


Language fashions have demonstrated exceptional capabilities in processing various information varieties, together with multilingual textual content, code, mathematical expressions, photographs, and audio. Nonetheless, a basic query arises: how do these fashions successfully deal with such heterogeneous inputs utilizing a single parameter set? Whereas one strategy suggests growing specialised subspaces for every information sort, this overlooks the inherent semantic connections that exist throughout seemingly totally different types of information. As an illustration, equal sentences in several languages, image-caption pairs, or code snippets with pure language descriptions all share conceptual similarities. Very like the human mind’s transmodal semantic hub that integrates info from numerous sensory inputs, there exists a possibility to develop fashions that may mission totally different information varieties right into a unified illustration area, carry out computations, and generate acceptable outputs. The problem lies in creating an structure that may successfully make the most of these structural commonalities whereas sustaining the distinctive traits of every information sort.
Earlier makes an attempt to handle cross-data-type illustration have primarily centered on aligning individually skilled mono-data-type fashions by way of transformation methods. Analysis has demonstrated success in aligning phrase embeddings throughout totally different languages by way of mapping strategies, and comparable approaches have been utilized to attach visible and textual representations from distinct fashions. Some research have explored minimal fine-tuning of language-only fashions to deal with multimodal duties. Further analysis has investigated illustration evolution by way of transformer layers, analyzing its impression on reasoning, factuality, and information processing. Layer pruning and early exiting research have additionally supplied insights into illustration dynamics. Nonetheless, these approaches usually require separate fashions or transformations between representations, limiting their effectivity and doubtlessly lacking deeper connections between totally different information varieties. Additionally, the necessity for specific alignment mechanisms provides complexity and computational overhead to the methods.
Researchers from MIT, the College of Southern California, and the Allen Institute for AI suggest a strong strategy to understanding how language fashions course of a number of information varieties by way of a shared illustration area. The methodology facilities on investigating the existence of a “semantic hub” – a unified illustration area scaffolded by the mannequin’s dominant information sort, usually English. This strategy examines three key features: first, analyzing how semantically comparable inputs from totally different information varieties (languages, arithmetic expressions, code, and multimodal inputs) cluster collectively in intermediate mannequin layers; second, investigating how these hidden representations may be interpreted by way of the mannequin’s dominant language utilizing the logit lens method; and third, conducting intervention experiments to reveal that this shared illustration area actively influences mannequin conduct slightly than being a passive byproduct of coaching. In contrast to earlier approaches specializing in aligning individually skilled fashions, this system examines how a single mannequin naturally develops and makes use of a unified illustration area with out requiring specific alignment mechanisms.
The semantic hub speculation testing framework employs a classy mathematical structure constructed on domain-specific capabilities and illustration areas. For any information sort z within the mannequin’s supported set Z, the framework defines a site Xz (reminiscent of Chinese language tokens for language or RGB values for photographs) and two essential capabilities: Mz, which maps enter sequences right into a semantic illustration area Sz, and Vz, which transforms these representations again into the unique information sort format. The testing methodology evaluates two basic equations: first, evaluating the similarity between semantically associated inputs from totally different information varieties utilizing cosine similarity measures of hidden states, and second, analyzing the connection between these representations and the mannequin’s dominant language by way of the logit lens method. This system analyzes hidden states at intermediate layers by making use of the output token embedding matrix, producing likelihood distributions that reveal the mannequin’s inside processing. The structure has been rigorously examined throughout a number of information varieties, together with numerous languages, arithmetic expressions, code, semantic constructions, and multimodal inputs, persistently demonstrating the existence of a unified semantic illustration area.

The analysis presents compelling outcomes from intervention experiments that validate the causal impression of the semantic hub on mannequin conduct. In multilingual experiments utilizing the Activation Addition method, interventions within the English illustration area successfully steered mannequin outputs even when processing Spanish and Chinese language texts. Testing on 1000 prefixes from each the InterTASS dataset (Spanish) and the multilingual Amazon opinions corpus (Chinese language), the research in contrast mannequin outputs with and with out interventions utilizing language-specific sentiment set off phrases (Good/Dangerous, Bueno/Malo, 好/坏). These experiments demonstrated that English-based interventions achieved sentiment steering results corresponding to interventions utilizing the textual content’s native language whereas sustaining era fluency and relevance. The researchers evaluated the standard of generated textual content utilizing three key metrics: sentiment alignment with the supposed course, fluency of the generated textual content, and relevance to the unique prefix. The outcomes strongly help the speculation that the semantic hub is just not merely a byproduct of coaching however actively influences the mannequin’s cross-lingual processing capabilities.
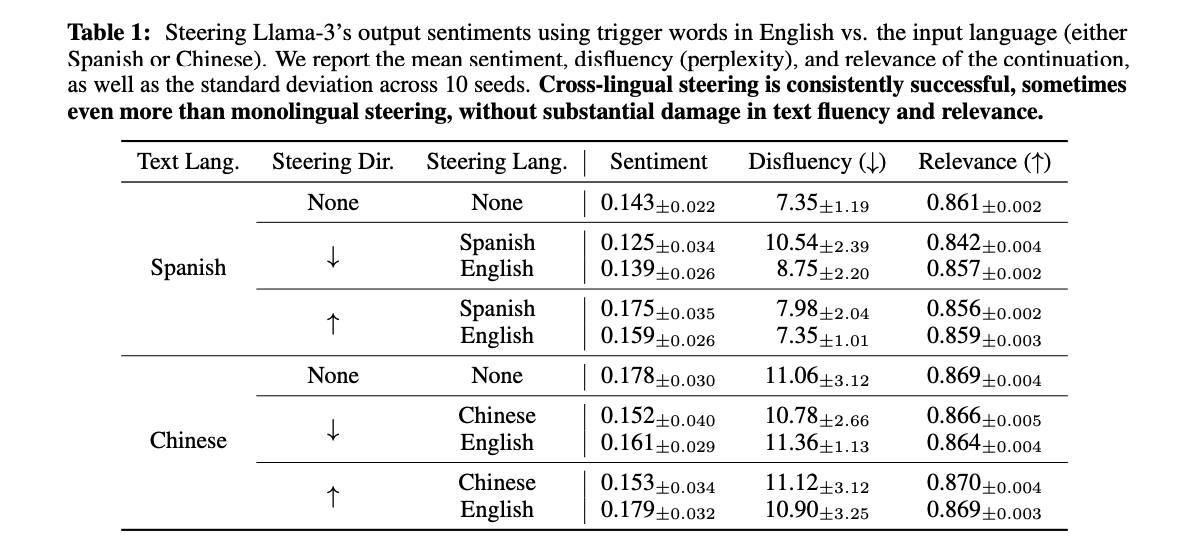
The analysis advances the understanding of how language fashions course of various information varieties by way of a unified semantic hub. The research conclusively demonstrates that fashions naturally develop a shared illustration area the place semantically associated inputs cluster collectively, no matter their unique modality. This discovery, validated throughout a number of fashions and information varieties, opens new prospects for mannequin interpretation and management by way of focused interventions within the dominant language area.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[AI Magazine/Report] Learn Our Newest Report on ‘SMALL LANGUAGE MODELS‘
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.

