

")
Quantization is a necessary approach in machine studying for compressing mannequin knowledge, which allows the environment friendly operation of enormous language fashions (LLMs). As the scale and complexity of those fashions develop, they more and more demand huge storage and reminiscence sources, making their deployment a problem on restricted {hardware}. Quantization immediately addresses these challenges by lowering the reminiscence footprint of fashions, making them accessible for extra various purposes, from complicated pure language processing to high-speed scientific modeling. Particularly, post-training quantization (PTQ) compresses mannequin weights with out requiring retraining, providing a memory-efficient resolution essential for scalable and cost-effective deployments.
A major drawback with LLMs lies of their excessive storage calls for, which limits their sensible software on constrained {hardware} methods. Massive fashions, similar to LLMs exceeding 200GB, can shortly overwhelm reminiscence bandwidth, even in high-capacity GPUs. Present PTQ methods like vector quantization (VQ) depend on codebooks with a number of vectors to signify mannequin knowledge effectively. Nonetheless, conventional VQ strategies have a big downside: they want exponential reminiscence to retailer and entry these codebooks. This dependence limits the scalability of VQ for high-dimensional knowledge, resulting in slower inference speeds and suboptimal efficiency, particularly when real-time response is crucial.
Present quantization strategies, together with QuIP# and AQLM, goal to cut back knowledge illustration by compressing weights into 2-bit or 4-bit fashions by way of VQ methods. By quantizing every vector dimension right into a high-density codebook, VQ can optimize the mannequin’s dimension whereas preserving knowledge integrity. Nonetheless, the codebooks required for high-dimensional vectors usually exceed sensible cache limits, inflicting bottlenecks in reminiscence entry. For instance, the 8-dimensional codebooks AQLM makes use of occupy round 1MB every, making storing them in high-speed caches tough, severely limiting VQ’s general inference velocity and scalability.
Researchers from Cornell College launched the Quantization with Trellis and Incoherence Processing (QTIP) methodology. QTIP presents an alternative choice to VQ by making use of trellis-coded quantization (TCQ), which effectively compresses high-dimensional knowledge utilizing a hardware-efficient “bitshift” trellis construction. QTIP’s design separates codebook dimension from the bitrate, permitting ultra-high-dimensional quantization with out incurring the reminiscence prices typical of VQ. This modern design combines trellis coding with incoherence processing, leading to a scalable and sensible resolution that helps quick, low-memory quantization for LLMs. With QTIP, researchers can obtain state-of-the-art compression whereas minimizing the operational bottlenecks that sometimes come up from codebook dimension limitations.
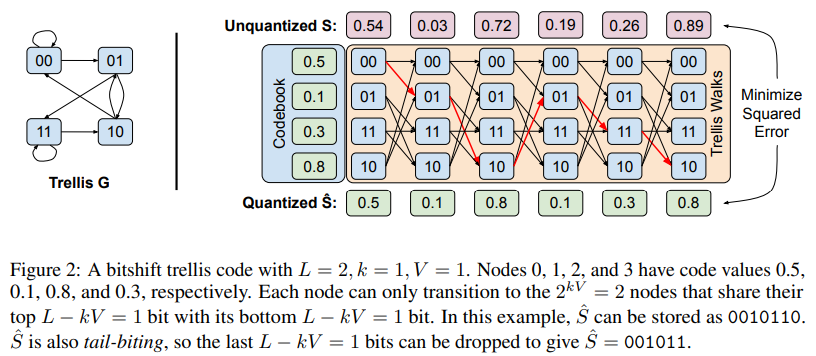
The QTIP construction leverages a bitshift trellis, enabling high-dimensional quantization whereas lowering reminiscence entry calls for. This methodology makes use of a trellis-coded quantizer that eliminates the necessity to retailer a full codebook by producing random Gaussian values immediately in reminiscence, considerably enhancing knowledge effectivity. Additionally, QTIP employs incoherence processing by way of a random Hadamard transformation that ensures weight knowledge resembles Gaussian distributions, a course of that reduces knowledge storage prices and permits for quick inference speeds. By managing quantized knowledge effectively, QTIP achieves glorious efficiency with out requiring giant reminiscence caches, making it adaptable to numerous {hardware} configurations.
Efficiency evaluations of QTIP present that it achieves notable beneficial properties over conventional strategies, delivering larger accuracy with quicker processing occasions throughout totally different {hardware} setups. In checks involving Llama 2 mannequin quantization, QTIP produced higher compression high quality at 2-bit and 3-bit settings, surpassing state-of-the-art outcomes achieved by VQ-based QuIP# and AQLM. On a Wikitext2 analysis, QTIP attained a 5.12 perplexity rating in 4-bit mode, outperforming each QuIP# and AQLM with out further fine-tuning, which is a vital benefit when real-time adaptability is required. Notably, QTIP’s environment friendly code-based strategy requires as few as two {hardware} directions per weight, enabling quicker decoding speeds whereas sustaining mannequin accuracy, even with fashions like Llama 3.1, the place conventional quantization strategies battle.
QTIP’s flexibility in adapting to numerous {hardware} environments additional highlights its potential. Designed for compatibility with cache-limited and parallel-processing units, QTIP leverages the bitshift trellis to course of quantized knowledge effectively on GPUs and different units like ARM CPUs. For instance, QTIP achieves excessive processing speeds on GPUs whereas sustaining a high-dimensional quantization of 256 dimensions, a characteristic that no different PTQ methodology at present helps with out compromising velocity. Its capability to take care of compression high quality at ultra-high dimensions is a notable development, particularly in large-scale deployment wants in LLM inference duties.
QTIP units a brand new commonplace in quantization effectivity for big language fashions. Utilizing trellis-coded quantization paired with incoherence processing, QTIP allows high-dimensional compression with minimal {hardware} necessities, guaranteeing large-scale fashions can carry out inference shortly and exactly. In comparison with VQ-based strategies, QTIP achieves important compression charges with no need giant codebooks or fine-tuning changes, making it extremely adaptable for various kinds of machine studying infrastructure.
Key Takeaways from QTIP Analysis:
- Improved Compression Effectivity: Achieves superior mannequin compression with state-of-the-art quantization high quality, even in high-dimensional settings.
- Minimal Reminiscence Necessities: Requires solely two directions per weight, considerably lowering reminiscence calls for and accelerating processing speeds.
- Enhanced Adaptability: QTIP’s trellis-coded quantization could be effectively processed on GPUs and ARM CPUs, making it versatile for diverse {hardware} environments.
- Increased-High quality Inference: Outperforms QuIP# and AQLM in inference accuracy throughout numerous mannequin sizes, together with the Llama 3 and Llama 2 fashions.
- Extremely-Excessive-Dimensional Quantization: Efficiently operates with 256-dimensional quantization, exceeding the sensible limits of vector quantization.

In conclusion, QTIP presents an modern resolution to giant language fashions’ scalability and reminiscence calls for, providing environment friendly quantization with out sacrificing velocity or accuracy. By addressing the core challenges of conventional quantization strategies, QTIP holds important promise for enhancing the efficiency and accessibility of complicated machine studying fashions throughout a spread of {hardware} configurations.
Try the Paper and Fashions on HuggingFace. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An Intensive Assortment of Small Language Fashions (SLMs) for Intel PCs
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


