


Contrastive studying has turn into important for constructing representations from paired information like image-text mixtures in AI. It has proven nice utility in transferring discovered data to downstream duties, particularly in domains with complicated information interdependencies, reminiscent of robotics and healthcare. In robotics, for example, brokers collect information from visible, tactile, and proprioceptive sensors, whereas healthcare professionals combine medical photos, biosignals, and genomic information. Every area calls for a mannequin able to concurrently processing a number of information sorts. But, current fashions in contrastive studying are predominantly restricted to 2 modalities, limiting the illustration high quality and usefulness throughout complicated, multimodal eventualities.
A significant problem lies within the limitations of two-modality fashions, reminiscent of CLIP, that are structured to seize solely pairwise information dependencies. This setup restricts the mannequin from understanding joint conditional dependencies throughout greater than two information sorts, resulting in a big data hole. When analyzing a number of modalities—like photos, audio, and textual content—the dependencies between every pair don’t mirror the total complexity; for example, if three forms of information exist, a pairwise mannequin may perceive the connection between image-text and text-audio however miss the broader relationships, notably when one information kind relies upon conditionally on one other. This incapacity to characterize cross-modal relationships past pairs of knowledge sorts stays a barrier for healthcare and multimedia functions.
Traditionally, researchers have prolonged pairwise contrastive fashions to a number of modalities by making use of targets like CLIP to pairs of modalities. Whereas this two-at-a-time strategy introduces a level of multimodal compatibility, it’s restricted by the necessity for specialised architectures or extra coaching steps for every modality pairing, complicating generalization. Various fashions that deal with a number of information sorts require complicated buildings and complex tuning, which in the end restricts their applicability. Whereas efficient in restricted functions, these strategies demand guide intervention to outline appropriate modality pairings, leaving room for approaches that seize all modality interactions inside a single goal perform.
Researchers from New York College current Symile, an revolutionary contrastive studying mannequin that surpasses these limitations by capturing higher-order dependencies throughout a number of information modalities with out complicated changes. Not like pairwise strategies, Symile leverages a complete correlation goal that accommodates any variety of modalities, making a unified illustration with out counting on complicated architectural modifications. The researchers structured Symile to flexibly deal with various modalities, focusing on a generalization of mutual data that estimates dependencies throughout information sorts. By deriving a decrease certain on whole correlation, Symile’s mannequin goal captures modality-specific representations that retain crucial joint data, enabling it to carry out effectively in eventualities the place information from a number of modalities is incomplete or lacking.
Symile’s methodology entails a novel contrastive goal that makes use of the multilinear inside product (MIP), a scoring perform that generalizes dot merchandise to account for 3 or extra vectors, to measure similarity between a number of information sorts. Symile maximizes optimistic tuple scores and minimizes adverse ones inside a batch by this perform. The mannequin then averages these losses throughout all modalities. This permits Symile to seize extra than simply pairwise data, including a 3rd layer of “conditional data” among the many information sorts. The researchers optimized the mannequin utilizing a brand new adverse sampling strategy, creating extra numerous adverse samples inside every batch simplifying computations for broader datasets.
Symile’s efficiency on multimodal information duties highlights its effectiveness over conventional pairwise fashions. Testing concerned varied experiments, together with cross-modal classification and retrieval of numerous datasets. In a single experiment utilizing an artificial dataset with managed variables, Symile achieved a near-perfect accuracy of 1.00 when deciphering information with mutual conditional data throughout three modalities. On the similar time, CLIP reached solely 0.50, which is successfully the speed of random probability. Additional experiments on a big multilingual dataset, Symile-M3, demonstrated Symile’s accuracy of 93.9% in predicting picture content material based mostly on textual content and audio throughout two languages, whereas CLIP achieved simply 47.3%. This hole widens because the dataset complexity will increase; Symile maintained 88.2% accuracy when utilizing ten languages, whereas CLIP’s dropped to 9.4%. On a medical dataset incorporating chest X-rays, electrocardiograms, and lab information, Symile achieved 43.5% accuracy in predicting appropriate matches, outperforming CLIP’s 38.7%.
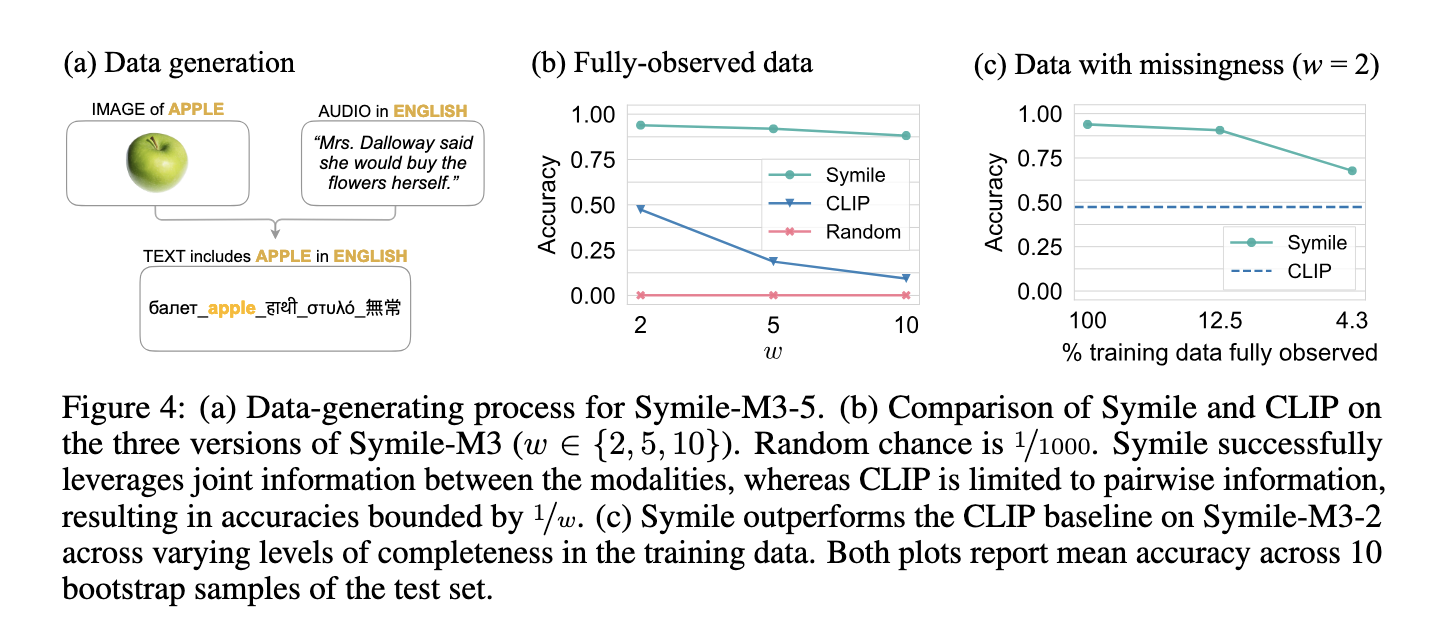
Via its skill to seize joint data amongst modalities, Symile’s strategy permits it to carry out effectively even when some information sorts are lacking. For instance, in a variant of Symile-M3 the place every modality was randomly omitted with a likelihood of fifty%, Symile maintained excessive accuracy at 90.6%, considerably outperforming CLIP below the identical constraints. The Symile mannequin dealt with lacking information by adapting the target to take care of accuracy by out-of-support samples, a function crucial for real-world functions like healthcare the place all information might not all the time be accessible.
This analysis addresses a significant hole in contrastive studying by enabling a mannequin to course of a number of information sorts concurrently with an easy, architecture-independent goal. Symile’s whole correlation strategy, by capturing greater than pairwise data, represents a considerable development over two-modality fashions and delivers superior efficiency, particularly in complicated, data-dense domains like healthcare and multilingual duties. By bettering illustration high quality and flexibility, Symile is well-positioned as a beneficial instrument for multimodal integration, providing a versatile answer that aligns with real-world information’s complicated, high-dimensional nature.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Upcoming Live LinkedIn event] ‘One Platform, Multimodal Potentialities,’ the place Encord CEO Eric Landau and Head of Product Engineering, Justin Sharps will speak how they’re reinventing information growth course of to assist groups construct game-changing multimodal AI fashions, quick‘
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


