

")
Massive Imaginative and prescient Language Fashions (LVLMs) have demonstrated vital developments throughout varied difficult multi-modal duties over the previous few years. Their skill to interpret visible data in figures, referred to as visible notion, relied on visible encoders and multimodal coaching. Even with these developments, visible notion errors nonetheless trigger many errors in LVLMs and affect their skill to grasp picture particulars wanted for duties.
Latest widespread datasets for evaluating LVLMs, akin to MMMU and MathVista, dont concentrate on visible notion and goal duties that require expert-level reasoning and data. As well as, efficiency on these datasets is affected by a number of capabilities, and since visible notion is tough to guage instantly, it’s tough to evaluate efficiency. Most benchmarks on multimodal reasoning in scientific figures are often restricted to software domains that demand professional data and neglect visible notion. Common visible notion datasets goal duties like OCR, depth estimation, and counting however lack fine-grained element because of the problem of designing particular questions. Whereas some datasets are designed to guage the visible notion of LVLMs, they usually goal much less fine-grained visible data, akin to scene understanding.
To unravel this, a bunch of researchers from Penn State College proposed VisOnlyQA, a brand new dataset designed to instantly consider the visible notion capabilities of LVLMs on questions on geometric and numerical data in scientific figures. Bridging the hole, VisOnlyQA targeted on fine-grain visible particulars and goal evaluation of LVLMs’ visible notion functionality to construct new limitations on prior datasets and generated artificial figures from scripts, together with variety and precision. Questions have been manually annotated or generated mechanically utilizing metadata and templates, avoiding the necessity for reasoning or area data. The dataset had three splits: Eval-Actual, Eval-Artificial, and Practice, with balanced labels and excessive annotation high quality confirmed by human efficiency (93.5% to 95% accuracy).
The examine evaluates the efficiency of 20 open-source and proprietary LVLMs on the VisOnlyQA dataset, specializing in their visible notion capabilities. The fashions have been assessed on geometry, chemistry, and chart evaluation duties, with and with out chain-of-thought reasoning. Outcomes confirmed that the fashions carried out considerably worse than people, with common accuracies round 54.2% for the real-world dataset and 42.4% for artificial information, far under human efficiency (93.5% and 95.0%, respectively).
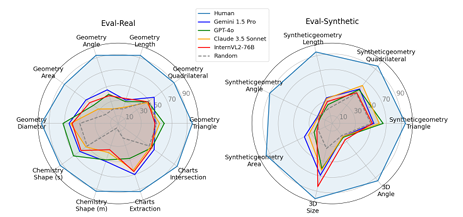
Regardless of the big mannequin sizes, akin to Phi-3.5-Imaginative and prescient and LLaVA-Subsequent, most of the fashions carried out near-randomly on duties like Geometry-Triangle and Charts Intersection, indicating that present LVLMs nonetheless wrestle with visible notion duties involving geometric and numerical data. The evaluation additionally confirmed that chain-of-thought reasoning didn’t constantly enhance efficiency and, in some instances, even worsened it, additional emphasizing that VisOnlyQA instantly evaluates visible notion slightly than requiring reasoning. Error evaluation revealed that almost all errors have been associated to visible notion, supporting the dataset’s skill to evaluate this functionality.
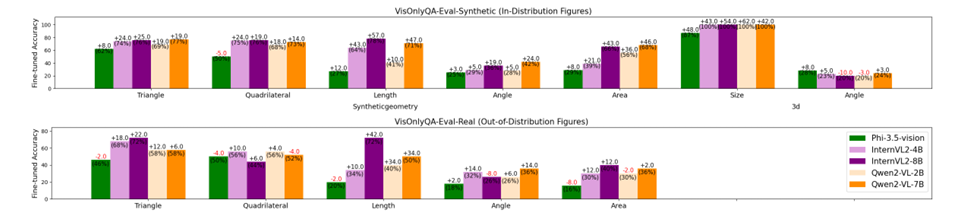
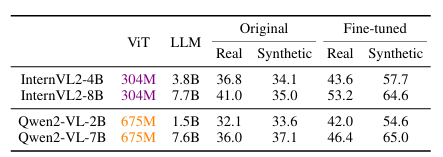
In conclusion, the proposed VisOnlyQA was launched as a dataset to evaluate the visible notion talents of LVLMs by questions on geometric and numerical particulars in scientific figures. This technique revealed that LVLMs nonetheless lack sturdy visible notion capabilities. There’s nice scope sooner or later to enhance coaching information and mannequin architectures to reinforce their visible notion. This technique can open new methods within the area of LVLMs and might function a baseline for upcoming analysis!
Take a look at the Particulars right here and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 [Must Subscribe]: Subscribe to our e-newsletter to get trending AI analysis and dev updates
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and clear up challenges.


