


Contrastive picture and textual content fashions face vital challenges in optimizing retrieval accuracy regardless of their essential function in large-scale text-to-image and image-to-text retrieval methods. Whereas these fashions successfully be taught joint embeddings via contrastive loss features to align matching text-image pairs and separate non-matching pairs, they primarily optimize pretraining goals like InfoNCE quite than downstream retrieval efficiency. This elementary limitation results in suboptimal embeddings for sensible retrieval duties. Present methodologies wrestle with points just like the hubness drawback, the place sure retrieval candidates dominate as nearest neighbors for a number of queries in high-dimensional embedding areas, leading to incorrect matches. Additionally, current options usually require substantial computational sources, extra coaching throughout domains, or exterior database integration, making them impractical for limited-compute environments or black-box embedding fashions.
Researchers from Massachusetts Institute of Expertise and Stanford College current Nearest Neighbor Normalization (NNN), which emerges as a strong training-free method to boost contrastive retrieval efficiency. This revolutionary technique addresses the constraints of earlier approaches by introducing a computationally environment friendly answer with sublinear time complexity relative to reference database dimension. At its core, NNN implements a correction mechanism that targets embeddings receiving disproportionate retrieval scores by normalizing candidate scores utilizing solely the ok nearest question embeddings from a reference dataset. This focused method not solely surpasses the efficiency of current strategies like QBNorm and DBNorm but in addition maintains minimal inference overhead. The strategy demonstrates exceptional versatility by constantly enhancing retrieval accuracy throughout numerous fashions and datasets whereas concurrently lowering dangerous biases, resembling gender bias, making it a big development in contrastive retrieval methods.
The Nearest Neighbor Normalization technique introduces a complicated method to handle the hubness drawback in contrastive text-to-image retrieval methods. The strategy calculates a match rating s(q, r) between a question q and database retrieval candidate r utilizing cosine similarity between picture and textual content embeddings. To counteract bias in the direction of hub pictures that present excessive cosine similarity with a number of question captions, The NNN technique implements a bias correction mechanism. This bias b(r) for every retrieval candidate is computed as α instances the imply of the ok highest similarity scores from a reference question dataset D. The ultimate debiased retrieval rating is obtained by subtracting this estimated bias from the unique rating: sD(q, r) = s(q, r) – b(r). The strategy’s effectivity stems from its means to compute bias scores offline and cache them whereas sustaining sublinear time complexity throughout retrieval operations via vector retrieval strategies.
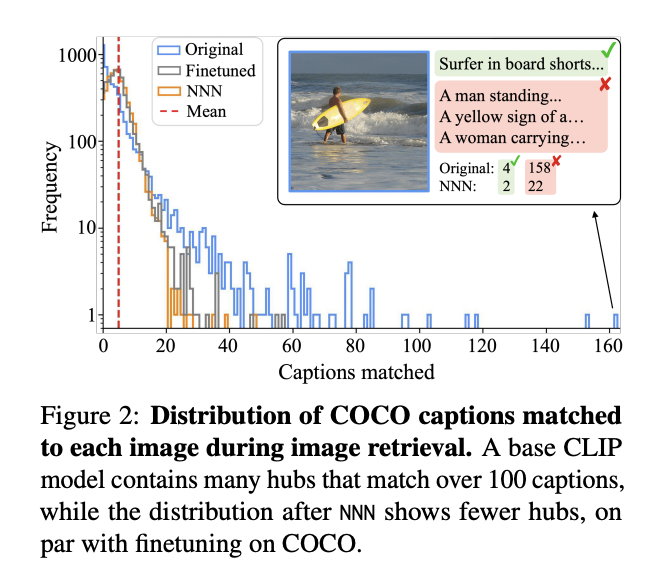
The analysis of NNN demonstrates spectacular efficiency enhancements throughout a number of contrastive multimodal fashions together with CLIP, BLIP, ALBEF, SigLIP, and BEiT. The strategy reveals constant positive factors in each text-to-image and image-to-text retrieval duties, outperforming current approaches whereas requiring considerably much less computational sources. As well as, whereas DBNorm’s hyperparameter optimization calls for 100 instances extra compute, NNN achieves superior outcomes with minimal computational overhead. The strategy’s robustness is obvious via its constant efficiency with each in-distribution and out-of-distribution queries, sustaining effectiveness even with various sizes of reference databases. In addressing gender bias, NNN considerably diminished bias in occupation-related picture retrieval from 0.348 to 0.072 (n=6) and from 0.270 to 0.078 (n=10), whereas concurrently enhancing common precision from 56.5% to 69.6% for Retrieval@1 and from 49.6% to 56.5% for Retrieval@5, demonstrating its functionality to boost each equity and accuracy.
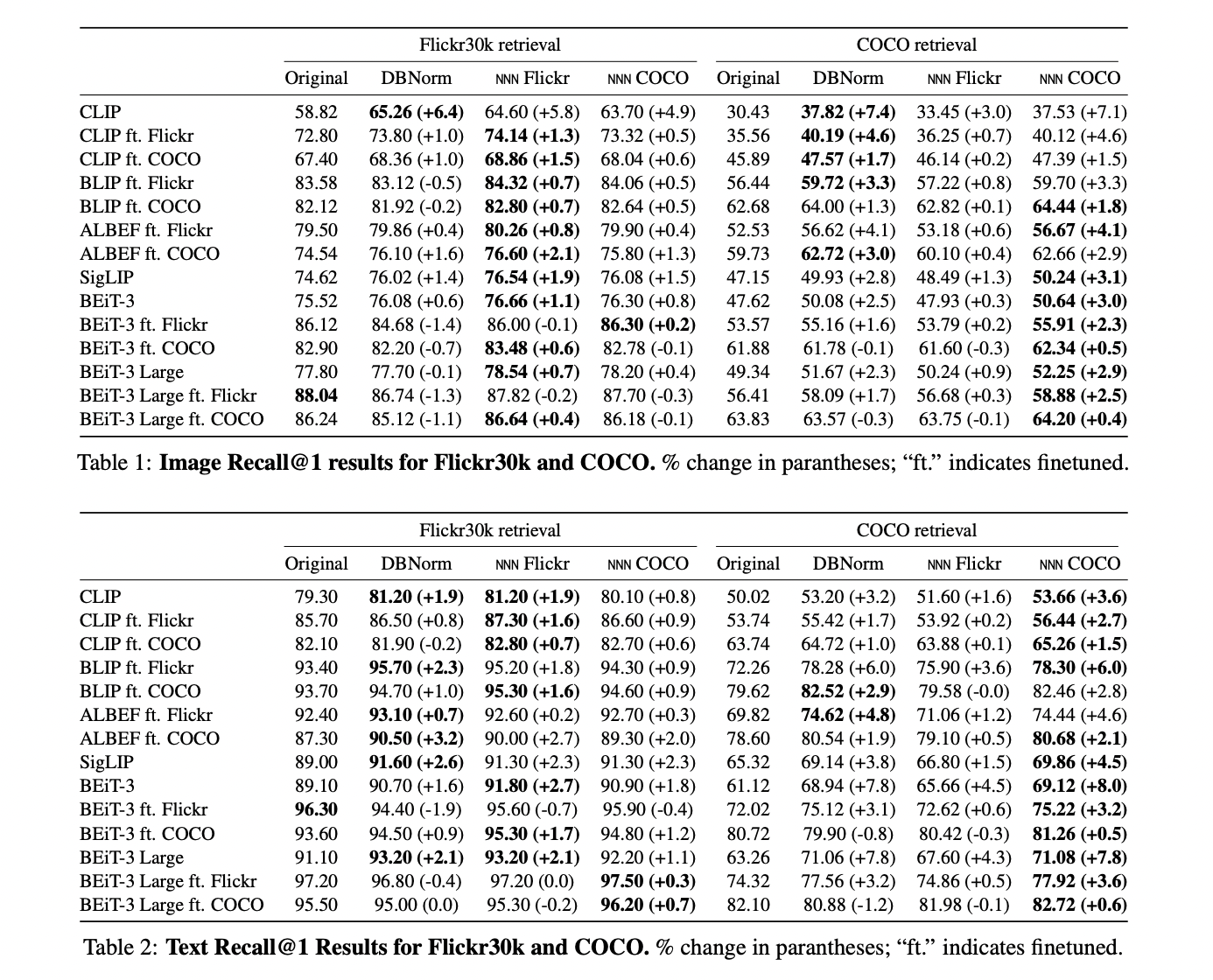

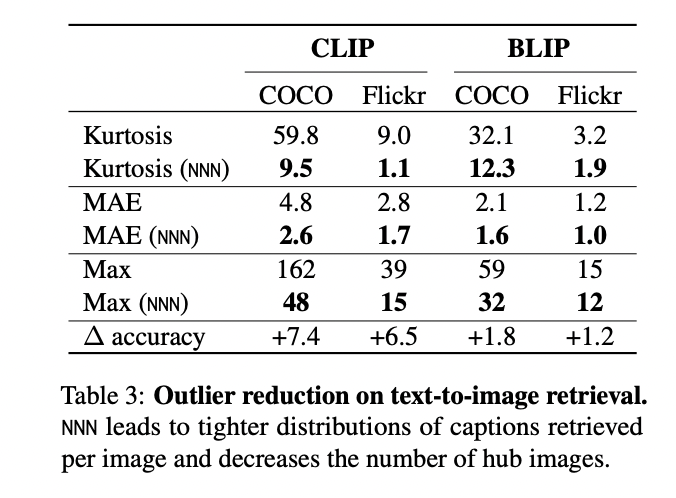
Nearest Neighbor Normalization represents a big development in contrastive multimodal retrieval methods. The strategy’s revolutionary method of utilizing k-nearest neighbors for bias correction scores demonstrates superior effectivity whereas sustaining improved accuracy in comparison with current test-time inference strategies. NNN’s versatility is obvious in its profitable software with numerous reference datasets and its effectiveness in lowering gender bias, marking it as a sensible and highly effective answer for enhancing multimodal retrieval methods.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Neighborhood Members
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


