


Giant Language Fashions (LLMs) have proven outstanding potential in fixing advanced real-world issues, from perform calls to embodied planning and code era. A vital functionality for LLM brokers is decomposing advanced issues into executable subtasks by means of workflows, which function intermediate states to enhance debugging and interpretability. Whereas workflows present prior data to forestall hallucinations, present analysis benchmarks for workflow era face vital challenges. The challenges embrace (a) Restricted scope of eventualities, focusing solely on perform name duties, (b) Sole emphasis on linear relationships between subtasks the place real-world eventualities usually contain extra advanced graph constructions, together with parallelism (c) Evaluations closely depend on GPT-3.5/4.
Present strategies in workflow era have primarily targeted on three key areas: Giant Language Brokers, Workflow and Agent Planning, and Workflow era and Analysis. Whereas LLM brokers have been deployed throughout numerous domains together with internet interfaces, medical purposes, and coding duties, their planning skills contain both reasoning or environmental interplay. Present analysis frameworks try to judge workflow era by means of semantic similarity matching and GPT-4 scoring in software studying eventualities. Nonetheless, these strategies are restricted by their deal with linear function-calling, lack of ability to deal with advanced activity constructions, and heavy dependency on probably biased analysis strategies.
Researchers from Zhejiang College and Alibaba Group have proposed WORFBENCH, a benchmark for evaluating workflow era capabilities in LLM brokers. This technique addresses earlier limitations by using multi-faceted eventualities and complicated workflow constructions, validated by means of rigorous information filtering and human analysis. Additional, researchers introduced WORFEVAL, a scientific analysis protocol using superior subsequence and subgraph matching algorithms to judge chain and graph construction workflow era. The experiments reveal there are vital efficiency gaps between sequence and graph planning capabilities, with even superior fashions like GPT-4 displaying roughly a 15% distinction in efficiency.
WORFBENCH’s structure integrates duties and motion lists from established datasets, utilizing a scientific strategy of establishing node chains earlier than constructing workflow graphs. The framework handles two foremost activity classes:
- Perform Name Duties: The system makes use of GPT-4 to reverse-engineer ideas from perform calls utilizing the REACT format, collected from ToolBench and ToolAlpaca. This generates subtask nodes for every step.
- Embodied Duties: Drawn from sources like ALFWorld, WebShop, and AgentInstruct, these duties require a novel strategy resulting from their dynamic environmental nature. As a substitute of one-node-per-action mapping, these duties are decomposed into mounted granularity, with fastidiously designed few-shot prompts for constant workflow era.
Efficiency evaluation reveals vital disparities between linear and graph planning capabilities throughout all fashions. Whereas GLM-4-9B confirmed the most important hole of 20.05%, even the best-performing Llama-3.1-70B demonstrated a 15.01% distinction. In benchmark testing, GPT-4 achieved solely 67.32% and 52.47% in f1chain and f1graph scores respectively, whereas Claude-3.5 topped open-grounded planning duties with 61.73% and 41.49%. As workflow complexity will increase, with extra nodes and edges, efficiency constantly declines resulting in decrease scores. Evaluation of low-performing samples recognized 4 main error sorts: insufficient activity granularity, obscure subtask descriptions, incorrect graph constructions, and format non-compliance.
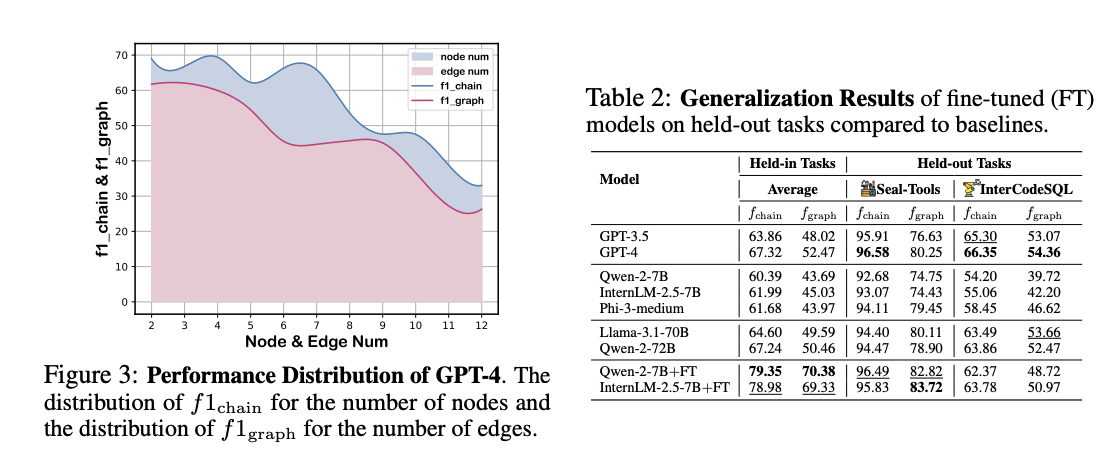
In conclusion, researchers launched WORFBENCH, a way to judge workflow era capabilities in LLM brokers. Via the WORFEVAL system’s quantitative algorithms, the researchers revealed substantial efficiency gaps between linear and graph-structured workflow era throughout numerous LLM architectures. The paper highlights the present limitations of LLM brokers in advanced workflow planning and offers a basis for future enhancements in agent structure growth. Nonetheless, the proposed technique has some limitations. Whereas imposing strict high quality management on the node chain and workflow graph, some queries may need high quality points. Additionally, the workflow presently follows a one-pass era paradigm and assumes all nodes require traversal to finish the duty.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Positive-Tuned Fashions: Predibase Inference Engine (Promoted)

Sajjad Ansari is a remaining yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.

