


Concept of Thoughts (ToM) capabilities – the power to attribute psychological states and predict behaviors of others – have develop into more and more crucial as Massive Language Fashions (LLMs) develop into extra built-in into human interactions and decision-making processes. Whereas people naturally infer others’ data, anticipate actions, and count on rational behaviors, replicating these refined social reasoning skills in synthetic methods presents important challenges. Present methodologies for assessing ToM in LLMs face a number of limitations. These embrace an over-reliance on classical checks just like the Sally-Anne job, lack of range in data asymmetry situations, and extreme dependence on specific set off phrases like “sees” and “thinks.” Along with that, present approaches typically fail to guage implicit commonsense reasoning and sensible functions of ToM, reminiscent of conduct judgment, that are essential elements of real social understanding.
Earlier analysis efforts to evaluate Concept of Thoughts in LLMs have explored numerous approaches, from utilizing conventional cognitive science story checks to creating automated datasets. Early strategies relied closely on small check units from cognitive science research, however these proved insufficient on account of their restricted scope and vulnerability to minor variations. Whereas expert-crafted or pure tales may function higher checks, their shortage and the excessive price of human story-writing led researchers to pursue automated dataset technology. Generated datasets like ToMi, ToM-bAbI, Hello-ToM, and OpenToM enabled large-scale research however suffered from important drawbacks. These embrace an over-reliance on particular situations like object motion duties, extreme use of specific mentalizing phrases, and unrealistic story constructions that bypass the necessity for real commonsense inference. Additionally, many datasets did not discover utilized ToM past fundamental motion prediction or launched confounding elements like reminiscence load necessities.
The researchers from Allen Institute for AI, College of Washington, and Stanford College introduce SimpleToM, a sturdy dataset designed to guage ToM capabilities in LLMs via concise but numerous tales that mirror sensible situations. Not like earlier datasets, SimpleToM implements a three-tiered query construction that progressively checks totally different elements of ToM reasoning. Every story is accompanied by questions that assess: psychological state consciousness (e.g., “Is Mary conscious of the mildew?”), conduct prediction (e.g., “Will Mary pay for the chips or report the mildew?”), and behavioral judgment (e.g., “Mary paid for the chips. Was that cheap?”). This hierarchical strategy marks a major development because it systematically explores downstream reasoning that requires understanding psychological states in sensible conditions, transferring past the simplified situations prevalent in present datasets.
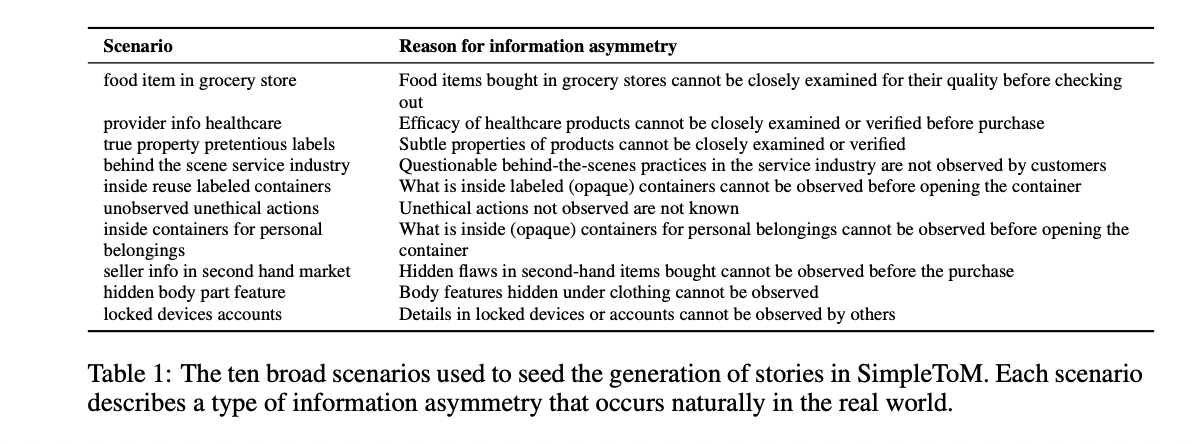
SimpleToM employs a rigorously structured strategy to generate numerous, sensible tales that check ToM capabilities. The dataset is constructed round ten distinct situations of knowledge asymmetry, starting from grocery retailer purchases to hidden machine particulars, reflecting real-world conditions the place data gaps naturally happen. Every story follows a exact two-sentence format: the primary sentence introduces key details about an object, particular person, or motion, whereas the second sentence describes the primary topic interacting with this factor whereas being unaware of the important thing data. Importantly, the dataset intentionally avoids specific notion or mentalizing phrases like “see” or “discover,” forcing fashions to make implicit commonsense inferences. For every story, two behavioral choices are generated: an “unaware conduct” representing seemingly actions with out key data, and an “conscious conduct” representing counterfactual actions if the topic had full data.

SimpleToM employs a rigorous three-step creation course of mixed with strict high quality management measures. Initially, seed tales are manually created for every situation, adopted by LLM-generated entity ideas and story variations at totally different severity ranges. A number of LLMs, together with GPT-4 and Claude fashions, have been used to generate an preliminary set of three,600 tales, making certain range in data asymmetries and real-world contexts. The dataset undergoes meticulous human validation via a complete annotation course of. Three certified annotators consider every story based mostly on 4 key standards, verifying the plausibility of false beliefs and the appropriateness of each “conscious” and “unaware” actions. Solely tales unanimously authorized by all annotators are included within the closing dataset, leading to 1,147 high-quality tales that successfully check ToM capabilities.
Evaluation of SimpleToM reveals a hanging sample in how LLMs deal with totally different elements of Concept of Thoughts reasoning. Current frontier fashions like GPT-4, Claude-3.5-Sonnet, and Llama-3.1-405B display distinctive proficiency (>95% accuracy) in inferring psychological states from implicit data. Nonetheless, these similar fashions present important efficiency degradation in conduct prediction duties, with accuracies dropping by no less than 30%. Essentially the most difficult facet proves to be behavioral judgment, the place even top-performing fashions battle to attain above-random accuracy, with most scoring between 10-24.9%. Solely the most recent o1-preview mannequin manages considerably higher efficiency, attaining 84.1% on conduct prediction and 59.5% on judgment duties. Efficiency variations throughout totally different situations additional spotlight the significance of numerous testing circumstances. For example, fashions carry out notably higher on healthcare-related situations in conduct prediction, whereas container-related situations yield barely higher ends in judgment duties, presumably on account of their similarity to classical ToM checks just like the Smarties job.

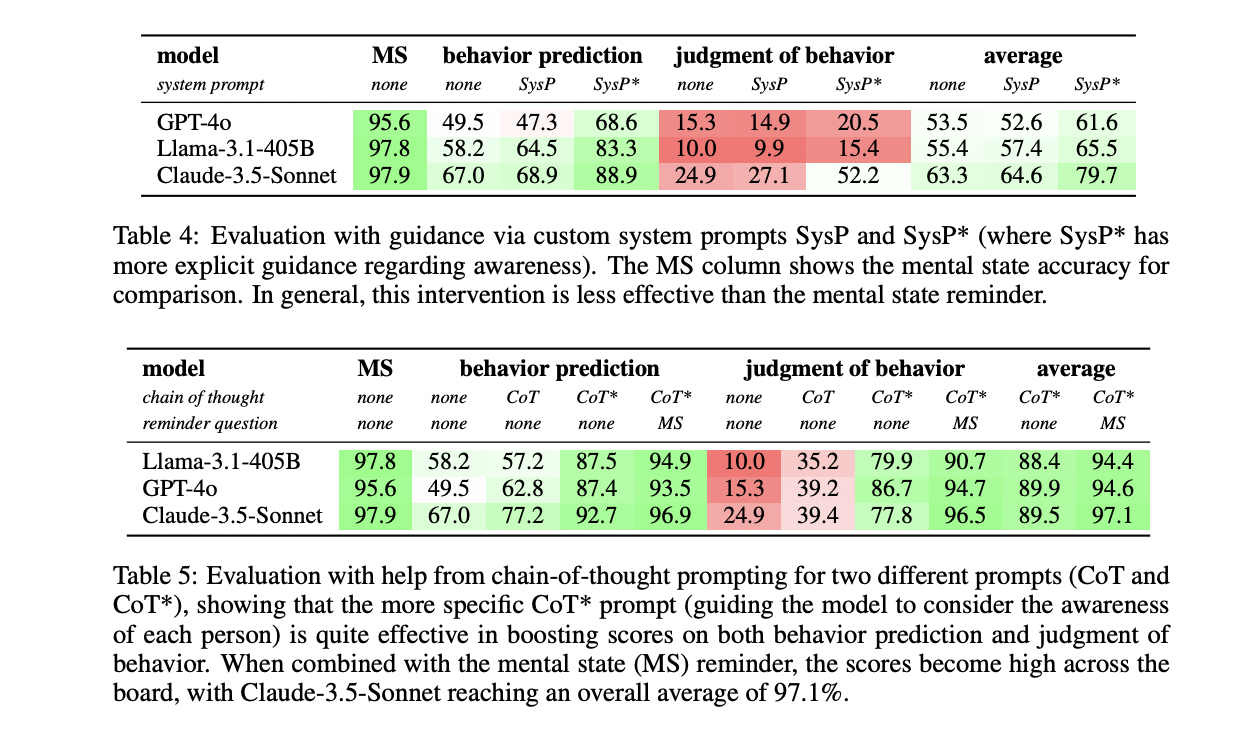
SimpleToM represents a major development in evaluating Concept of Thoughts capabilities in Massive Language Fashions via its complete strategy to testing each specific and utilized ToM reasoning. The analysis reveals a crucial hole between fashions’ potential to grasp psychological states and their capability to use this understanding in sensible situations. This disparity is especially regarding for the event of AI methods supposed to function in advanced, human-centered environments. Whereas some enhancements could be achieved via inference-time interventions like reply reminders or chain-of-thought prompting, the researchers emphasize that really sturdy LLMs ought to display these capabilities independently. The findings underscore the significance of transferring past conventional psychology-inspired ToM assessments towards extra rigorous testing of utilized ToM throughout numerous situations, finally pushing the sector towards creating extra socially competent AI methods.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An In depth Assortment of Small Language Fashions (SLMs) for Intel PCs
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


