


Massive Language Fashions (LLMs) have demonstrated exceptional capabilities in varied pure language processing duties. Nevertheless, they face a major problem: hallucinations, the place the fashions generate responses that aren’t grounded within the supply materials. This problem undermines the reliability of LLMs and makes hallucination detection a crucial space of analysis. Whereas standard strategies like classification and rating fashions have been efficient, they typically lack interpretability, which is essential for person belief and mitigation methods. The widespread adoption of LLMs has led researchers to discover utilizing these fashions themselves for hallucination detection. However, this method introduces new challenges, notably concerning latency, as a result of huge dimension of LLMs and the computational overhead required to course of lengthy supply texts. This creates a major impediment for real-time functions that require fast response occasions.
Researchers from Microsoft Accountable AI current a strong workflow to deal with the challenges of hallucination detection in LLMs. This method goals to stability latency and interpretability by combining a small classification mannequin, particularly a small language mannequin (SLM), with a downstream LLM module known as a “constrained reasoner.” The SLM performs preliminary hallucination detection, whereas the LLM module explains the detected hallucinations. This technique makes use of the comparatively rare incidence of hallucinations in sensible use, making the typical time value of utilizing LLMs for reasoning on hallucinated texts manageable. Moreover, the method capitalizes on LLMs’ pre-existing reasoning and clarification capabilities, eliminating the necessity for in depth domain-specific information and the numerous computational value related to fine-tuning.
This framework mitigates a possible problem in combining SLMs and LLMs: inconsistency between the SLM’s selections and the LLM’s explanations. This downside is especially related in hallucination detection, the place alignment between detection and clarification is essential. The examine focuses on resolving this problem inside the two-stage hallucination detection framework. Moreover, the researchers analyze LLM reasonings about SLM selections and floor fact labels, exploring the potential of LLMs as suggestions mechanisms for enhancing detection processes. The examine makes two main contributions: introducing a constrained reasoner for hallucination detection that balances latency and interpretability and offering a complete evaluation of upstream-downstream consistency, together with sensible options to reinforce alignment between detection and clarification. The effectiveness of this method is demonstrated throughout a number of open-source datasets.
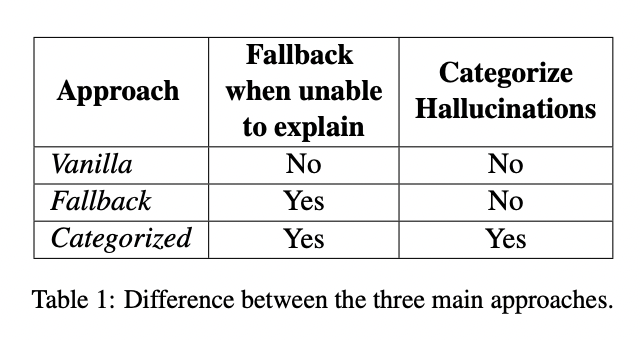
The proposed framework addresses the twin challenges of latency and interpretability in hallucination detection for LLMs. It consists of two primary elements: an SLM for preliminary detection and a constrained reasoner based mostly on an LLM for clarification.
The SLM serves as a light-weight, environment friendly classifier educated to establish potential hallucinations in textual content. This preliminary step permits for fast screening of enter, considerably decreasing the computational load on the system. When the SLM flags a chunk of textual content as doubtlessly containing a hallucination, it triggers the second stage of the method.
The constrained reasoner, powered by an LLM, then takes over to offer an in depth clarification of the detected hallucination. This element takes benefit of the LLM’s superior reasoning capabilities to research the flagged textual content in context, providing insights into why it was recognized as a hallucination. The reasoner is “constrained” within the sense that it focuses solely on explaining the SLM’s resolution, quite than performing an open-ended evaluation.
To sort out potential inconsistencies between the SLM’s selections and the LLM’s explanations, the framework incorporates mechanisms to reinforce alignment. This consists of cautious immediate engineering for the LLM and potential suggestions loops the place the LLM’s explanations can be utilized to refine the SLM’s detection standards over time.
The experimental setup of the proposed hallucination detection framework is designed to review the consistency of reasoning and discover efficient approaches to filter inconsistencies. The researchers use GPT4-turbo because the constrained reasoner (R) to elucidate hallucination determinations with particular temperature and top-p settings. The experiments are carried out throughout 4 datasets: NHNET, FEVER, HaluQA, and HaluSum, with sampling utilized to handle dataset sizes and useful resource limitations.
To simulate an imperfect SLM classifier, the researchers pattern each hallucinated and non-hallucinated responses from the datasets, assuming the upstream label as a hallucination. This creates a mixture of true optimistic and false optimistic instances for evaluation.
The methodology focuses on three main approaches:
1. Vanilla: A baseline method the place R merely explains why the textual content was detected as a hallucination with out addressing inconsistencies.
2. Fallback: Introduces an “UNKNOWN” flag to point when R can’t present an acceptable clarification, signaling potential inconsistencies.
3. Categorized: Refines the flagging mechanism by incorporating granular hallucination classes, together with a particular class (hallu12) to sign inconsistencies the place the textual content shouldn’t be a hallucination.
These approaches are in comparison with assess their effectiveness in dealing with inconsistencies between SLM selections and LLM explanations to enhance the general reliability and interpretability of the hallucination detection framework.
The experimental outcomes reveal the effectiveness of the proposed hallucination detection framework, notably the Categorized method. In figuring out inconsistencies between SLM selections and LLM explanations, the Categorized method achieved near-perfect efficiency throughout all datasets, with precision, recall, and F1 scores persistently above 0.998 on many datasets.
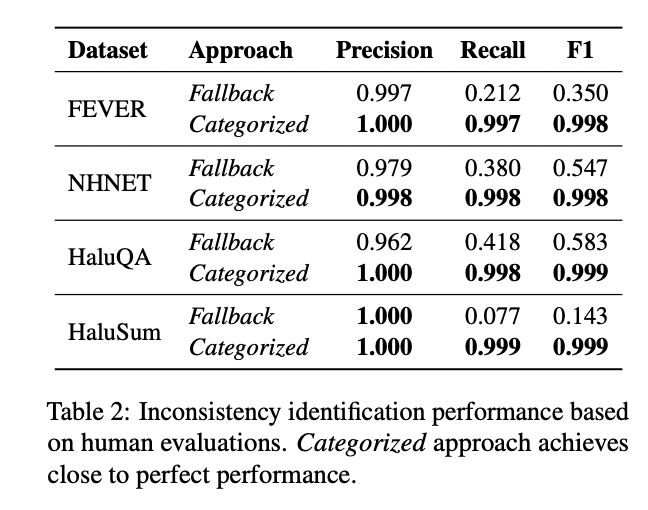
In comparison with the Fallback method, which confirmed excessive precision however poor recall, the Categorized technique excelled in each metrics. This superior efficiency translated into more practical inconsistency filtering. Whereas the Vanilla method exhibited excessive inconsistency charges, and the Fallback technique confirmed restricted enchancment, the Categorized method dramatically decreased inconsistencies to as little as 0.1-1% throughout all datasets after filtering.
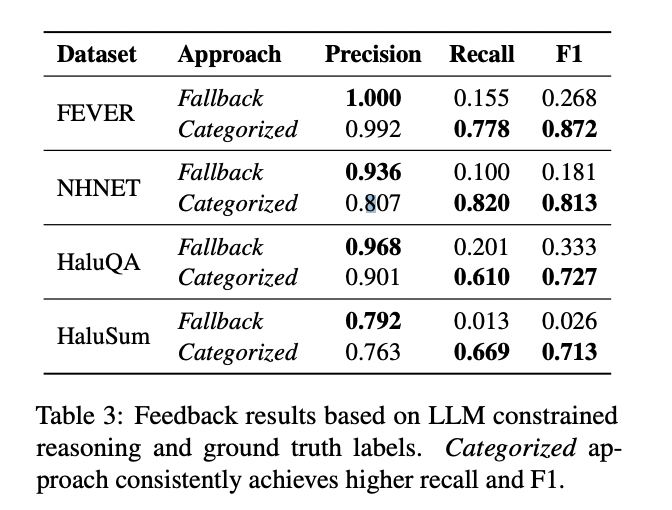
The Categorized method additionally demonstrated sturdy potential as a suggestions mechanism for enhancing the upstream SLM. It persistently outperformed the Fallback technique in figuring out false positives, attaining a macro-average F1 rating of 0.781. This means its functionality to precisely assess the SLM’s selections in opposition to floor fact, making it a promising instrument for refining the detection course of.
These outcomes spotlight the Categorized method’s skill to reinforce consistency between detection and clarification within the hallucination detection framework, whereas additionally offering beneficial suggestions for system enchancment.
This examine presents a sensible framework for environment friendly and interpretable hallucination detection by integrating an SLM for detection with an LLM for constrained reasoning. The proposed categorized prompting and filtering technique offered by the researchers successfully aligns LLM explanations with SLM selections, demonstrating empirical success throughout 4 hallucination and factual consistency datasets. Additionally, this method holds potential as a suggestions mechanism for refining SLMs, paving the best way for extra sturdy and adaptive techniques. The findings supply broader implications for enhancing classification techniques and enhancing SLMs via LLM-driven constrained interpretation.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Here’s a extremely really useful webinar from our sponsor: ‘Constructing Performant AI Purposes with NVIDIA NIMs and Haystack’
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


