

 1B to 4B, Attaining 90% of the Efficiency with Solely 5% of the Parameters")
Multimodal giant language fashions (MLLMs) quickly evolve in synthetic intelligence, integrating imaginative and prescient and language processing to reinforce comprehension and interplay throughout numerous knowledge sorts. These fashions excel in duties like picture recognition and pure language understanding by combining visible and textual knowledge processing into one coherent framework. This built-in strategy permits MLLMs to carry out extremely on duties requiring multimodal inputs, proving precious in fields resembling autonomous navigation, medical imaging, and distant sensing, the place simultaneous visible and textual knowledge evaluation is crucial.
Regardless of their benefits, MLLMs face substantial limitations on account of their computational depth and in depth parameter necessities, limiting their adaptability on gadgets with constrained assets. Many MLLMs depend on general-purpose coaching knowledge, typically derived from web sources, which impacts their efficiency when utilized to specialised domains. This reliance on huge datasets and large-scale computing energy creates vital boundaries to deploying these fashions for duties requiring nuanced, domain-specific understanding. These challenges are amplified in fields like distant sensing or autonomous driving, the place area adaptation is essential however advanced and dear.
Current MLLMs sometimes incorporate imaginative and prescient encoders like CLIP, designed to align imaginative and prescient knowledge with language fashions for a cohesive multimodal framework. Nevertheless, these fashions typically encounter limitations in specialised domains on account of a scarcity of complete visible information throughout these fields. Most present MLLMs use pre-trained imaginative and prescient encoders aligned with giant language fashions, which require substantial changes to their structure and coaching schedules when utilized to completely different domains. This course of, although efficient, will be inefficient and makes deploying these fashions on smaller gadgets difficult, as their reliance on internet-domain knowledge limits their potential to adapt seamlessly to domain-specific duties with out in depth reconfiguration.
Researchers from Shanghai AI Laboratory, Tsinghua College, Nanjing College, Fudan College, The Chinese language College of Hong Kong, SenseTime Analysis and Shanghai Jiao Tong College have launched Mini-InternVL, a collection of light-weight MLLMs with parameters starting from 1B to 4B to ship environment friendly multimodal understanding throughout varied domains. Mini-InternVL seeks to take care of 90% of the efficiency of bigger multimodal fashions utilizing solely 5% of the parameters, making it each resource-effective and accessible on consumer-grade gadgets. The analysis staff designed Mini-InternVL as a pocket-sized resolution adaptable to duties resembling autonomous driving, medical imaging, and distant sensing whereas providing decrease computational overhead than conventional MLLMs. By making a unified adaptation framework, Mini-InternVL helps efficient mannequin switch throughout domains, selling accessibility and applicability throughout specialised fields.
Mini-InternVL employs a strong imaginative and prescient encoder known as InternViT-300M, distilled from the bigger InternViT-6B mannequin. This imaginative and prescient encoder enhances the mannequin’s representational capability, permitting for efficient cross-domain switch with lowered useful resource necessities. The Mini-InternVL collection contains three mannequin variants: Mini-InternVL-1B, Mini-InternVL-2B, and Mini-InternVL-4B, with parameter counts of 1 billion, 2 billion, and 4 billion, respectively. Every variant is related to pre-trained language fashions like Qwen2-0.5B, InternLM2-1.8B, and Phi-3-Mini, permitting for versatile deployment. Coaching happens in two phases: first, by way of language-image alignment, the place the mannequin is pre-trained on in depth datasets throughout varied duties, guaranteeing sturdy alignment of visible and textual components. Second, the mannequin undergoes visible instruction tuning, which includes coaching on datasets particular to multimodal duties resembling picture captioning, chart interpretation, and visible query answering. The varied vary of duties throughout this multi-stage coaching enhances Mini-InternVL’s adaptability and efficiency in real-world eventualities.

Mini-InternVL demonstrates vital efficiency achievements on varied multimodal benchmarks, reaching as much as 90% of the efficiency of bigger fashions like InternVL2-Llama3-76B with solely 5% of its parameters. Particularly, Mini-InternVL-4B carried out effectively on common multimodal benchmarks, scoring 78.9 on the MMBench and 81.5 on ChartQA, each important benchmarks for vision-language duties. The mannequin additionally carried out competitively on domain-specific duties, matching and even outperforming some proprietary fashions in accuracy and effectivity. As an illustration, within the autonomous driving area, Mini-InternVL-4B achieved an accuracy rating akin to fashions utilizing considerably extra assets. Moreover, Mini-InternVL fashions excelled in medical imaging and distant sensing, demonstrating sturdy generalization capabilities with minimal fine-tuning. The Mini-InternVL-4B mannequin achieved a remaining common rating of 72.8 throughout a number of benchmarks, highlighting its energy as a light-weight, high-performing mannequin able to transferring seamlessly throughout specialised fields with out extreme useful resource calls for.
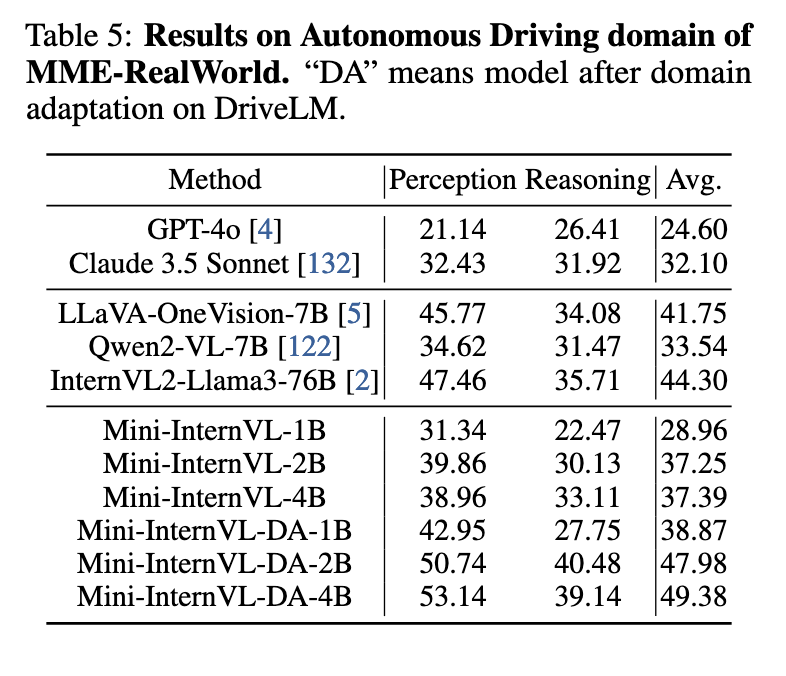
The researchers efficiently addressed the excessive computational boundaries in multimodal mannequin deployment by introducing Mini-InternVL. This mannequin demonstrates that environment friendly structure and coaching strategies can obtain aggressive efficiency ranges whereas considerably decreasing useful resource necessities. By using a unified adaptation framework and a strong imaginative and prescient encoder, Mini-InternVL gives a scalable resolution for specialised functions in resource-limited environments, advancing the sensible applicability of multimodal giant language fashions in specialised fields.
Try the Paper and Mannequin Card on Hugging Face. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An In depth Assortment of Small Language Fashions (SLMs) for Intel PCs
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


