


The static data base and hallucination-creating inaccuracy or fabrication of data are two widespread points with massive language fashions (LLMs). The parametric data inside LLMs is inherently static, making it difficult to supply up-to-date data in real-time situations. Retrieval-augmented technology (RAG) addresses the issue of integrating exterior, real-time data to reinforce accuracy and relevance. Nevertheless, noise, ambiguity, and deviation in intent in consumer queries are sometimes a hindrance to efficient doc retrieval. Question rewriting performs an essential position in refining such inputs to make sure that retrieved paperwork extra intently match the precise intent of the consumer.
Present strategies for question rewriting in RAG techniques will be broadly categorized into two- training-based and prompt-based approaches. Coaching-based strategies contain supervised fine-tuning utilizing annotated knowledge or reinforcement studying, whereas prompt-based strategies use immediate engineering to information LLMs in particular rewriting methods. Whereas prompt-based strategies are cost-effective, they usually lack generalization and variety. Multi-strategy rewriting addresses these points by combining totally different prompt-based strategies to deal with numerous question sorts and improve retrieval variety.
To deal with this, researchers from Renmin College of China, Southeast College, Beijing Jiaotong College, and Kuaishou Know-how have proposed DMQR-RAG, a Various Multi-Question Rewriting framework. This framework makes use of 4 methods of rewriting at totally different ranges of data to enhance efficiency over baseline approaches. Furthermore, an adaptive technique choice methodology is proposed to reduce the variety of rewrites whereas optimizing general efficiency.
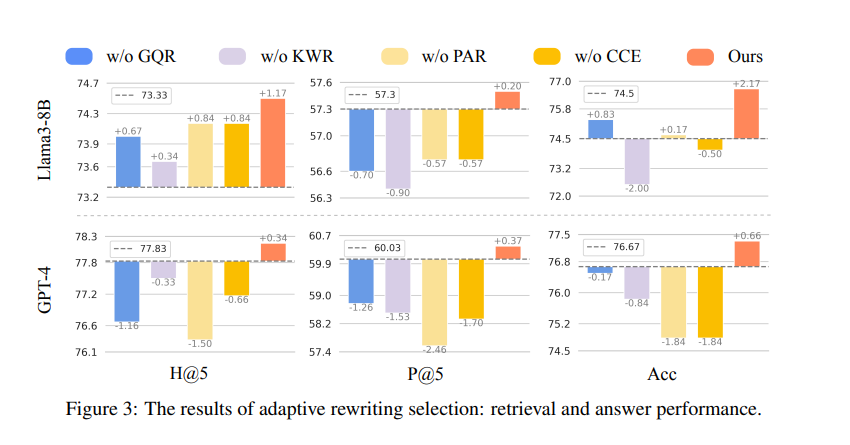
The DMQR-RAG framework launched 4 rewriting methods: GQR, KWR, PAR, and CCE. GQR refines a question by omitting noise and sustaining related data to supply the precise question. Equally, KWR is used to extract key phrases that search engines like google and yahoo want. PAR constructs a pseudo reply to broaden the question with helpful data, whereas CCE concentrates on discovering key data the place detailed queries have been extracted.
The framework additionally helps a method choice methodology of adaptive rewriting technique that dynamically determines one of the best methods for any given question, avoiding superfluous rewrites and optimizing retrieval efficiency. In each educational and industrial environments, by way of a variety of experiments, these proposed strategies validate that the processes might result in important enchancment in doc retrieval and remaining response high quality. The strategy outperforms baseline strategies, reaching roughly 10% efficiency features and demonstrating specific effectiveness for smaller language fashions by lowering pointless rewrites and minimizing retrieval noise. The proposed methodology demonstrated superior efficiency throughout datasets like AmbigNQ, HotpotQA, and FreshQA, reaching greater recall (H@5) and precision (P@5) in comparison with baselines. For instance, DMQR-RAG improved P@5 by as much as 14.46% on FreshQA and surpassed RAG-Fusion in most metrics. It additionally confirmed versatility by performing properly with smaller LLMs and proving efficient in real-world business situations.
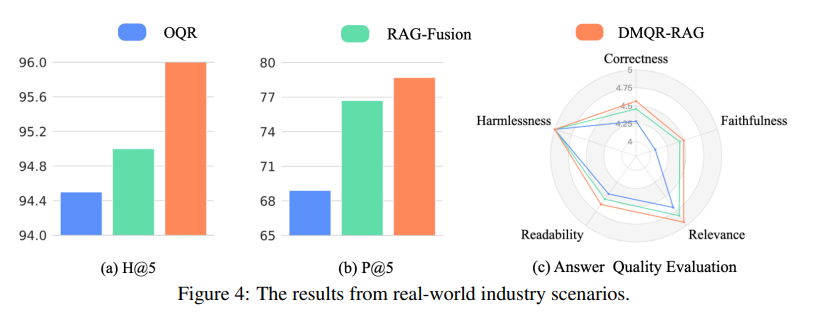
In conclusion, DMQR-RAG solved the issue of bettering relevance-aggregate retrieval techniques, growing a various multi-query rewriting framework, and an adaptive technique choice methodology. Its enhancements embrace enhanced relevance and variety of retrieved paperwork. These improvements result in higher general efficiency in retrieval-augmented technology. DMQR-RAG proves efficient in real-world situations, bettering question retrieval throughout 15 million consumer queries. It will increase hit and precision charges whereas enhancing response correctness and relevance with out sacrificing different efficiency metrics.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
Nazmi Syed is a consulting intern at MarktechPost and is pursuing a Bachelor of Science diploma on the Indian Institute of Know-how (IIT) Kharagpur. She has a deep ardour for Information Science and actively explores the wide-ranging purposes of synthetic intelligence throughout varied industries. Fascinated by technological developments, Nazmi is dedicated to understanding and implementing cutting-edge improvements in real-world contexts.


