

 to Present Advantageous-Grained Annotations for Giant Imaginative and prescient Language Fashions")
Imaginative and prescient Language Fashions (VLMs) have demonstrated outstanding capabilities in producing human-like textual content in response to photographs, with notable examples together with GPT-4, Gemini, PaLiGemma, LLaVA, and Llama 3 Imaginative and prescient fashions. Nevertheless, these fashions continuously generate hallucinated content material that lacks correct grounding within the reference pictures, highlighting a essential flaw of their output reliability. The problem of detecting and stopping such hallucinations necessitates efficient reward fashions (RMs) for analysis and enchancment. Present binary classification-based RMs present solely single-score evaluations for total outputs, severely limiting their interpretability and granularity. This coarse analysis method masks the underlying decision-making course of, making it tough for builders to establish particular areas of enchancment and implement focused enhancements in VLM efficiency.
Earlier makes an attempt to enhance VLM efficiency have primarily targeted on Reinforcement Studying from Human Suggestions (RLHF) strategies, which have efficiently enhanced language fashions like ChatGPT and LLaMA 3. These approaches sometimes contain coaching reward fashions on human choice information and utilizing algorithms like Proximal Coverage Optimization (PPO) or Direct Coverage Optimization (DPO) for coverage studying. Whereas some developments have been made with course of reward fashions and step-wise reward fashions, current options for detecting hallucinations are predominantly restricted to the language area and function at sentence-level granularity. Different approaches have explored artificial information technology and laborious destructive mining by way of human annotation, heuristic-based strategies, and hybrid approaches combining computerized technology with handbook verification. Nevertheless, these strategies haven’t adequately addressed the core problem of representing and evaluating visible options in VLMs, which stays a major bottleneck in creating extra dependable vision-language basis fashions.
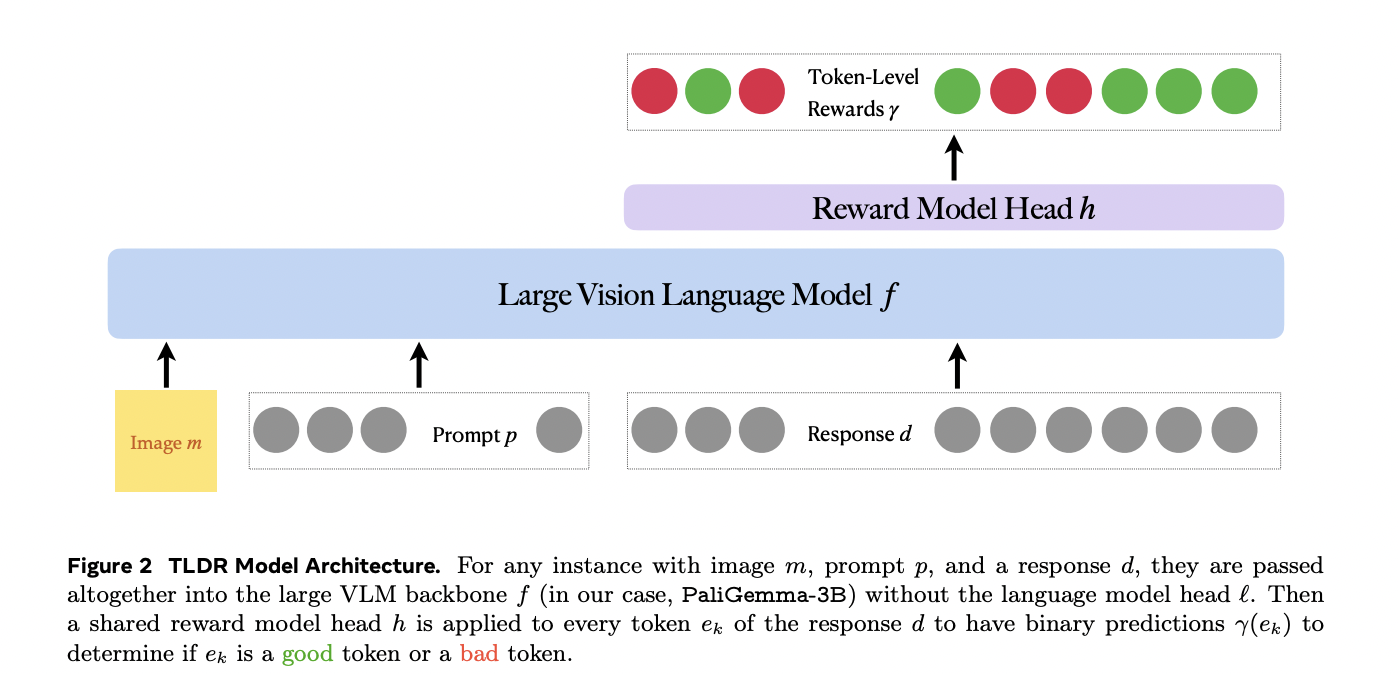
Researchers from Meta and the College of Southern California have launched The Token-Stage Detective Reward (TLDR) mannequin, representing a breakthrough in evaluating VLM outputs by offering token-by-token evaluation moderately than single-score evaluations. This granular method allows exact identification of hallucinations and errors inside the generated textual content, making it significantly precious for human annotators who can shortly establish and proper particular problematic segments. TLDR addresses the inherent bias of binary reward fashions, which are likely to favor longer texts no matter hallucination content material, by incorporating strong visible grounding mechanisms. By means of cautious integration of multimodal cues and enhanced visible function projection strategies, the mannequin achieves considerably improved efficiency in detecting content material misalignment. The system’s structure facilitates seamless integration with current mannequin enchancment strategies like DPO and PPO, whereas concurrently serving as a probability coaching goal that enhances the underlying imaginative and prescient language mannequin’s efficiency.
The TLDR mannequin operates on multimodal query-response situations consisting of a picture, consumer textual content immediate, and textual content response. In contrast to conventional reward fashions that produce binary classifications, TLDR evaluates every token within the response individually, producing a rating between 0 and 1 primarily based on a threshold θ (sometimes 0.5). The mannequin’s efficiency is evaluated utilizing three distinct accuracy metrics: token-level accuracy for particular person token evaluation, sentence-level accuracy for evaluating coherent textual content segments, and response-level accuracy for general output analysis. To deal with information shortage and granularity points, the system employs subtle artificial information technology strategies, significantly specializing in dense captioning and visible question-answering duties. The coaching information is enhanced by way of a scientific perturbation course of utilizing massive language fashions, particularly focusing on eight key taxonomies: spatial relationships, visible attributes, attribute binding, object identification, counting, small object detection, textual content OCR, and counterfactual situations. This complete method ensures strong analysis throughout various visual-linguistic challenges.
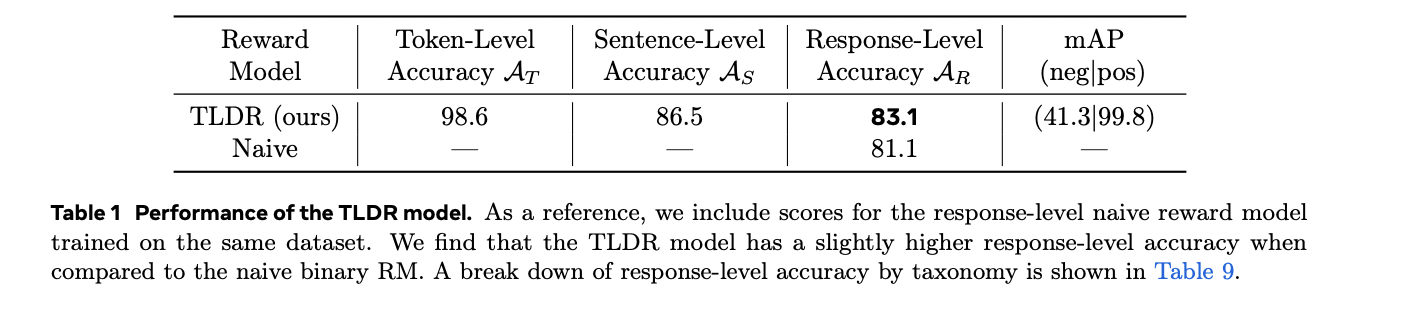
The TLDR mannequin demonstrates strong efficiency throughout a number of analysis metrics when examined on artificial information from the DOCCI dataset. Efficiency evaluation reveals barely superior response-level accuracy in comparison with conventional binary reward fashions, reaching a notable 41.3 mAP(neg) rating. Detailed taxonomy breakdown signifies specific challenges with spatial relationship assessments, aligning with recognized limitations in present VLM applied sciences. Human analysis of token-level predictions on WinoGround pictures, focusing particularly on false negatives, exhibits a modest sentence-level false destructive charge of 8.7%. In sensible functions, TLDR’s effectiveness is demonstrated by way of complete hallucination detection throughout numerous main VLMs, together with Llama-3.2-Imaginative and prescient, GPT-4 variants, MiniCPM, PaLiGemma, and Phi 3.5 Imaginative and prescient. GPT-4o emerges as the highest performer with minimal hallucination charges throughout all granularity ranges. The mannequin’s utility extends to real-world functions, as evidenced by its evaluation of PixelProse dataset, the place it recognized hallucinated tokens in 22.39% of captions, with token-level and sentence-level hallucination charges of 0.83% and 5.23% respectively.

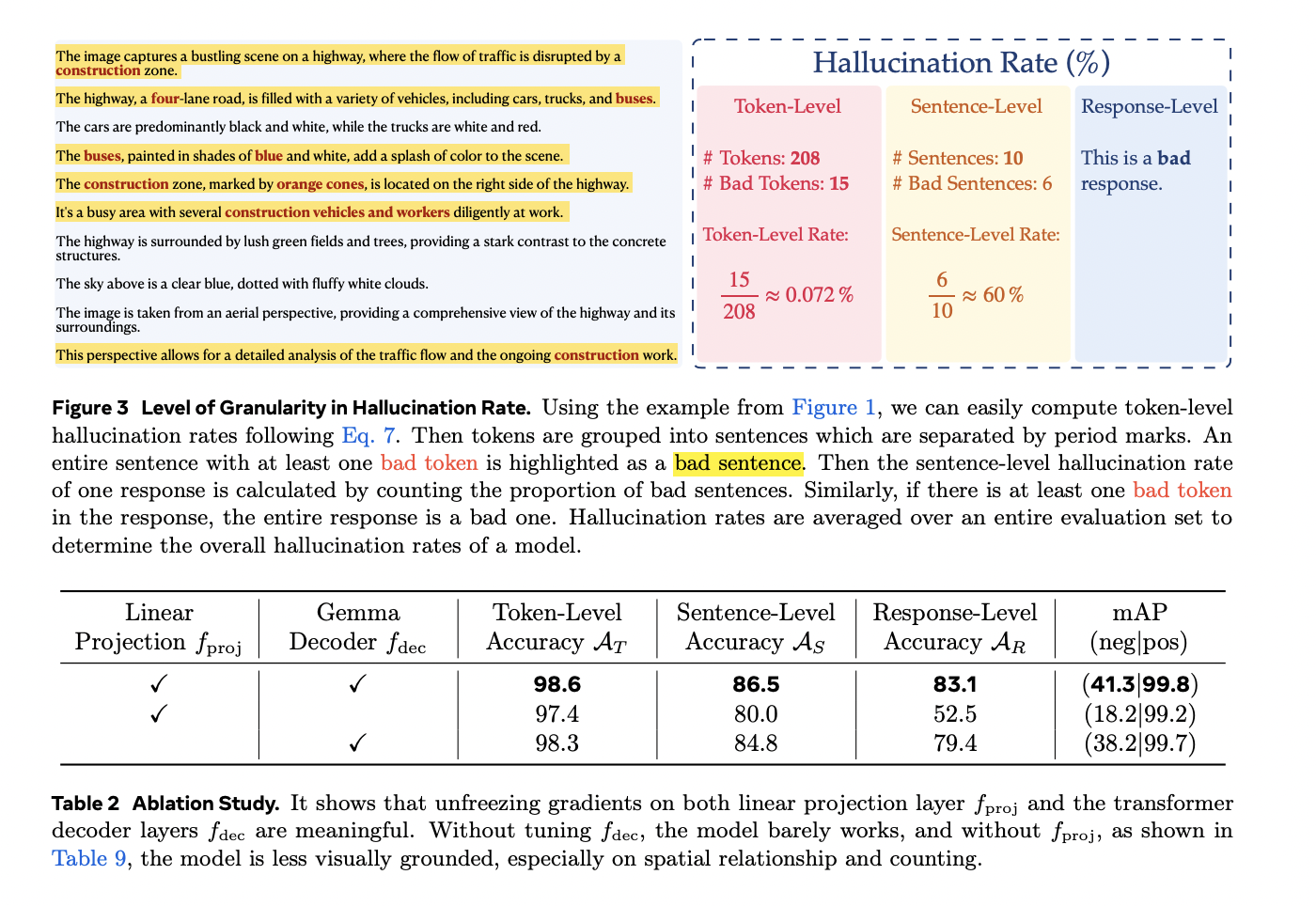

The Token-Stage Detective Reward Mannequin represents a major development in evaluating and enhancing imaginative and prescient language fashions by way of its fine-grained token-level annotation capabilities. Past merely figuring out errors, TLDR pinpoints particular problematic areas, enabling environment friendly self-correction and hallucination detection. The mannequin’s effectiveness extends to sensible functions, serving as a probability optimization methodology and facilitating sooner human annotation processes. This revolutionary method establishes a basis for superior token-level DPO and PPO post-training methodologies, marking a vital step ahead in VLM growth.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Advantageous-Tuned Fashions: Predibase Inference Engine (Promoted)
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


