


When making use of Reinforcement Studying (RL) to real-world functions, two key challenges are sometimes confronted throughout this course of. Firstly, the fixed on-line interplay and replace cycle in RL locations main engineering calls for on massive methods designed to work with static ML fashions needing solely occasional offline updates. Secondly, RL algorithms often begin from scratch, relying solely on info gathered throughout these interactions, limiting each their effectivity and flexibility. In widespread conditions the place RL is utilized, there are often earlier efforts utilizing rule-based or supervised ML strategies that produce numerous helpful knowledge about good and unhealthy behaviors. Ignoring this info results in inefficient studying in RL from the start.
Present strategies in Reinforcement Studying contain an internet interaction-then-update cycle, which may be inefficient for large-scale methods. These approaches embody overlooking worthwhile, already obtainable knowledge from rule-based or supervised machine-learning strategies and studying from scratch. Many RL strategies depend on worth operate estimation and require entry to Markov Choice Course of (MDP) dynamics, usually using Q-learning methods with per-timestep rewards for correct credit score project. Nevertheless, these strategies rely upon dense rewards and performance approximators, making them unsuitable for offline RL situations with aggregated reward indicators. To handle this, researchers have proposed an imitation learning-based algorithm that integrates trajectories from a number of baseline insurance policies to create a brand new coverage that exceeds the efficiency of the most effective mixture of those baselines. This strategy reduces pattern complexity and will increase efficiency by manipulating present knowledge.
A gaggle of researchers from Google AI have proposed a way involving accumulating trajectories from Okay baseline insurance policies, every excelling in numerous components of the state area. The paper addresses a Contextual Markov Choice Course of (MDP) with finite horizons, the place every baseline coverage has context-dependent deterministic transitions and rewards. Given baseline insurance policies and trajectory knowledge, the aim is to establish a coverage from a given class that competes with the best-performing baseline for every context. This includes offline imitation studying with sparse trajectory-level rewards, complicating conventional strategies reliant on worth operate approximation. The proposed BC-MAX algorithm chooses the trajectory with the very best cumulative reward per context and clones it, specializing in matching optimum motion sequences. In contrast to strategies requiring entry to detailed state transitions or worth features, BC-MAX operates below restricted reward knowledge, optimizing a cross-entropy loss as a proxy to direct coverage studying. The paper offers theoretical remorse bounds for BC-MAX, guaranteeing efficiency near the most effective baseline coverage for every context.
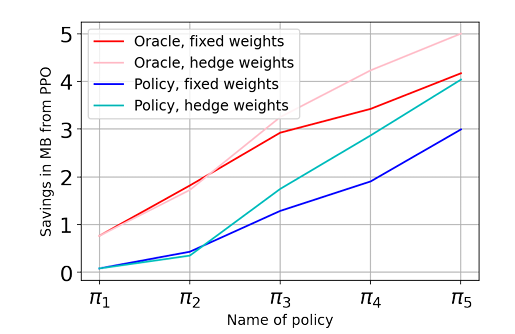
On this, the limitation studying algorithm combines trajectories to be taught a brand new coverage. The researchers present a pattern complexity sure on the algorithm’s accuracy and show its minimax optimality. They apply this algorithm to compiler optimization, particularly for inlining applications to create smaller binaries. The outcomes confirmed that the brand new coverage outperforms an preliminary coverage realized by way of commonplace RL after a couple of iterations. It introduces BC-MAX, a habits cloning algorithm designed to optimize efficiency by executing a number of insurance policies throughout preliminary states and imitating the trajectory with the very best reward in every state. The authors present an higher sure on the anticipated remorse of the realized coverage relative to the utmost achievable reward in every beginning state by selecting the right baseline coverage. The evaluation features a decrease sure, demonstrating that additional enchancment is proscribed to polylogarithmic elements on this context. Utilized to 2 real-world datasets for optimizing compiler inlining for binary measurement, BC-MAX outperforms robust baseline insurance policies. Beginning with a single on-line RL-trained coverage, BC-MAX iteratively incorporates earlier insurance policies as baselines, reaching sturdy insurance policies with restricted environmental interplay. This strategy reveals vital potential for difficult real-world functions.
In conclusion, the paper presents a novel offline imitation studying algorithm, BC-MAX, which successfully leverages a number of baseline insurance policies to optimize compiler inlining selections. The tactic addresses the constraints of present RL approaches by using prior knowledge and minimizing the necessity for on-line updates by leveraging a number of baselines, proposing a novel imitation studying algorithm that improves efficiency and reduces pattern complexity, significantly in compiler optimization duties. It additionally demonstrated {that a} coverage may be realized that outperforms an preliminary coverage realized by way of commonplace RL by means of a couple of iterations of our strategy. This analysis can function a baseline for future improvement in RL!
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Wonderful-Tuned Fashions: Predibase Inference Engine (Promoted)
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and clear up challenges.


