


Retrieval-augmented technology (RAG) programs are important in enhancing language mannequin efficiency by integrating exterior information sources into their workflows. These programs make the most of strategies that divide paperwork into smaller, manageable sections referred to as chunks. RAG programs intention to enhance each the accuracy and contextual relevance of their outputs by retrieving contextually applicable chunks and feeding them into generative language fashions. The sector is consistently evolving to deal with challenges associated to doc segmentation’s effectivity and scalability.
A key problem in RAG programs is guaranteeing that chunking methods successfully steadiness contextual preservation and computational effectivity. Conventional fixed-size chunking divides paperwork into uniform, consecutive components and infrequently fragments semantically associated content material. This fragmentation limits its usefulness in proof retrieval and reply technology duties. Whereas various methods like semantic chunking are gaining consideration for his or her skill to group semantically related data, their advantages over fixed-size chunking nonetheless must be found. Researchers have questioned whether or not these strategies can persistently justify the extra computational sources required.
Fastened-size chunking, whereas computationally simple, should be improved to take care of contextual continuity throughout doc segments. Researchers have proposed semantic chunking methods akin to breakpoint-based and clustering-based strategies. Breakpoint-based semantic chunking identifies factors of serious semantic dissimilarity between sentences to create coherent segments. In distinction, clustering-based chunking makes use of algorithms to group semantically related sentences, even when they aren’t consecutive. Numerous business instruments have carried out these strategies, however systematic effectiveness evaluations nonetheless must be extra sparse.
Researchers from Vectara, Inc., and the College of Wisconsin-Madison evaluated chunking methods to find out their efficiency throughout doc retrieval, proof retrieval, and reply technology duties. Utilizing sentence embeddings and knowledge from benchmark datasets, they in contrast fixed-size, breakpoint-based, and clustering-based semantic chunking strategies. The research aimed to measure retrieval high quality, reply technology accuracy, and computational prices. Additional, the workforce launched a novel analysis framework to deal with the necessity for ground-truth knowledge for chunk-level assessments.
The analysis concerned a number of datasets, together with stitched and unique paperwork, to simulate real-world complexities. Stitched datasets contained artificially mixed quick paperwork with excessive subject range, whereas unique datasets maintained their pure construction. The research used positional and semantic metrics for clustering-based chunking, combining cosine similarity with sentence positional proximity to enhance chunking accuracy. Breakpoint-based chunking relied on thresholds to find out segmentation factors. Fastened-size chunking included overlapping sentences between consecutive chunks to mitigate data loss. Metrics akin to F1 scores for doc retrieval and BERTScore for reply technology offered quantitative insights into efficiency variations.

The outcomes revealed that semantic chunking provided marginal advantages in high-topic range situations. As an illustration, the breakpoint-based semantic chunker achieved an F1 rating of 81.89% on the Miracl dataset, outperforming fixed-size chunking, which scored 69.45%. Nonetheless, these benefits might have been extra constant throughout different duties. In proof retrieval, fixed-size chunking carried out comparably or higher in three of 5 datasets, indicating its reliability in capturing core proof sentences. On datasets with pure constructions, akin to HotpotQA and MSMARCO, fixed-size chunking, they achieved F1 scores of 90.59% and 93.58%, respectively, demonstrating their robustness. Clustering-based strategies struggled with sustaining contextual integrity in situations the place positional data was essential.
Reply technology outcomes highlighted minor variations between chunking strategies. Fastened-size and semantic chunkers produced comparable outcomes, with semantic chunkers displaying barely increased BERTScores in sure circumstances. For instance, clustering-based chunking achieved a rating of 0.50 on the Qasper dataset, marginally outperforming fixed-size chunking’s rating of 0.49. Nonetheless, these variations have been insignificant sufficient to justify the extra computational prices related to semantic approaches.
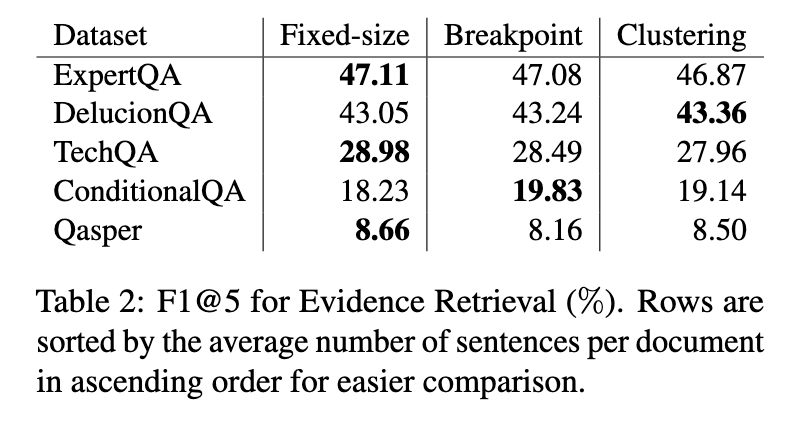
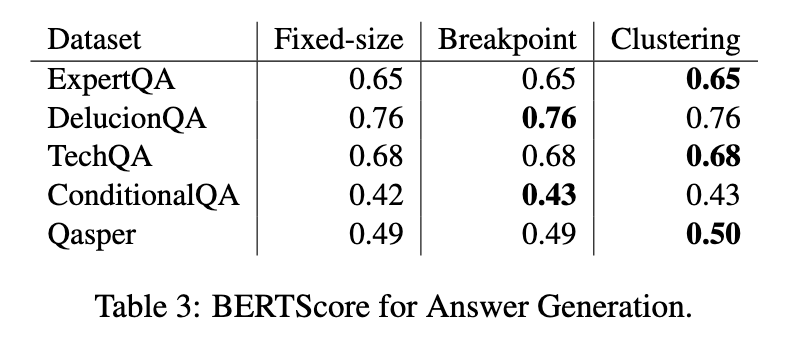
The findings emphasize that fixed-size chunking stays a sensible selection for RAG programs, notably in real-world purposes the place paperwork usually characteristic restricted subject range. Whereas semantic chunking often demonstrates superior efficiency in extremely particular circumstances, its computational calls for and inconsistent outcomes restrict its broader applicability. Researchers concluded that future work ought to concentrate on optimizing chunking methods to realize a greater steadiness between computational effectivity and contextual accuracy. The research underscores the significance of evaluating the trade-offs between chunking methods in RAG programs. By systematically evaluating these strategies, the researchers present invaluable insights into their strengths and limitations, guiding the event of extra environment friendly doc segmentation strategies.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Clever Doc Processing with GenAI in Monetary Companies and Actual Property Transactions– From Framework to Manufacturing

Sajjad Ansari is a closing 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.


