


The important thing problem within the picture autoencoding course of is to create high-quality reconstructions that may retain high quality particulars, particularly when the picture knowledge has undergone compression. Conventional autoencoders, which depend on pixel-level losses resembling imply squared error (MSE), have a tendency to provide blurry outputs with out capturing high-frequency particulars, textual info, and edge info. Whereas adversarial strategies, as utilized by generative adversarial networks (GANs), have helped improve the realism of reconstructions, they introduce different issues: instability in coaching and an incapacity to attain excessive variability in generated photos on account of their deterministic nature. Overcoming these challenges is essential for enhancing functions in picture technology, compression, and real-time video synthesis—constancy and variety being inalienable.
The mainstream current strategies strategy this drawback primarily by enhancing the pixel-level losses with additional penalties, together with perceptual and adversarial losses. Particularly, GAN-based strategies have proven nice efficiency in producing real looking textures; nonetheless, they nonetheless have important limitations. For instance, GANs are arduous to coach due to instability and are delicate to hyperparameter tuning. Moreover, their outputs should not assorted since trendy GAN architectures are inherently deterministic; subsequently, they’ll present just one reconstruction for a given latent illustration. These strategies additionally take heavy computation and subsequently don’t apply in eventualities that require effectivity or run in real-time.
In an try to beat these challenges, researchers from Google launched “Pattern What You Can’t Compress,” which {couples} autoencoder-based illustration studying with diffusion fashions. This strategy includes stochastic decoding for extra assorted and high-quality reconstructions from a compressed latent house. One of many key elements of SWYCC is the applying of a diffusion course of, whereby the randomness throughout reconstruction helps generate particulars at a finer degree that isn’t attainable by conventional, moderately deterministic, methods. In contrast to GAN-based fashions, SWYCC can provide a number of, assorted outputs from one single latent illustration by enhancing high quality and variety. Nevertheless, the truth that tuning is far simpler and that it could possibly scale higher, on account of a sound theoretical foundation of diffusion fashions, makes this class of strategies a really critical and highly effective various to GANs within the framework of picture reconstruction.
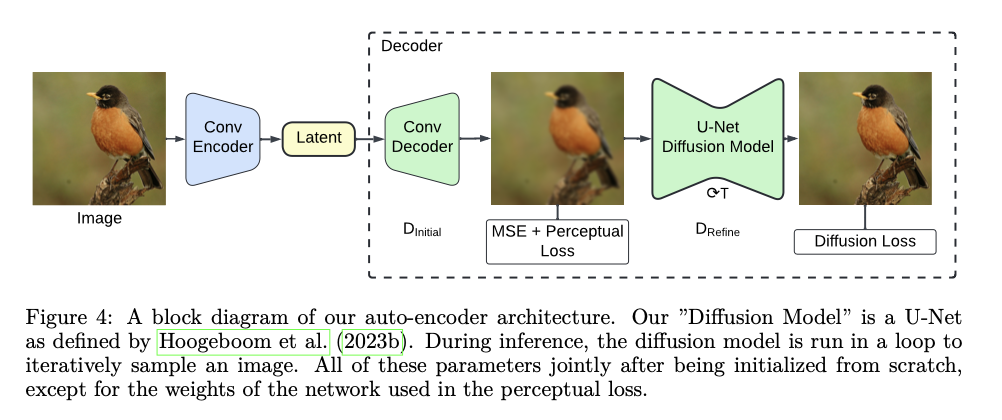
SWYCC makes use of a totally convolutional encoder primarily based on MaskGIT structure coupled with a UNet-based diffusion decoder. An encoder that makes use of ResNet blocks to compress enter photos into compact latent representations, whereas a two-stage picture reconstruction decoder—one first preliminary approximation, DInitial, and one other for refinement, DRefine—permits the mechanism of diffusion loss to information this decoder within the reconstruction course of by explicitly modeling noise corrupting the enter knowledge. The coaching follows a composite loss operate of the parts that contain diffusion, perceptual, and MSE elements, therefore serving to be sure that the mannequin is nice each on the pixel degree and notion. Coaching knowledge used was obtained from the ImageNet dataset, resized into 256 × 256 pixel photos. Among the many coaching methods employed are direct penalization of DInitial outputs, accelerating the convergence, and enhancing efficiency. One other technique used within the efficiency fine-tuning of the mannequin within the technology of photos is the classifier-free steerage scale.
The proposed methodology, SWYCC, outperforms GAN-based autoencoders when it comes to each reconstruction high quality and variability of output. SWYCC has stored the bottom perceptual distortion for all examined compressions measured by CMMD; the reconstructions are sharper with extra detailed content material. Furthermore, the proposed strategy reduces FID by 5%, which signifies that the SWYCC generates photos with larger visible faithfulness and realism in comparison with GANs. What’s extra, SWYCC is doing an amazing job of preserving high-frequency info, like textures and edges, even at excessive compression ratios, whereas making a transparent title for being extraordinarily highly effective in producing perceptually superior and assorted photos.
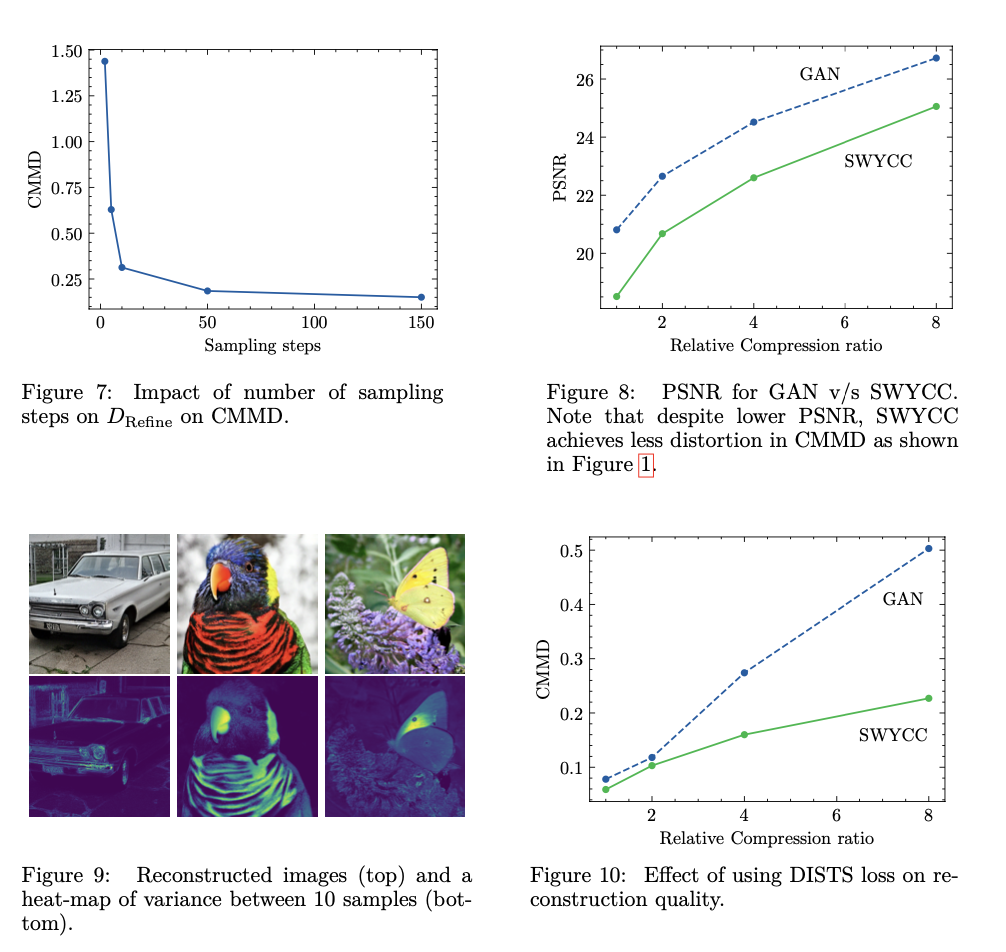
In conclusion, SWYCC supplies a powerful framework for enhancing picture reconstruction and overcomes the challenges of conventional GAN-based fashions by introducing stochastic decoding and using diffusion processes. It is a huge step ahead to be taken within the area of picture autoencoding, contemplating the opportunity of producing sharper, extra fine-grained, and assorted photos at excessive compression. SWYCC simplifies coaching and supplies improved high quality with scalability, thus promising nice potential for steady knowledge domains resembling audio, video, and 3D modeling. This makes SWYCC a extremely valued contribution within the area of AI-driven generative fashions.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving High-quality-Tuned Fashions: Predibase Inference Engine (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.


