

: A Machine Studying Technique that Computes the Cross-Entropy Loss with out Materializing the Logits for all Tokens into World Reminiscence")
Developments in giant language fashions (LLMs) have revolutionized pure language processing, with functions spanning textual content era, translation, and summarization. These fashions depend on giant quantities of knowledge, giant parameter counts, and expansive vocabularies, necessitating refined strategies to handle computational and reminiscence necessities. A vital part of LLM coaching is the cross-entropy loss computation, which, whereas central to mannequin accuracy, presents vital reminiscence challenges as a result of dimension and complexity of the vocabulary.
The reminiscence necessities of the cross-entropy loss layer constrict coaching giant language fashions, particularly as vocabulary sizes attain a whole bunch of 1000’s of tokens. The problem turns into acute in fashions like Gemma 2 (2B), the place the cross-entropy loss computation alone can eat as much as 24 GB of reminiscence, accounting for as much as 90% of the reminiscence footprint throughout coaching. These limitations limit batch sizes and pressure trade-offs between mannequin efficiency and computational feasibility, posing a major bottleneck for scalability.
Earlier strategies aimed toward decreasing reminiscence utilization, reminiscent of FlashAttention and hierarchical vocabularies, have addressed particular elements like self-attention however fall quick in assuaging the burden of the cross-entropy layer. Chunking strategies scale back reminiscence necessities however introduce latency trade-offs, limiting their sensible use. Additionally, these approaches want to totally exploit the sparsity of gradients or leverage {hardware} optimizations, leaving room for enchancment.
Researchers at Apple launched the Reduce Cross-Entropy (CCE) technique, a novel method designed to beat the reminiscence challenges related to giant vocabulary fashions. In contrast to standard strategies that compute and retailer all logits for tokens in reminiscence, CCE dynamically calculates solely the mandatory logits and performs log-sum-exp reductions in on-chip reminiscence. This method eliminates the necessity to materialize giant matrices in GPU reminiscence, considerably decreasing the reminiscence footprint. For example, within the Gemma 2 mannequin, the reminiscence utilization for loss computation dropped from 24 GB to simply 1 MB, with complete classifier head reminiscence consumption decreased from 28 GB to 1 GB.
The core of CCE lies in its environment friendly computation technique, which employs customized CUDA kernels to course of embeddings and carry out reductions. By calculating logits on the fly and avoiding intermediate reminiscence storage, the strategy capitalizes on shared GPU reminiscence, which is quicker and extra environment friendly than conventional international reminiscence utilization. Additionally, gradient filtering selectively skips computations that contribute negligibly to the gradient, leveraging the inherent sparsity of the softmax matrix. Vocabulary sorting optimizes processing by grouping tokens with vital contributions, minimizing wasted computation. Collectively, these improvements allow a memory-efficient, low-latency loss computation mechanism.
The efficiency features from CCE are outstanding. Reminiscence reductions enabled a 10-fold improve in batch dimension for smaller fashions like GPT-2 and a 1.5-fold improve for bigger fashions like Llama 2 (13B). Coaching throughput remained unaffected, and experimental outcomes demonstrated secure convergence, matching the efficiency of conventional strategies. For a batch of 8,192 tokens with a vocabulary dimension 256,000, CCE achieved a peak reminiscence utilization of simply 1 MB in comparison with 28 GB in baseline strategies. Coaching stability exams on fashions reminiscent of Llama 3 (8B) and Phi 3.5 Mini confirmed the reliability of CCE, with indistinguishable loss curves in comparison with current approaches.
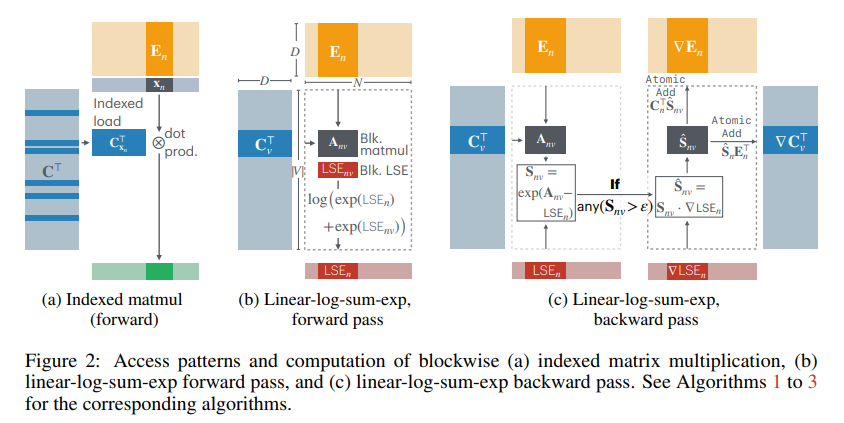
This analysis highlights a number of key takeaways:
- Important Reminiscence Discount: CCE reduces reminiscence utilization for cross-entropy loss computation to negligible ranges, as little as 1 MB for large-scale fashions like Gemma 2 (2B).
- Improved Scalability: By enabling bigger batch sizes, the strategy helps extra environment friendly utilization of computational assets, which is essential for coaching intensive fashions.
- Effectivity Features: Customized CUDA kernels and gradient filtering be certain that the discount in reminiscence footprint doesn’t compromise coaching velocity or mannequin convergence.
- Sensible Applicability: The tactic is adaptable to numerous architectures and situations, with potential functions extending to picture classification and contrastive studying.
- Future Potential: CCE’s skill to deal with giant vocabularies with minimal reminiscence impression might facilitate coaching much more intensive fashions with improved pipeline balancing.
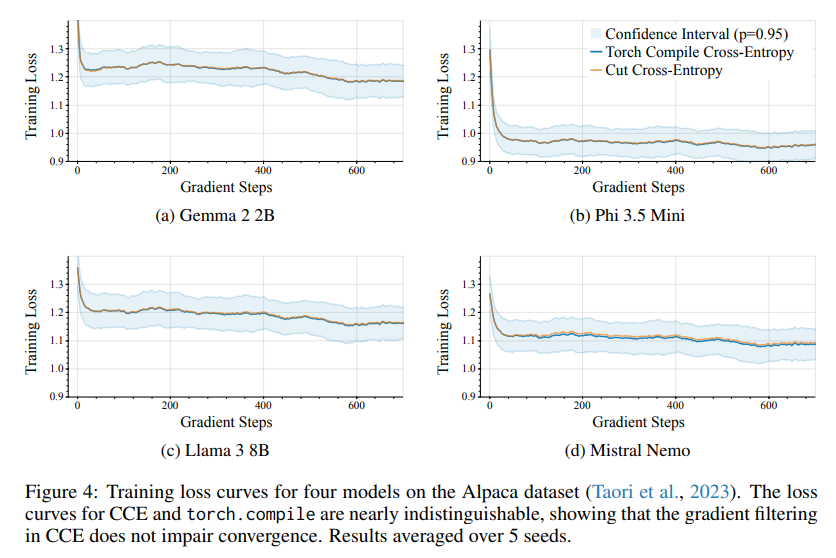

In conclusion, the CCE technique represents a major breakthrough in coaching giant language fashions by addressing the vital bottleneck of memory-intensive cross-entropy loss layers. By progressive strategies like dynamic logit computation, gradient filtering, and vocabulary sorting, CCE permits dramatic reductions in reminiscence utilization with out sacrificing velocity or accuracy. This development not solely enhances the effectivity of present fashions but in addition paves the way in which for extra scalable and balanced architectures sooner or later, opening new prospects for large-scale machine studying.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Clever Doc Processing with GenAI in Monetary Companies and Actual Property Transactions
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


