


Imaginative and prescient Transformers (ViTs) have revolutionized laptop imaginative and prescient by providing an revolutionary structure that makes use of self-attention mechanisms to course of picture knowledge. Not like Convolutional Neural Networks (CNNs), which depend on convolutional layers for characteristic extraction, ViTs divide pictures into smaller patches and deal with them as particular person tokens. This token-based strategy permits for scalable and environment friendly processing of enormous datasets, making ViTs notably efficient for high-dimensional duties reminiscent of picture classification and object detection. Their potential to decouple how info flows between tokens from how options are extracted inside tokens offers a versatile framework for addressing numerous laptop imaginative and prescient challenges.
Regardless of their success, a key query persists concerning the necessity of pre-training for ViTs. It has lengthy been assumed that pre-training enhances downstream activity efficiency by studying helpful characteristic representations. Nevertheless, researchers have begun questioning whether or not these options are the only contributors to efficiency enhancements or whether or not different elements, reminiscent of consideration patterns, would possibly play a extra important position. This investigation challenges the normal perception within the dominance of characteristic studying, suggesting {that a} deeper understanding of the mechanisms driving ViTs’ effectiveness may result in extra environment friendly coaching methodologies and improved efficiency.
Typical approaches to using pre-trained ViTs contain fine-tuning the complete mannequin on particular downstream duties. This course of combines consideration switch and have studying, making it troublesome to isolate every contribution. Whereas data distillation frameworks have been employed to switch logits or characteristic representations, they largely ignore the potential of consideration patterns. The shortage of targeted evaluation on consideration mechanisms limits a complete understanding of their position in bettering downstream activity outcomes. This hole highlights the necessity for strategies to evaluate consideration maps’ influence independently.
Researchers from Carnegie Mellon College and FAIR have launched a novel technique referred to as “Consideration Switch,” designed to isolate and switch solely the eye patterns from pre-trained ViTs. The proposed framework consists of two strategies: Consideration Copy and Consideration Distillation. In Consideration Copy, the pre-trained trainer ViT generates consideration maps straight utilized to a pupil mannequin whereas the scholar learns all different parameters from scratch. In distinction, Consideration Distillation makes use of a distillation loss perform to coach the scholar mannequin to align its consideration maps with the trainer’s, requiring the trainer mannequin solely throughout coaching. These strategies separate the intra-token computations from inter-token circulation, providing a recent perspective on pre-training dynamics in ViTs.
Consideration Copy transfers pre-trained consideration maps to a pupil mannequin, successfully guiding how tokens work together with out retaining realized options. This setup requires each the trainer and pupil fashions throughout inference, which can add computational complexity. Consideration Distillation, alternatively, refines the scholar mannequin’s consideration maps by a loss perform that compares them to the trainer’s patterns. After coaching, the trainer is not wanted, making this strategy extra sensible. Each strategies leverage the distinctive structure of ViTs, the place self-attention maps dictate inter-token relationships, permitting the scholar to concentrate on studying its options from scratch.
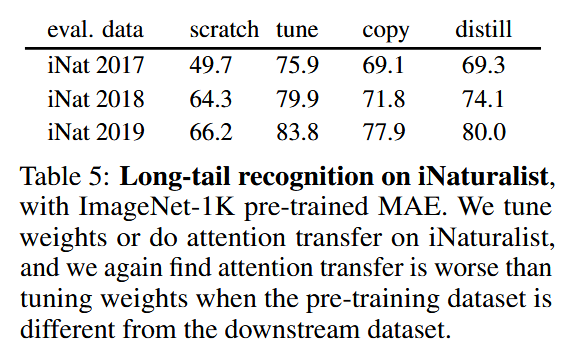
The efficiency of those strategies demonstrates the effectiveness of consideration patterns in pre-trained ViTs. Consideration Distillation achieved a top-1 accuracy of 85.7% on the ImageNet-1K dataset, equaling the efficiency of totally fine-tuned fashions. Whereas barely much less efficient, Consideration Copy closed 77.8% of the hole between coaching from scratch and fine-tuning, reaching 85.1% accuracy. Moreover, ensembling the scholar and trainer fashions enhanced accuracy to 86.3%, showcasing the complementary nature of their predictions. The examine additionally revealed that transferring consideration maps from task-specific fine-tuned academics additional improved accuracy, demonstrating the adaptability of consideration mechanisms to particular downstream necessities. Nevertheless, challenges arose beneath knowledge distribution shifts, the place consideration switch underperformed in comparison with weight tuning, highlighting limitations in generalization.

This analysis illustrates that pre-trained consideration patterns are enough for attaining excessive downstream activity efficiency, questioning the need of conventional feature-centric pre-training paradigms. The proposed Consideration Switch technique decouples consideration mechanisms from characteristic studying, providing an alternate strategy that reduces reliance on computationally intensive weight fine-tuning. Whereas limitations reminiscent of distribution shift sensitivity and scalability throughout various duties stay, this examine opens new avenues for optimizing the usage of ViTs in laptop imaginative and prescient. Future work may handle these challenges, refine consideration switch methods, and discover their applicability to broader domains, paving the best way for extra environment friendly, efficient machine studying fashions.
Try the Particulars. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Digital GenAI Convention ft. Meta, Mistral, Salesforce, Harvey AI & extra. Be part of us on Dec eleventh for this free digital occasion to study what it takes to construct large with small fashions from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and extra.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


