

: A Hybrid Method to Reinforcement Studying from Human and AI Suggestions, Fixing Activity Generalization and Suggestions Assortment Challenges")
Reinforcement studying (RL) has been pivotal in advancing synthetic intelligence by enabling fashions to study from their interactions with the surroundings. Historically, reinforcement studying depends on rewards for constructive actions and penalties for detrimental ones. A current method, Reinforcement Studying from Human Suggestions (RLHF), has introduced exceptional enhancements to giant language fashions (LLMs) by incorporating human preferences into the coaching course of. RLHF ensures that AI methods behave in methods aligned with human values. Nonetheless, gathering and processing this suggestions is resource-intensive, requiring giant datasets of human-labeled preferences. With AI methods rising in scale and complexity, researchers are exploring extra environment friendly methods to enhance mannequin efficiency with out relying solely on human enter.
Fashions educated utilizing RLHF want huge quantities of choice knowledge to make choices that align with person expectations. As human knowledge assortment is pricey, the method creates a bottleneck, slowing down mannequin improvement. Additionally, reliance on human suggestions limits fashions’ generalizability to new duties they’ve but to come across throughout coaching. This will result in poor efficiency when fashions are deployed in real-world environments that must deal with unfamiliar or out-of-distribution (OOD) situations. Addressing this problem requires a way that reduces the dependency on human knowledge and improves mannequin generalization.
Present approaches like RLHF have confirmed helpful, however they’ve limitations. In RLHF, fashions are refined primarily based on human-provided suggestions, which includes rating outputs in keeping with person preferences. Whereas this technique improves alignment, it may be inefficient. A current various, Reinforcement Studying from AI Suggestions (RLAIF), seeks to beat this utilizing AI-generated suggestions. A mannequin makes use of predefined tips, or a “structure,” to guage its outputs. Although RLAIF reduces reliance on human enter, current research present that AI-generated suggestions can misalign with precise human preferences, leading to suboptimal efficiency. This misalignment is especially evident in out-of-distribution duties the place the mannequin wants to grasp nuanced human expectations.
SynthLabs and Stanford College researchers launched a hybrid resolution: Generative Reward Fashions (GenRM). This new technique combines the strengths of each approaches to coach fashions extra successfully. GenRM makes use of an iterative course of to fine-tune LLMs by producing reasoning traces, which act as artificial choice labels. These labels higher mirror human preferences whereas eliminating the necessity for intensive human suggestions. The GenRM framework bridges the hole between RLHF and RLAIF by permitting AI to generate its enter and repeatedly refine itself. The introduction of reasoning traces helps the mannequin mimic the detailed human thought course of that improves decision-making accuracy, significantly in additional complicated duties.
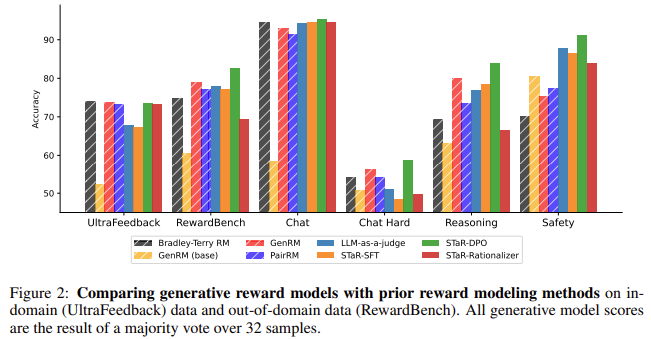
GenRM leverages a big pre-trained LLM to generate reasoning chains that assist decision-making. Chain-of-Thought (CoT) reasoning is integrated into the mannequin’s workflow, the place the AI generates step-by-step reasoning earlier than concluding. This self-generated reasoning serves as suggestions for the mannequin, which is additional refined in iterative cycles. The GenRM mannequin compares favorably in opposition to conventional strategies like Bradley-Terry reward fashions and DPO (Direct Desire Optimization), surpassing them in accuracy by 9-31% in in-distribution duties and 10-45% on out-of-distribution duties. These iterative refinements scale back the useful resource load and enhance the mannequin’s capacity to generalize throughout duties.
In in-distribution duties, the place fashions are examined on issues they’ve seen earlier than, GenRM performs equally to the Bradley-Terry reward mannequin, sustaining excessive accuracy charges. Nonetheless, the true benefit of GenRM is obvious in OOD duties. For example, GenRM outperforms conventional fashions by 26% in generalization duties, making it higher fitted to real-world functions the place AI methods are required to deal with new or sudden situations. Additionally, fashions utilizing GenRM confirmed enhancements in decreasing errors in decision-making and offering extra correct outputs aligned with human values, demonstrating between 9% and 31% improved efficiency in duties requiring complicated reasoning. The mannequin additionally outperformed LLM-based judges, which rely solely on AI suggestions, showcasing a extra balanced method to suggestions optimization.
Key Takeaways from the Analysis:
- Elevated Efficiency: GenRM improves in-distribution process efficiency by 9-31% and OOD duties by 10-45%, displaying superior generalization skills.
- Lowered Dependency on Human Suggestions: AI-generated reasoning traces exchange the necessity for giant human-labeled datasets, dashing up the suggestions course of.
- Improved Out-of-Distribution Generalization: GenRM performs 26% higher than conventional fashions in unfamiliar duties, enhancing robustness in real-world situations.
- Balanced Method: The hybrid use of AI and human suggestions ensures that AI methods keep aligned with human values whereas decreasing coaching prices.
- Iterative Studying: Steady refinement by reasoning chains enhances decision-making in complicated duties, enhancing accuracy and decreasing errors.

In conclusion, the introduction of Generative Reward Fashions presents a robust step ahead in reinforcement studying. Combining human suggestions with AI-generated reasoning permits for extra environment friendly mannequin coaching with out sacrificing efficiency. GenRM solves two vital points: it reduces the necessity for labor-intensive human knowledge assortment whereas enhancing the mannequin’s capacity to deal with new, untrained duties. By integrating RLHF and RLAIF, GenRM represents a scalable and adaptable resolution for advancing AI alignment with human values. The hybrid system boosts in-distribution accuracy and considerably enhances out-of-distribution efficiency, making it a promising framework for the subsequent technology of clever methods.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Tremendous-Tuned Fashions: Predibase Inference Engine (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.


