


Code intelligence has grown quickly, pushed by developments in massive language fashions (LLMs). These fashions are more and more utilized for automated programming duties equivalent to code technology, debugging, and testing. With capabilities spanning a number of languages and domains, LLMs have turn out to be essential instruments in advancing software program growth, knowledge science, and computational problem-solving. The evolution of LLMs is remodeling how advanced programming duties are approached and executed.
One vital space for enchancment within the present panorama is the necessity for complete benchmarks that precisely mirror real-world programming calls for. Present analysis datasets, equivalent to HumanEval, MBPP, and DS-1000, are sometimes narrowly targeted on particular domains, like superior algorithms or machine studying, failing to seize the range required for full-stack programming. Furthermore, these datasets may very well be extra in depth in assessing the multilingual and domain-spanning capabilities needed for real-world software program growth. This hole poses a significant impediment to successfully measuring and advancing LLM efficiency.
Researchers from ByteDance Seed and M-A-P have launched FullStack Bench, a benchmark that evaluates LLMs throughout 11 distinct software domains and helps 16 programming languages. The benchmark consists of knowledge evaluation, desktop and internet growth, machine studying, and multimedia. Additional, they developed SandboxFusion, a unified execution surroundings that automates code execution and analysis in a number of languages. These instruments goal to supply a holistic framework for testing LLMs in real-world situations and overcoming the constraints of present benchmarks.
The FullStack Bench dataset comprises 3,374 issues, every accompanied by unit take a look at circumstances, reference options, and straightforward, medium, and arduous problem classifications. Issues have been curated utilizing a mixture of human experience and LLM-assisted processes, making certain variety and high quality in query design. SandboxFusion helps the execution of FullStack Bench issues by enabling safe, remoted execution environments that accommodate the necessities of various programming languages and dependencies. It helps 23 programming languages, offering a scalable and versatile resolution for benchmarking LLMs on datasets past FullStack Bench, together with widespread benchmarks like HumanEval and MBPP.
The researchers performed in depth experiments to guage the efficiency of varied LLMs on FullStack Bench. Outcomes revealed marked variations in efficiency throughout domains and programming languages. For instance, whereas some fashions demonstrated sturdy fundamental programming and knowledge evaluation capabilities, others wanted assist with multimedia and working system-related duties. Move@1, the first analysis metric, assorted throughout domains, highlighting fashions’ challenges in adapting to various and sophisticated programming duties. SandboxFusion proved to be a sturdy and environment friendly analysis software, considerably outperforming present execution environments in supporting a variety of programming languages and dependencies.
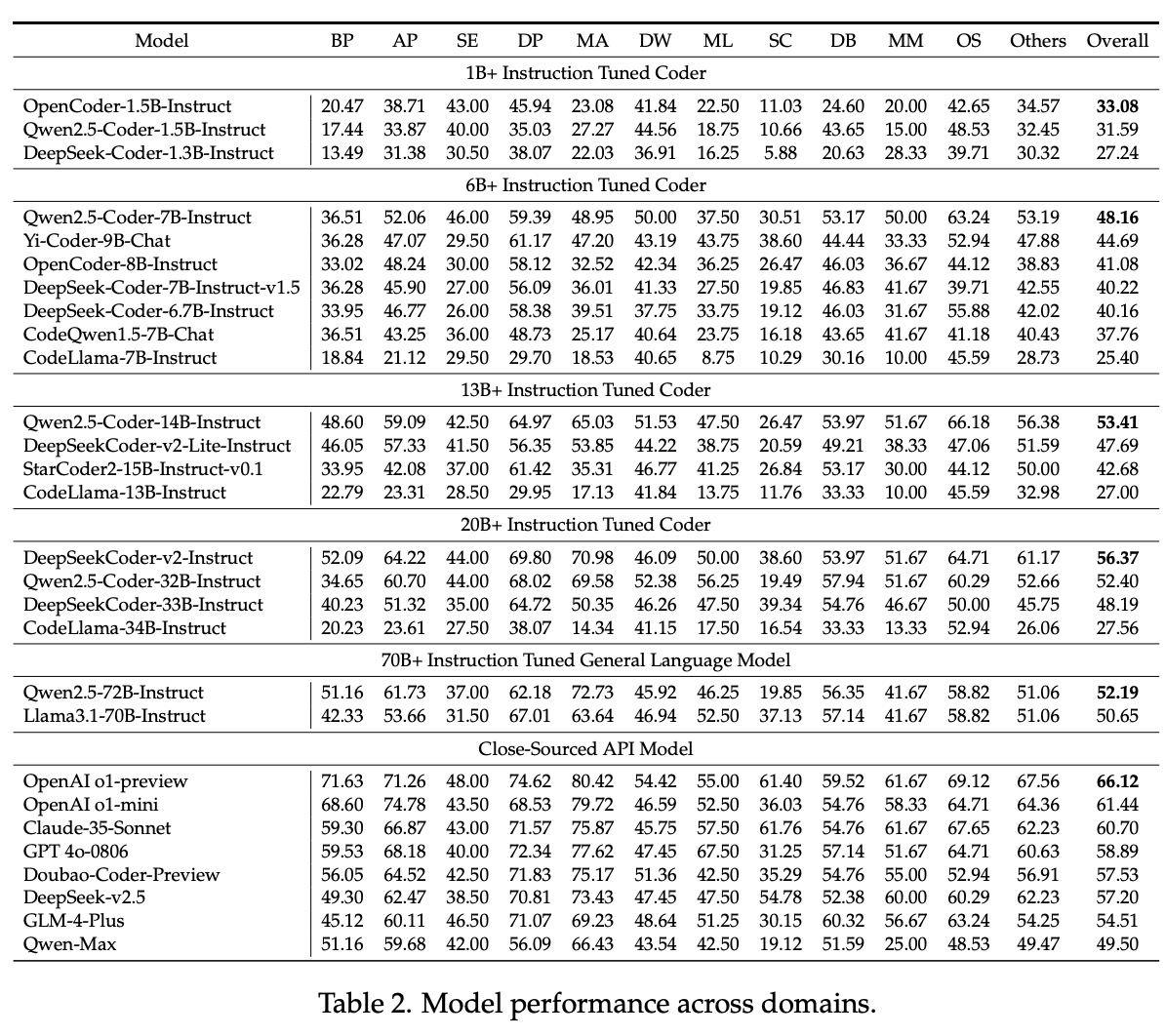
Scaling legal guidelines have been additionally analyzed, exhibiting that rising parameters usually improves mannequin efficiency. Nonetheless, researchers noticed a efficiency decline for some fashions at greater scales. For instance, the Qwen2.5-Coder collection peaked at 14B parameters however confirmed a drop in efficiency at 32B and 72B. This discovering underscores the significance of balancing mannequin dimension and effectivity in optimizing LLM efficiency. Researchers noticed a constructive correlation between code compilation cross charges and take a look at success charges, emphasizing the necessity for exact and error-free code technology.
The FullStack Bench and SandboxFusion collectively characterize vital developments in evaluating LLMs. By addressing the constraints of present benchmarks, these instruments allow a extra complete evaluation of LLM capabilities throughout various domains and programming languages. This analysis lays the groundwork for additional improvements in code intelligence and emphasizes the significance of creating instruments that precisely mirror real-world programming situations.
Take a look at the Paper, FullStack Bench, and SandboxFusion. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication.. Don’t Overlook to hitch our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Rework proofs-of-concept into production-ready AI functions and brokers’ (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


