


Generative AI methods rework how people work together with expertise, providing groundbreaking pure language processing and content material technology capabilities. Nonetheless, these methods pose important dangers, notably in producing unsafe or policy-violating content material. Addressing this problem requires superior moderation instruments that guarantee outputs are protected and cling to moral pointers. Such instruments have to be efficient and environment friendly, notably for deployment on resource-constrained {hardware} similar to cellular gadgets.
One persistent problem in deploying security moderation fashions is their dimension and computational necessities. Whereas highly effective and correct, giant language fashions (LLMs) demand substantial reminiscence and processing energy, making them unsuitable for gadgets with restricted {hardware} capabilities. Deploying these fashions can result in runtime bottlenecks or failures for cellular gadgets with restricted DRAM, severely limiting their usability. To deal with this, researchers have targeted on compressing LLMs with out sacrificing efficiency.
Current strategies for mannequin compression, together with pruning and quantization, have been instrumental in decreasing mannequin dimension and enhancing effectivity. Pruning entails selectively eradicating much less vital mannequin parameters, whereas quantization reduces the precision of the mannequin weights to lower-bit codecs. Regardless of these developments, many options need assistance to successfully stability dimension, computational calls for, and security efficiency, notably when deployed on edge gadgets.
Researchers at Meta launched Llama Guard 3-1B-INT4, a security moderation mannequin designed to deal with these challenges. The mannequin, unveiled throughout Meta Join 2024, is simply 440MB, making it seven occasions smaller than its predecessor, Llama Guard 3-1B. This was achieved by means of superior compression strategies similar to decoder block pruning, neuron-level pruning, and quantization-aware coaching. The researchers additionally employed distillation from a bigger Llama Guard 3-8B mannequin to recuperate misplaced high quality throughout compression. Notably, the mannequin achieves a throughput of no less than 30 tokens per second with a time-to-first-token of lower than 2.5 seconds on a regular Android cellular CPU.
A number of key methodologies underpin the technical developments in Llama Guard 3-1B-INT4. Pruning strategies diminished the mannequin’s decoder blocks from 16 to 12 and the MLP hidden dimensions from 8192 to 6400, attaining a parameter depend of 1.1 billion, down from 1.5 billion. Quantization additional compressed the mannequin by decreasing the precision of weights to INT4 and activations to INT8, chopping its dimension by an element of 4 in comparison with a 16-bit baseline. Additionally, unembedding layer pruning diminished the output layer dimension by focusing solely on 20 essential tokens whereas sustaining compatibility with present interfaces. These optimizations ensured the mannequin’s usability on cellular gadgets with out compromising its security requirements.
The efficiency of Llama Guard 3-1B-INT4 underscores its effectiveness. It achieves an F1 rating of 0.904 for English content material, outperforming its bigger counterpart, Llama Guard 3-1B, which scores 0.899. For multilingual capabilities, the mannequin performs on par with or higher than bigger fashions in 5 out of eight examined non-English languages, together with French, Spanish, and German. In comparison with GPT-4, examined in a zero-shot setting, Llama Guard 3-1B-INT4 demonstrated superior security moderation scores in seven languages. Its diminished dimension and optimized efficiency make it a sensible answer for cellular deployment, and it has been proven efficiently on a Moto-Razor telephone.
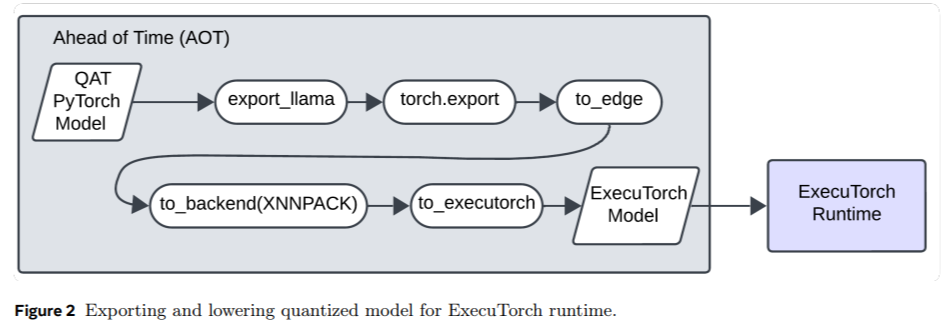
The analysis highlights a number of vital takeaways, summarized as follows:
- Compression Strategies: Superior pruning and quantization strategies can scale back LLM dimension by over 7× with out important loss in accuracy.
- Efficiency Metrics: Llama Guard 3-1B-INT4 achieves an F1 rating of 0.904 for English and comparable scores for a number of languages, surpassing GPT-4 in particular security moderation duties.
- Deployment Feasibility: The mannequin operates 30 tokens per second on commodity Android CPUs with a time-to-first-token of lower than 2.5 seconds, showcasing its potential for on-device purposes.
- Security Requirements: The mannequin maintains strong security moderation capabilities, balancing effectivity with effectiveness throughout multilingual datasets.
- Scalability: The mannequin permits scalable deployment on edge gadgets by decreasing computational calls for, broadening its applicability.


In conclusion, Llama Guard 3-1B-INT4 represents a big development in security moderation for generative AI. It addresses the vital challenges of dimension, effectivity, and efficiency, providing a compact mannequin for cellular deployment but strong sufficient to make sure excessive security requirements. Via progressive compression strategies and meticulous fine-tuning, researchers have created a software that’s each scalable and dependable, paving the best way for safer AI methods in numerous purposes.
Take a look at the Paper and Codes. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Overlook to hitch our 55k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


