


Giant Language Fashions (LLMs) have revolutionized long-context query answering (LCQA), a posh process requiring reasoning over intensive paperwork to offer correct solutions. Whereas current long-context LLMs like Gemini and GPT4-128k can course of complete paperwork straight, they wrestle with the “misplaced within the center” phenomenon, the place related info in the midst of paperwork typically results in suboptimal or incorrect responses. Retrieval-Augmented Technology (RAG) programs try to handle this through the use of fixed-length chunking methods, however they face their very own limitations. These embody the disruption of contextual construction, incomplete info in chunks, and challenges with low proof density in lengthy paperwork, the place noise can impair the LLMs’ capacity to establish key info precisely. These points collectively hinder the event of dependable LCQA programs.
A number of approaches have emerged to handle the challenges in long-context query answering. Lengthy-context LLM strategies fall into two classes: training-based approaches like Place Interpolation, YaRN, and LongLoRA, which provide higher efficiency however require important sources, and non-fine-tuned strategies corresponding to restricted consideration and context compression, which give plug-and-play options at decrease prices. Conventional RAG programs tried to enhance LLMs’ response high quality by using exterior information sources, however their direct incorporation of retrieved chunks led to incomplete info and noise. Superior RAG fashions launched options like filtering retrieved information, implementing chunk-free methods to protect semantics, and using lively retrieval mechanisms. Area-specific fine-tuning has additionally emerged as a technique to reinforce RAG elements, specializing in bettering retrieval outcomes and producing extra personalised outputs.
Researchers from Institute of Info Engineering, Chinese language Academy of Sciences, College of Cyber Safety, College of Chinese language Academy of Sciences, Tsinghua College and Zhipu AI introduce LongRAG, a complete answer to LCQA challenges by way of a dual-perspective, strong system paradigm comprising 4 plug-and-play elements: a hybrid retriever, an LLM-augmented info extractor, a CoT-guided filter, and an LLM-augmented generator. The system’s revolutionary strategy addresses each world context understanding and factual element identification. The long-context extractor employs a mapping technique to rework retrieved chunks right into a higher-dimensional semantic area, preserving contextual relationships, whereas the CoT-guided filter makes use of Chain of Thought reasoning to offer world clues and exactly filter irrelevant info. This dual-perspective strategy considerably enhances the system’s capacity to course of complicated, prolonged contexts whereas sustaining accuracy. The system’s structure is complemented by an automatic instruction knowledge pipeline for fine-tuning, enabling robust “instruction-following” capabilities and simple area adaptation.
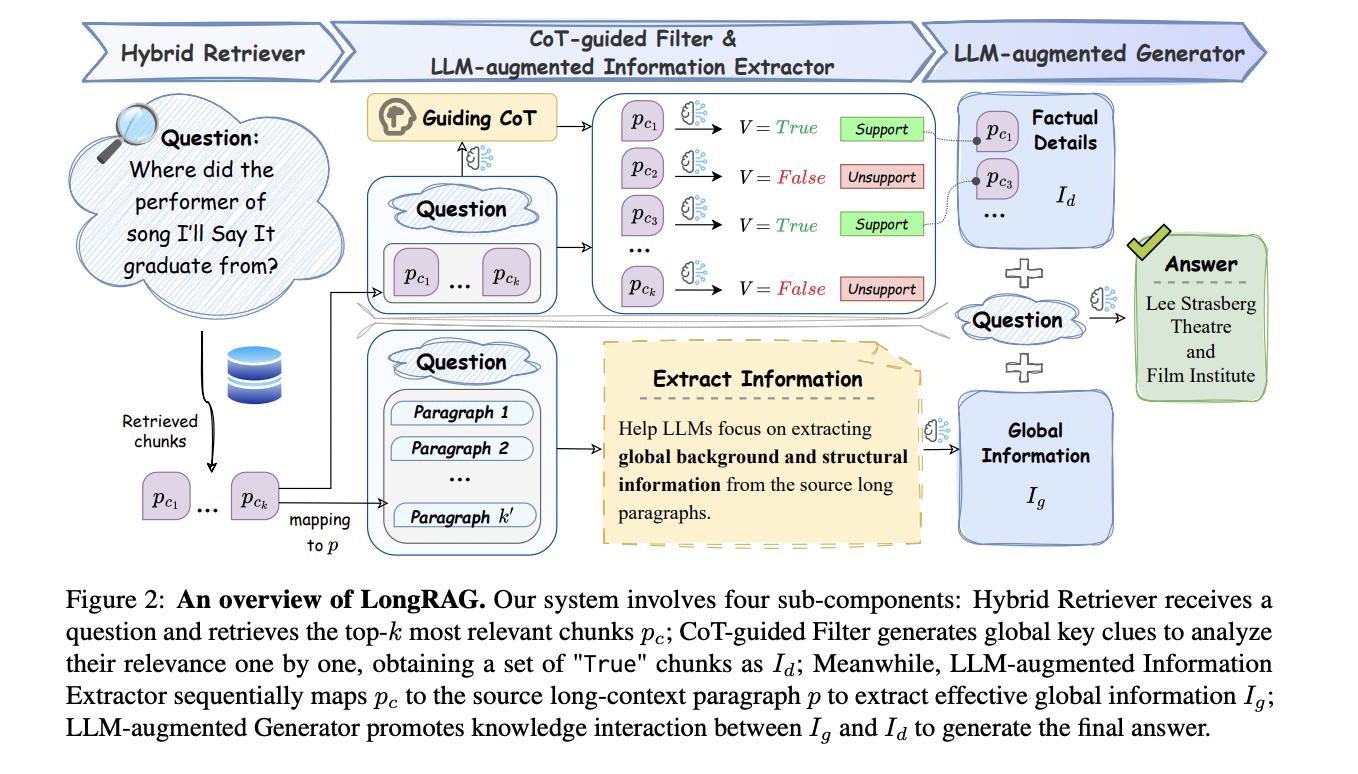
LongRAG’s structure consists of 4 refined elements working in concord. The hybrid retriever employs a dual-encoder construction with sliding home windows for chunk segmentation, combining coarse-grained fast retrieval with fine-grained semantic interplay by way of FAISS implementation. The LLM-augmented info extractor addresses scattered proof by mapping retrieved chunks again to supply paragraphs utilizing a mapping perform, preserving semantic order and contextual relationships. The CoT-guided filter implements a two-stage technique: first producing Chain of Thought reasoning with a world perspective, then utilizing these insights to guage and filter chunks primarily based on their relevance to the query. Lastly, the LLM-augmented generator synthesizes the worldwide info and filtered factual particulars to provide correct solutions. The system’s effectiveness is enhanced by way of instruction-tuning utilizing 2,600 high-quality knowledge factors from LRGinstruction, with fashions educated utilizing superior methods like DeepSpeed and flash consideration.
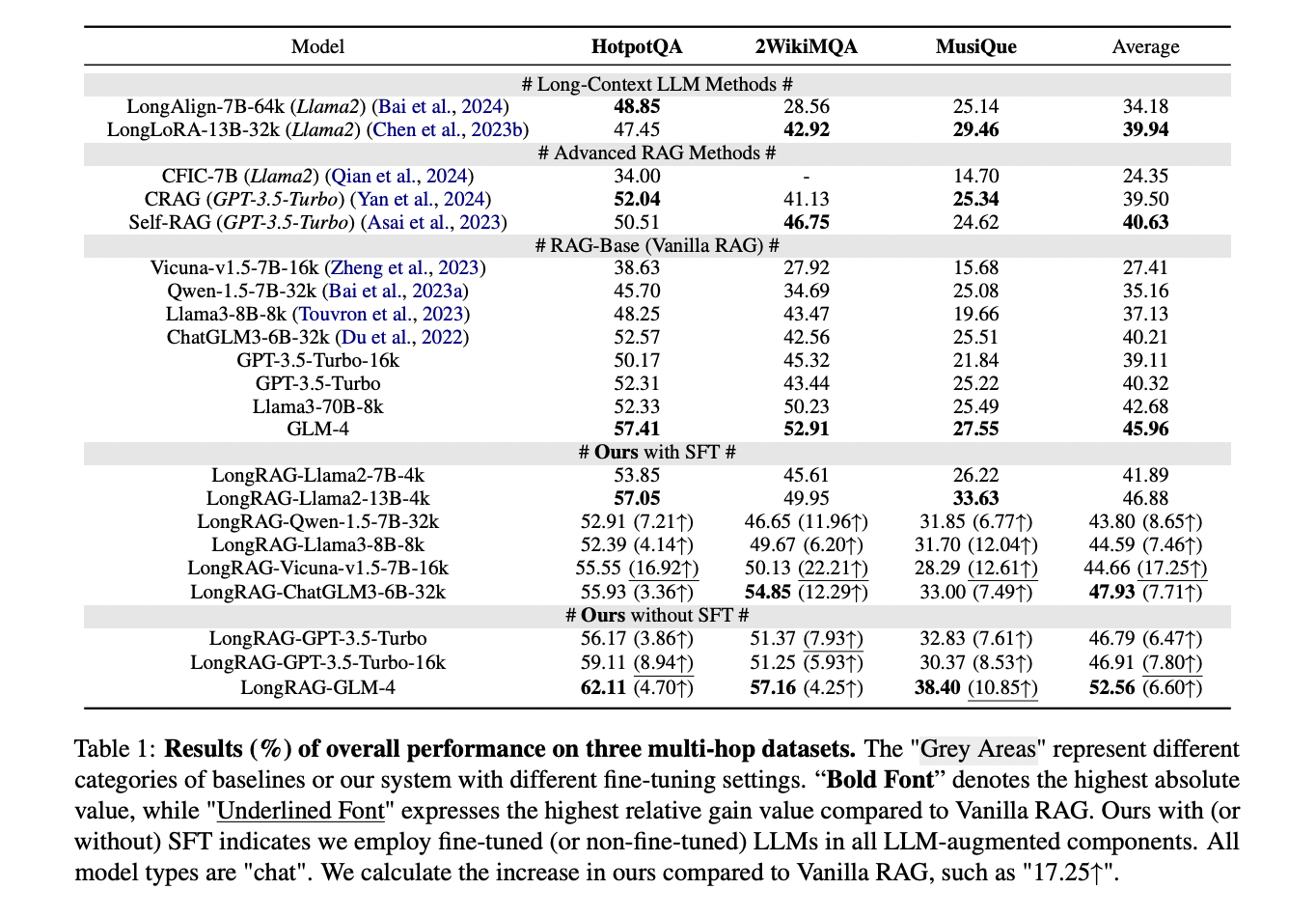
LongRAG demonstrates superior efficiency throughout a number of comparative dimensions. When in comparison with long-context LLM strategies like LongAlign and LongLoRA, the system achieves greater efficiency throughout all datasets, notably in detecting essential factual particulars that different fashions typically miss in mid-document sections. In comparison with superior RAG programs, LongRAG exhibits a 6.16% enchancment over main rivals like Self-RAG, primarily resulting from its extra strong dealing with of factual particulars and complicated multi-hop questions. The system’s most dramatic enchancment seems compared to Vanilla RAG, exhibiting as much as a 17.25% efficiency improve, attributed to its superior preservation of coherent long-context background and construction. Notably, LongRAG’s effectiveness extends throughout each small and huge language fashions, with fine-tuned ChatGLM3-6B-32k outperforming even non-fine-tuned GPT-3.5-Turbo, demonstrating the system’s strong structure and efficient instruction-following capabilities.
LongRAG emerges as a strong answer within the area of long-context query answering by way of its revolutionary twin info perspective strategy. The system successfully addresses two crucial challenges which have plagued present strategies: the unfinished assortment of long-context info and the imprecise identification of factual info in noisy environments. Via complete multidimensional experiments, LongRAG demonstrates not solely superior efficiency over long-context LLMs, superior RAG strategies, and Vanilla RAG but in addition outstanding cost-effectiveness. The system’s plug-and-play elements obtain higher outcomes than GPT-3.5-Turbo whereas utilizing smaller parameter-size LLMs, making it a sensible answer for native deployment with out counting on costly API sources.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An In depth Assortment of Small Language Fashions (SLMs) for Intel PCs
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.
")

