


Utilizing massive language fashions (LLMs) has revolutionized synthetic intelligence functions, enabling breakthroughs in pure language processing duties like conversational AI, content material technology, and automatic code completion. Usually with billions of parameters, these fashions depend on large reminiscence sources to retailer intermediate computation states and enormous key-value caches throughout inference. These fashions’ computational depth and rising measurement demand modern options to handle reminiscence with out sacrificing efficiency.
A important problem with LLMs is the restricted reminiscence capability of GPUs. When GPU reminiscence turns into inadequate to retailer the required information, methods offload parts of the workload to CPU reminiscence, a course of generally known as swapping. Whereas this expands reminiscence capability, it introduces delays resulting from information switch between CPU & GPU, considerably impacting the throughput and latency of LLM inference. The trade-off between growing reminiscence capability and sustaining computation effectivity stays a key bottleneck in advancing LLM deployment at scale.
Present options like vLLM and FlexGen try to handle this situation by means of numerous swapping methods. vLLM employs a paged reminiscence construction to handle the key-value cache, bettering reminiscence effectivity to some extent. FlexGen, alternatively, makes use of offline profiling to optimize reminiscence allocation throughout GPU, CPU, and disk sources. Nevertheless, these approaches usually want extra predictable latency, delayed computations, and an incapacity to dynamically adapt to workload adjustments, leaving room for additional innovation in reminiscence administration.
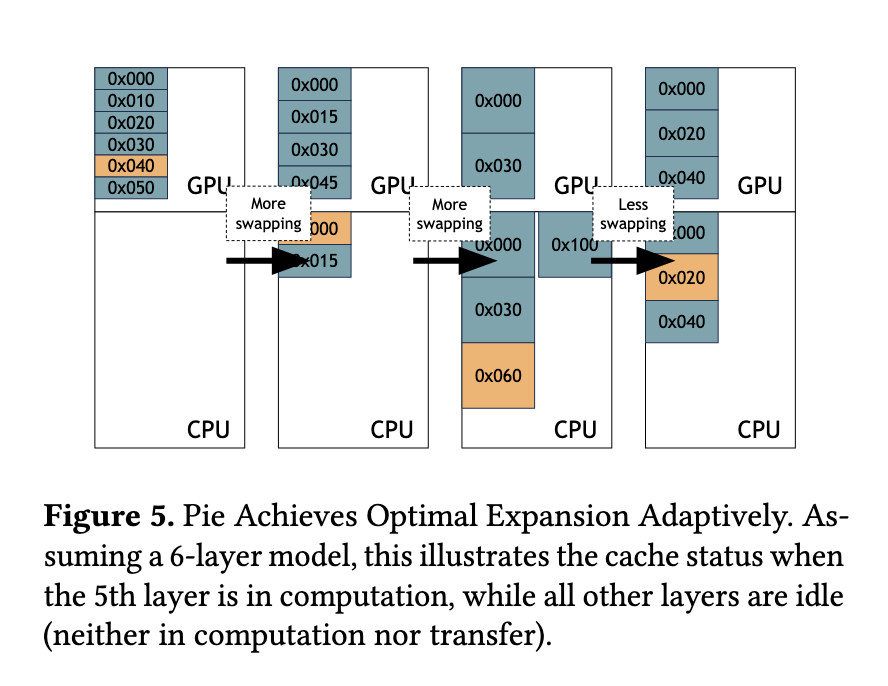
Researchers from UC Berkeley launched Pie, a novel inference framework designed to beat the challenges of reminiscence constraints in LLMs. Pie employs two core methods: performance-transparent swapping and adaptive enlargement. Leveraging predictable reminiscence entry patterns and superior {hardware} options like NVIDIA GH200 Grace Hopper Superchip’s high-bandwidth NVLink, Pie dynamically extends reminiscence capability with out including computational delays. This modern strategy permits the system to masks information switch latencies by executing them concurrently with GPU computations, guaranteeing optimum efficiency.
Pie’s methodology revolves round two pivotal parts. Efficiency-transparent swapping ensures that reminiscence transfers don’t delay GPU computations. That is achieved by prefetching information into the GPU reminiscence in anticipation of its use, using the excessive bandwidth of contemporary GPUs and CPUs. In the meantime, adaptive enlargement adjusts the quantity of CPU reminiscence used for swapping primarily based on real-time system situations. By dynamically allocating reminiscence as wanted, Pie prevents under-utilization or extreme swapping that might degrade efficiency. This design permits Pie to seamlessly combine CPU and GPU reminiscence, successfully treating the mixed sources as a single, expanded reminiscence pool for LLM inference.
Pie’s experimental evaluations demonstrated exceptional enhancements in efficiency metrics. In comparison with vLLM, Pie achieved as much as 1.9× greater throughput and a pair of× decrease latency in numerous benchmarks. Additional, Pie lowered GPU reminiscence utilization by 1.67× whereas sustaining comparable efficiency. Towards FlexGen, Pie confirmed an excellent better benefit, reaching as much as 9.4× greater throughput and considerably lowered latency, significantly in eventualities involving bigger prompts and extra complicated inference workloads. The experiments utilized state-of-the-art fashions, together with OPT-13B and OPT-30B, and ran on NVIDIA Grace Hopper cases with as much as 96GB of HBM3 reminiscence. The system effectively dealt with real-world workloads from datasets like ShareGPT and Alpaca, proving its sensible viability.
Pie’s means to dynamically adapt to various workloads and system environments units it aside from current strategies. The adaptive enlargement mechanism rapidly identifies the optimum reminiscence allocation configuration throughout runtime, guaranteeing minimal latency and most throughput. Even below constrained reminiscence situations, Pie’s performance-transparent swapping permits environment friendly utilization of sources, stopping bottlenecks and sustaining excessive system responsiveness. This adaptability was significantly evident throughout high-load eventualities, the place Pie scaled successfully to satisfy demand with out compromising efficiency.

Pie represents a major development in AI infrastructure by addressing the longstanding problem of reminiscence limitations in LLM inference. Its means to seamlessly broaden GPU reminiscence with minimal latency paves the best way for deploying bigger and extra complicated language fashions on current {hardware}. This innovation enhances the scalability of LLM functions and reduces the price boundaries related to upgrading {hardware} to satisfy the calls for of contemporary AI workloads. As LLMs develop in scale and software, frameworks like Pie will allow environment friendly and widespread use.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
Why AI-Language Fashions Are Nonetheless Susceptible: Key Insights from Kili Know-how’s Report on Giant Language Mannequin Vulnerabilities [Read the full technical report here]
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


