


In current occasions, Retrieval-augmented technology (RAG) has grow to be widespread because of its skill to resolve challenges utilizing Giant Language Fashions, equivalent to hallucinations and outdated coaching knowledge. A RAG pipeline consists of two elements: a retriever and a reader. The retriever part finds helpful data from an exterior data base, which is then included alongside a question in a immediate for the reader mannequin. This course of has been used as an efficient different to costly fine-tuning because it helps to scale back errors made by LLMs. Nonetheless, it’s unclear how a lot every a part of an RAG pipeline contributes to its efficiency on particular duties.
At present, retrieval fashions use Dense vector embedding fashions because of their higher efficiency than older strategies as they depend on phrase frequencies. These fashions use nearest-neighbor search algorithms to search out paperwork matching a question, with most dense retrievers encoding every doc as a single vector. Superior multi-vector fashions like ColBERT enable higher interactions between doc and question phrases, doubtlessly generalizing higher to new datasets. Nonetheless, dense vector embeddings are inefficient, particularly with high-dimensional knowledge, slowing down searches in giant databases. The RAG pipelines use an approximate nearest neighbor (ANN) search to enhance this by sacrificing some accuracy for quicker outcomes. Nonetheless, no clear steering exists on configuring ANN search to steadiness velocity and accuracy.
A bunch of researchers from the College of Colorado Boulder and Intel Labs carried out detailed analysis on optimizing RAG pipelines for frequent duties equivalent to Query Answering (QA). Specializing in understanding the affect of retrieval on downstream efficiency in RAG pipelines, pipelines have been evaluated through which the retriever and LLM elements have been individually educated. It was discovered that the method avoids the excessive useful resource prices of end-to-end coaching and clarifies the retriever’s contribution.
Experiments have been carried out to judge the efficiency of two instruction-tuned LLMs, LLaMA and Mistral, in Retrieval-Augmented Technology (RAG) pipelines with out fine-tuning or additional coaching. The analysis primarily centered on customary QA and attributed QA duties, the place fashions generated solutions utilizing retrieved paperwork, and it included particular doc citations within the case of attributed QA. Dense retrieval fashions equivalent to BGE-base and ColBERTv2 have been used to leverage environment friendly ANN seek for dense embeddings. The examined datasets included ASQA, QAMPARI, and Pure Questions (NQ), designed to evaluate retrieval and technology capabilities. Retrieval metrics relied on recall (retriever and search recall), whereas QA accuracy was measured utilizing actual match recall, and established frameworks assessed quotation high quality via quotation recall and precision. Confidence intervals have been computed utilizing bootstrapping to find out statistical significance throughout varied queries.
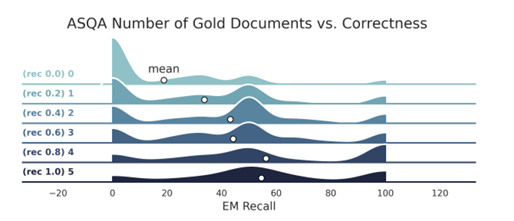
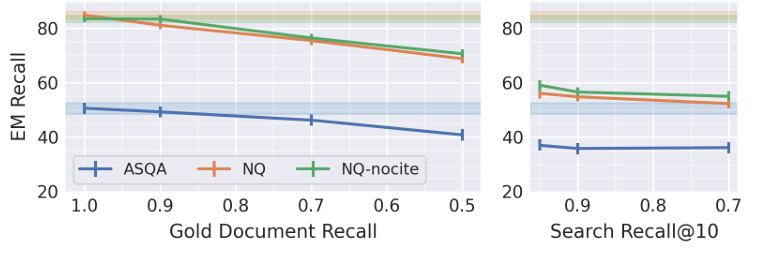
After evaluating the efficiency, the researchers discovered that retrieval typically improves efficiency, with ColBERT barely outperforming BGE by a small margin. The evaluation confirmed optimum correctness with 5-10 retrieved paperwork for Mistral, and 4-10 for LLaMA was achieved relying on the dataset. Notably, including a quotation immediate solely considerably impacted outcomes when the variety of retrieved paperwork (ok) exceeded 10. For some paperwork, the quotation precision was highest, and including extra led to too many citations. Together with gold paperwork drastically improved QA efficiency, and reducing the search recall from 1.0 to 0.7 had solely a small affect. Thus, the researchers discovered that decreasing the accuracy of the approximate nearest neighbor (ANN) search within the retriever has minimal results on job efficiency. Including noise to retrieval outcomes additionally results in a decline in efficiency. And the configuration was not discovered to surpass the gold customary.
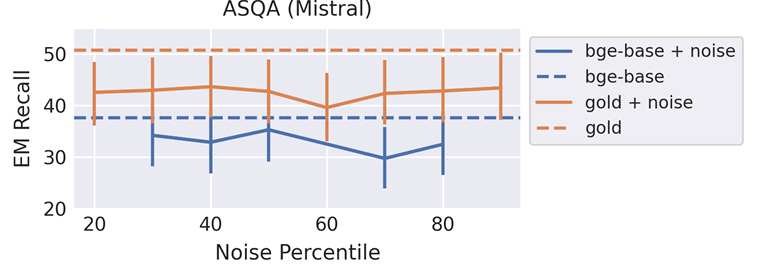
In conclusion, this analysis supplied helpful insights on enhancing retrieval methods for RAG pipelines and highlighted the significance of retrievers in boosting efficiency and effectivity, particularly for QA duties. It additionally confirmed that injecting noisy paperwork alongside gold or retrieved paperwork degrades correctness in comparison with the gold ceiling. Sooner or later, the generality of this analysis’s findings will be examined in different settings and may function a baseline for future analysis within the area of RAG pipelines!
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Clever Doc Processing with GenAI in Monetary Providers and Actual Property Transactions– From Framework to Manufacturing
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and clear up challenges.


