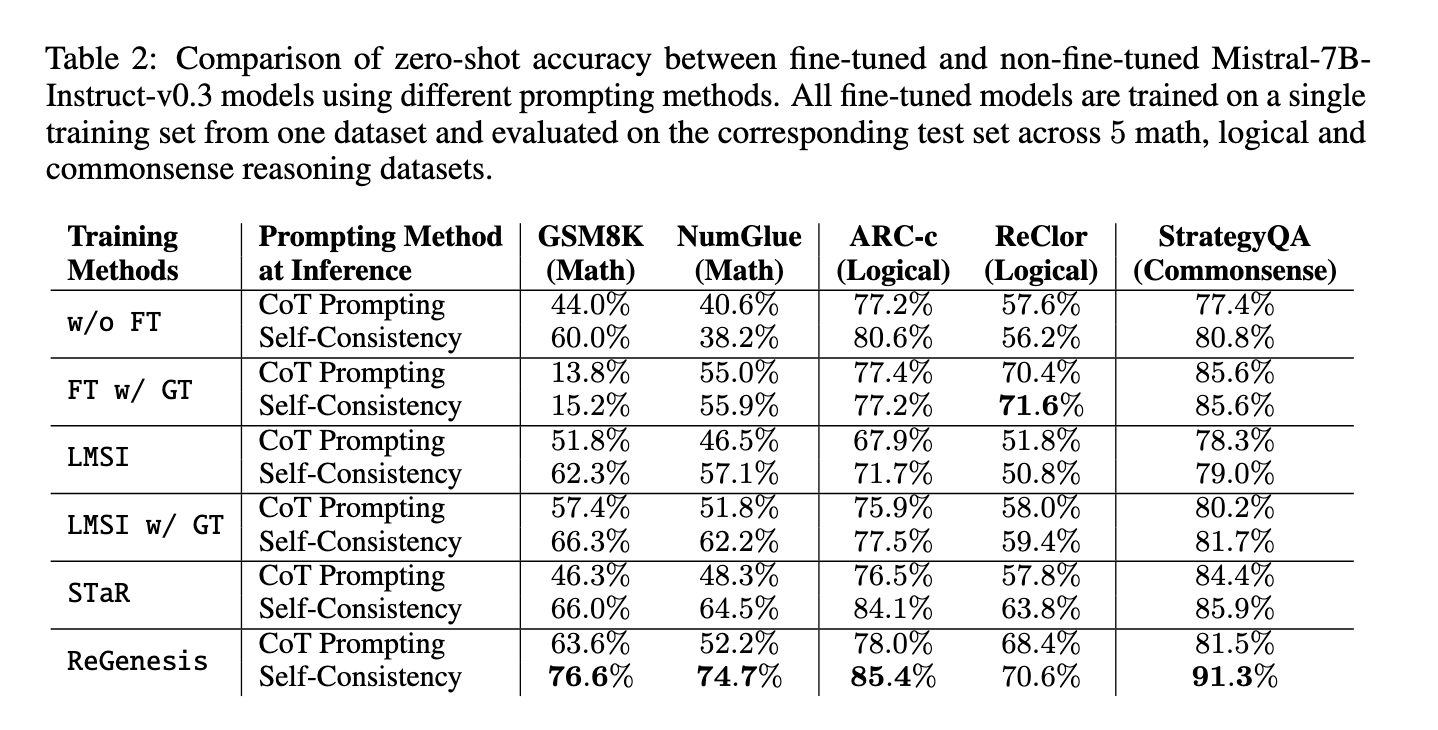
The outcomes of implementing ReGenesis are spectacular. The researchers evaluated the tactic throughout in- and out-of-domain duties and noticed that ReGenesis persistently outperformed current strategies. Particularly, ReGenesis delivered a 6.1% enchancment in OOD duties, whereas different fashions exhibited a mean efficiency drop of 4.6%. In a single set of evaluations involving six OOD duties like mathematical reasoning and logic, ReGenesis managed to keep up its efficiency, whereas different fashions noticed a big decline after post-training. On in-domain duties, similar to people who the fashions had been initially skilled on, ReGenesis additionally confirmed superior efficiency. For instance, it achieved between 7.1% and 18.9% higher outcomes throughout varied duties, together with common sense reasoning and mathematical problem-solving.
Extra detailed outcomes from ReGenesis additional spotlight its effectiveness. For six OOD duties, together with math, logic, and pure language inference, ReGenesis confirmed a constant enchancment in accuracy. In a single occasion, the mannequin exhibited a 6.1% enhance in OOD efficiency, in distinction to the 4.6% common efficiency drop seen in baseline strategies. Additional, whereas current strategies like STaR suffered from declines in accuracy when utilized to new duties, ReGenesis might keep away from this decline and display tangible enhancements, making it a extra strong answer for reasoning generalization. In one other analysis involving 5 in-domain duties, ReGenesis outperformed 5 baseline strategies by a margin of seven.1% to 18.9%, additional underscoring its superior capability to purpose via numerous duties successfully.
In conclusion, introducing ReGenesis by Salesforce AI Analysis addresses a big hole in growing LLMs. By enabling fashions to self-synthesize reasoning paths from normal tips and adapt them to particular duties, ReGenesis supplies a scalable answer to enhance each in-domain and out-of-domain efficiency. The strategy’s capability to boost reasoning with out counting on pricey human supervision or task-specific coaching knowledge marks an essential step ahead in growing AI methods that may actually generalize throughout a variety of duties. The efficiency positive factors reported in in- and out-of-domain duties make ReGenesis a promising software for advancing reasoning capabilities in AI.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Tremendous-Tuned Fashions: Predibase Inference Engine (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


