


Giant Language Fashions (LLMs) have demonstrated outstanding in-context studying (ICL) capabilities, the place they’ll study duties from demonstrations with out requiring extra coaching. A important problem on this area is knowing and predicting the connection between the variety of demonstrations supplied and the mannequin’s efficiency enchancment, often called the ICL curve. This relationship must be higher understood regardless of its important implications for numerous purposes. Correct prediction of ICL curves holds essential significance for figuring out optimum demonstration portions, anticipating potential alignment failures in many-shot eventualities, and assessing the fine-tuning required to manage undesired behaviours. The flexibility to mannequin these studying curves successfully would improve decision-making in deployment methods and assist mitigate potential dangers related to LLM implementations.
Numerous analysis approaches have tried to decode the underlying mechanisms of in-context studying in Giant Language Fashions, with divergent theories rising. Some research recommend LMs educated on artificial information behave like Bayesian learners, whereas others suggest they observe gradient descent patterns, and a few point out the training algorithm varies primarily based on process complexity, mannequin scale, and coaching progress. Energy legal guidelines have emerged as a predominant framework for modeling LM conduct, together with ICL curves throughout completely different settings. Nevertheless, current analysis has notable limitations. No earlier work has straight modeled the ICL curve primarily based on elementary studying algorithm assumptions. Additionally, post-training modifications have confirmed largely ineffective, with research revealing that such adjustments are sometimes superficial and simply circumvented, significantly regarding since ICL can reinstate behaviors that have been supposedly suppressed by means of fine-tuning.
Researchers suggest a that introduces Bayesian legal guidelines to mannequin and predict in-context studying curves throughout completely different language mannequin eventualities. The examine evaluates these legal guidelines utilizing each artificial information experiments with GPT-2 fashions and real-world testing on customary benchmarks. The strategy extends past easy curve becoming, offering interpretable parameters that seize the prior process distribution, ICL effectivity, and instance possibilities throughout completely different duties. The analysis methodology encompasses two principal experimental phases: first evaluating the Bayesian legal guidelines’ efficiency in opposition to current energy regulation fashions in curve prediction, and second, analyzing how post-training modifications have an effect on ICL conduct in each favored and disfavored duties. The examine culminates in complete testing throughout large-scale fashions starting from 1B to 405B parameters, together with analysis of capabilities, security benchmarks, and a sturdy many-shot jailbreaking dataset.
The structure of the Bayesian scaling legal guidelines for ICL is constructed upon elementary assumptions about how language fashions course of and study from in-context examples. The framework begins by treating ICL as a Bayesian studying course of, making use of Bayes’ theorem iteratively to mannequin how every new in-context instance updates the duty prior. A key innovation within the structure is the introduction of parameter discount strategies to forestall overfitting. This consists of two distinct approaches to parameter tying, sampling-wise and scoring-wise, which assist keep mannequin effectivity whereas scaling linearly with the variety of distributions. The structure incorporates an ICL effectivity coefficient ‘Okay’ that accounts for the token-by-token processing nature of LLMs and variations in instance informativeness, successfully modulating the energy of Bayesian updates primarily based on instance size and complexity.
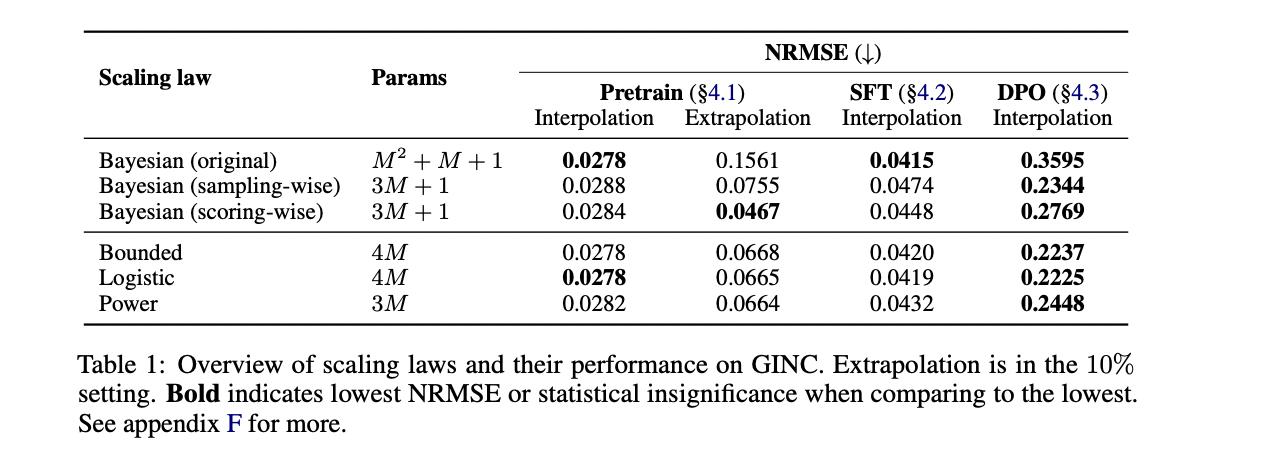
The experimental outcomes show superior efficiency of the Bayesian scaling legal guidelines in comparison with current approaches. In interpolation assessments, the unique Bayesian scaling regulation achieved considerably decrease Normalized Root Imply Sq. Error (NRMSE) throughout mannequin scales and trajectory lengths, solely matched by a powerful logistic baseline. The scoring-wise Bayesian regulation significantly excelled in extrapolation duties, exhibiting the most effective efficiency when predicting the remaining 90% of ICL curves utilizing solely the primary 10% of information factors. Past numerical superiority, the Bayesian legal guidelines provide interpretable parameters that present significant insights into mannequin conduct. The outcomes reveal that prior distributions align with uniform pretraining distributions, and ICL effectivity correlates positively with each mannequin depth and instance size, indicating that bigger fashions obtain sooner in-context studying, particularly with extra informative examples.
Evaluating Llama 3.1 8B Base and Instruct variations revealed essential insights in regards to the effectiveness of instruction-tuning. Outcomes present that whereas instruction-tuning efficiently reduces the prior chance of unsafe behaviors throughout numerous analysis metrics (together with harmbench and persona evaluations), it fails to forestall many-shot jailbreaking successfully. The Bayesian scaling regulation demonstrates that posterior possibilities are ultimately saturated, whatever the diminished prior possibilities achieved by means of instruction-tuning. This means that instruction-tuning primarily modifies process priors quite than basically altering the mannequin’s underlying process information, presumably as a result of comparatively restricted computational assets allotted to instruction-tuning in comparison with pretraining.
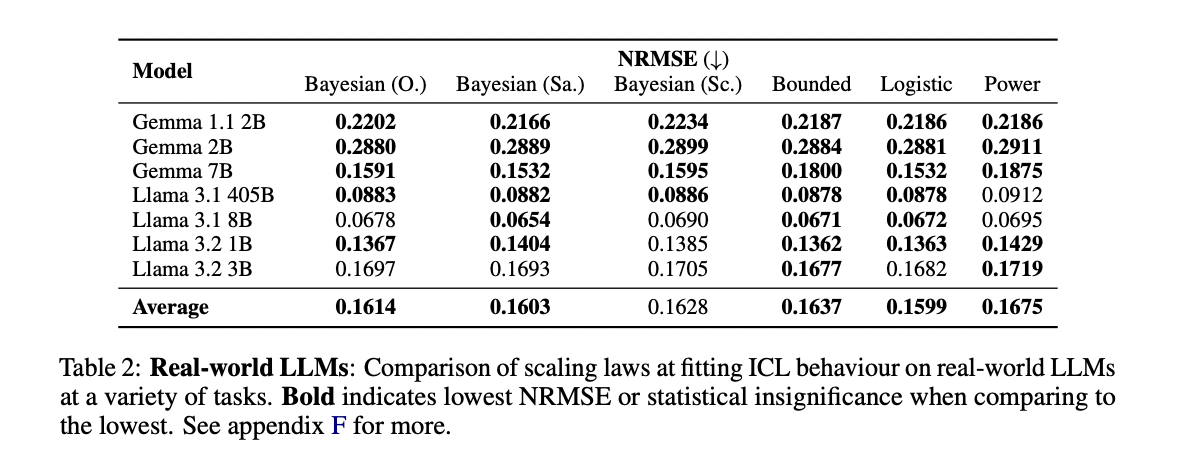
The analysis efficiently bridges two elementary questions on in-context studying by creating and validating Bayesian scaling legal guidelines. These legal guidelines show outstanding effectiveness in modeling ICL conduct throughout each small-scale LMs educated on artificial information and large-scale fashions educated on pure language. The important thing contribution lies within the interpretability of the Bayesian formulation, which supplies clear insights into priors, studying effectivity, and task-conditional possibilities. This framework has confirmed beneficial for understanding scale-dependent ICL capabilities, analyzing the impression of fine-tuning on information retention, and evaluating base fashions with their instruction-tuned counterparts. The success of this strategy means that continued investigation of scaling legal guidelines might yield additional essential insights into the character and conduct of in-context studying, paving the way in which for more practical and controllable language fashions.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Group Members
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


