


LG AI Analysis has launched bilingual fashions expertizing in English and Korean primarily based on EXAONE 3.5 as open supply following the success of its predecessor, EXAONE 3.0. The analysis workforce has expanded the EXAONE 3.5 fashions, together with three varieties designed for particular use circumstances:
- The two.4B mannequin is an ultra-lightweight model optimized for on-device use. It might function on low-spec GPUs and in environments with restricted infrastructure.
- A light-weight 7.8B mannequin provides improved efficiency over its predecessor, the EXAONE-3.0-7.8B-Instruct mannequin whereas sustaining versatility for general-purpose use.
- The 32B mannequin represents a frontier-level high-performance choice for demanding purposes, catering to customers who prioritize computational energy.
The EXAONE 3.5 fashions display distinctive efficiency and cost-efficiency, achieved by way of LG AI Analysis’s revolutionary R&D methodologies. The hallmark characteristic of EXAONE 3.5 is its help for long-context processing, permitting the dealing with of as much as 32,768 tokens. This functionality makes it efficient in addressing the calls for of real-world use circumstances and Retrieval-Augmented Technology (RAG) eventualities, the place prolonged textual inputs are widespread. Every mannequin within the EXAONE 3.5 sequence has demonstrated state-of-the-art efficiency in real-world purposes and duties requiring long-context understanding.
Coaching Methodologies and Architectural Improvements of EXAONE 3.5
Coaching EXAONE 3.5 language fashions includes a mix of superior configurations, pre-training methods, and post-training refinements to maximise efficiency and usefulness. The fashions are constructed on a state-of-the-art decoder-only Transformer structure, with configurations various primarily based on mannequin measurement. Whereas structurally much like EXAONE 3.0 7.8B, the EXAONE 3.5 fashions introduce enhancements resembling prolonged context size, supporting as much as 32,768 tokens, a major improve from the earlier 4,096 tokens. The structure incorporates superior options like SwiGLU non-linearities, Grouped Question Consideration (GQA), and Rotary Place Embeddings (RoPE), guaranteeing environment friendly processing and enhanced bilingual help for English and Korean. All fashions share a vocabulary of 102,400 tokens, evenly divided between the 2 languages.
The pre-training section of EXAONE 3.5 was performed in two phases. The primary stage targeted on numerous knowledge sources to reinforce normal area efficiency, whereas the second stage focused particular domains requiring improved capabilities, resembling long-context understanding. In the course of the second stage, a replay-based methodology was employed to handle catastrophic forgetting, permitting the mannequin to retain data from the preliminary coaching section. Computational sources had been optimized throughout pre-training; for instance, the 32B mannequin achieved excessive efficiency with considerably decrease computation necessities than different fashions of comparable measurement. A rigorous decontamination course of was utilized to remove contaminated examples within the coaching knowledge, guaranteeing the reliability of benchmark evaluations.
Put up-training, the fashions underwent supervised fine-tuning (SFT) to reinforce their potential to reply successfully to different directions. This concerned creating an instruction-response dataset from a taxonomy of information derived from net corpora. The dataset was designed to incorporate a spread of complexities, enabling the mannequin to generalize properly throughout duties. Choice optimization was then employed utilizing Direct Choice Optimization (DPO) and different algorithms to align the fashions with human preferences. This course of included a number of coaching phases to stop over-optimization and enhance output alignment with person expectations. LG AI Analysis performed in depth evaluations to handle potential authorized dangers like copyright infringement and private info safety to make sure knowledge compliance. Steps had been taken to de-identify delicate knowledge and make sure that all datasets met strict moral and authorized requirements.
Benchmark Evaluations: Unparalleled Efficiency of EXAONE 3.5 Bilingual Fashions
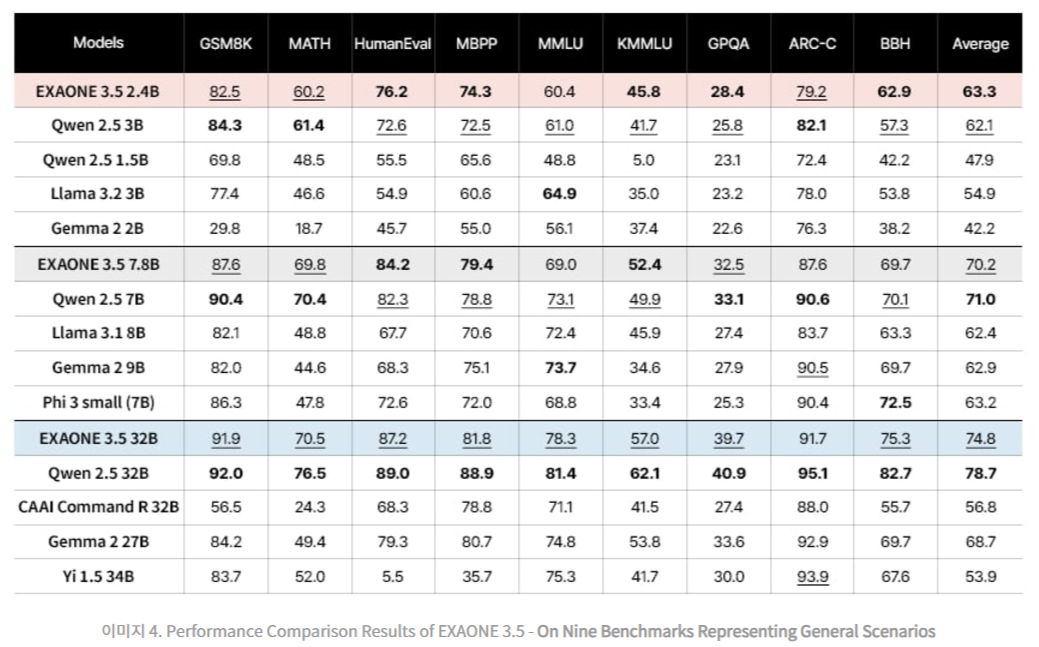
The analysis benchmarks of EXAONE 3.5 Fashions had been categorized into three teams: real-world use circumstances, long-context processing, and normal area duties. Actual-world benchmarks evaluated the fashions’ potential to know and reply to person queries in sensible eventualities. Lengthy-context benchmarks assessed the fashions’ functionality to course of and retrieve info from prolonged textual inputs, which is vital for RAG purposes. Normal area benchmarks examined the fashions’ proficiency in arithmetic, coding, and knowledge-based duties. EXAONE 3.5 fashions persistently carried out properly throughout all benchmark classes. The 32B and seven.8B fashions excelled in real-world use circumstances and long-context eventualities, usually surpassing baseline fashions of comparable measurement. For instance, the 32B mannequin achieved a median rating of 74.3 in real-world use circumstances, considerably outperforming opponents like Qwen 2.5 32B and Gemma 2 27B.
Equally, in long-context benchmarks, the fashions demonstrated a superior potential to course of and perceive prolonged contexts in each English and Korean. On exams like Needle-in-a-Haystack (NIAH), all three fashions achieved near-perfect retrieval accuracy, showcasing their strong efficiency in duties requiring detailed context comprehension. The two.4B mannequin was an environment friendly choice for resource-constrained environments, outperforming baseline fashions of comparable measurement in all classes. Regardless of its smaller measurement, it delivered aggressive outcomes usually area duties, resembling fixing mathematical issues and writing supply code. For instance, the two.4B mannequin scored a median of 63.3 throughout 9 benchmarks usually eventualities, surpassing bigger fashions like Gemma 2 9B in a number of metrics. Actual-world use case evaluations integrated benchmarks like MT-Bench, KoMT-Bench, and LogicKor, the place EXAONE 3.5 fashions had been judged on multi-turn responses. They achieved excessive scores in each English and Korean, highlighting their bilingual proficiency. As an illustration, the 32B mannequin achieved top-tier ends in MT-Bench with a rating of 8.51, producing correct and contextually related responses.
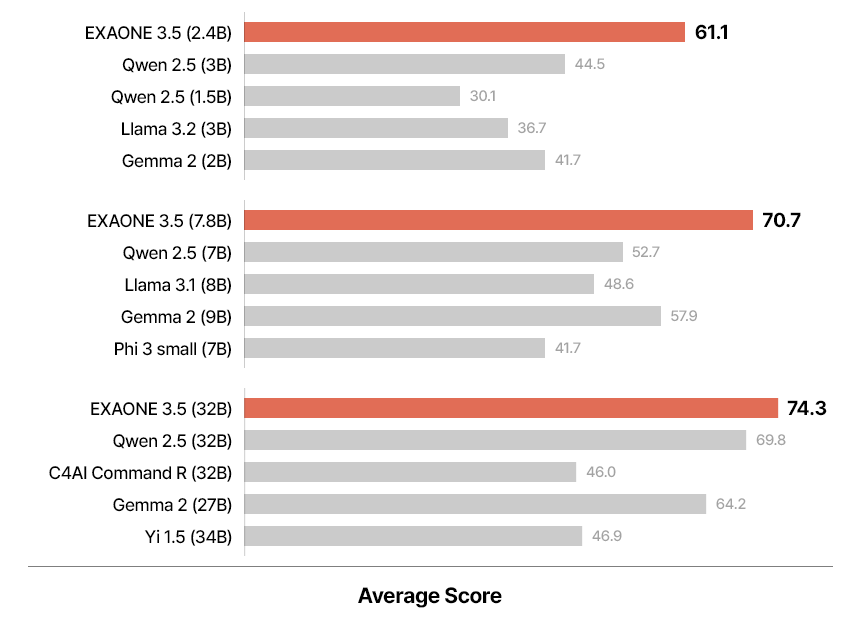
Within the long-context class, EXAONE 3.5 fashions had been evaluated utilizing benchmarks like LongBench and LongRAG and in-house exams like Ko-WebRAG. The fashions demonstrated distinctive long-context processing capabilities, persistently outperforming baselines in retrieving and reasoning over prolonged texts. The 32B mannequin, for instance, scored 71.1 on common throughout long-context benchmarks, cementing its standing as a pacesetter on this area. Normal area evaluations included benchmarks for arithmetic, coding, and parametric data. The EXAONE 3.5 fashions delivered aggressive efficiency in comparison with friends. The 32B mannequin achieved a median rating of 74.8 throughout 9 benchmarks, whereas the 7.8B mannequin scored 70.2.
Accountable AI Improvement: Moral and Clear Practices
The event of EXAONE 3.5 fashions adhered to LG AI Analysis’s Accountable AI Improvement Framework, prioritizing knowledge governance, moral issues, and danger administration. Recognizing these fashions’ open nature and potential for widespread use throughout varied domains, the framework goals to maximise social advantages whereas sustaining equity, security, accountability, and transparency. This dedication aligns with the LG AI Ethics Ideas, which information AI applied sciences’ moral use and deployment. EXAONE 3.5 fashions profit the AI group by addressing suggestions from the EXAONE 3.0 launch.
Nonetheless, releasing open fashions like EXAONE 3.5 additionally entails potential dangers, together with inequality, misuse, and the unintended technology of dangerous content material. LG AI Analysis performed an AI moral affect evaluation to mitigate these dangers, figuring out challenges resembling bias, privateness violations, and regulatory compliance. Authorized danger assessments had been carried out on all datasets, and delicate info was eliminated by way of de-identification processes. Bias in coaching knowledge was addressed by way of pre-processing documentation and analysis, guaranteeing excessive knowledge high quality and equity. To make sure secure and accountable use of the fashions, LG AI Analysis verified the open-source libraries employed and dedicated to monitoring AI rules throughout totally different jurisdictions. Efforts to reinforce the explainability of AI inferences had been additionally prioritized to construct belief amongst customers and stakeholders. Whereas totally explaining AI reasoning stays difficult, ongoing analysis goals to enhance transparency and accountability. The protection of EXAONE 3.5 fashions was assessed utilizing a third-party dataset supplied by the Ministry of Science and ICT of the Republic of Korea. This analysis examined the fashions’ potential to filter out dangerous content material, with outcomes exhibiting some effectiveness however highlighting the necessity for additional enchancment.
Key Takeaways, Actual-World Purposes, and Enterprise Partnerships of EXAONE 3.5
- Distinctive Lengthy Context Understanding: EXAONE 3.5 fashions stand out for his or her strong long-context processing capabilities, achieved by way of RAG expertise. Every mannequin can successfully deal with 32K tokens. Not like fashions claiming theoretical long-context capacities, EXAONE 3.5 has an “Efficient Context Size” of 32K, making it extremely practical for sensible purposes. Its bilingual proficiency ensures top-tier efficiency in processing advanced English and Korean contexts.
- Superior Instruction Following Capabilities: EXAONE 3.5 excels in usability-focused duties, delivering the very best common scores throughout seven benchmarks representing real-world use circumstances. This demonstrates its potential to reinforce productiveness and effectivity in industrial purposes. All three fashions carried out considerably higher than international fashions of comparable sizes in English and Korean.
- Robust Normal Area Efficiency: EXAONE 3.5 fashions ship wonderful outcomes throughout 9 benchmarks usually domains, significantly in arithmetic and programming. The two.4B mannequin ranks first in common scores amongst fashions of comparable measurement, showcasing its effectivity for resource-constrained environments. In the meantime, the 7.8B and 32B fashions obtain aggressive scores, demonstrating EXAONE 3.5’s versatility in dealing with varied duties.
- Dedication to Accountable AI Improvement: LG AI Analysis has prioritized moral issues and transparency within the improvement of EXAONE 3.5. An AI moral affect evaluation recognized and addressed potential dangers resembling inequality, dangerous content material, and misuse. The fashions excel at filtering out hate speech and unlawful content material, though the two.4B mannequin requires enchancment in addressing regional and occupational biases. Clear disclosure of analysis outcomes underscores LG AI Analysis’s dedication to fostering moral AI improvement and inspiring additional analysis into accountable AI.
- Sensible Purposes and Enterprise Partnerships: EXAONE 3.5 is being built-in into real-world purposes by way of partnerships with corporations like Polaris Workplace and Hancom. These collaborations purpose to include EXAONE 3.5 into software program options, enhancing effectivity and productiveness for each company and public sectors. A Proof of Idea (PoC) undertaking with the Hancom highlights the potential for AI-driven improvements to remodel authorities and public establishment workflows, showcasing the mannequin’s sensible enterprise worth.
Conclusion: A New Commonplace in Open-Supply AI
In conclusion, LG AI Analysis has set a brand new benchmark with the discharge of EXAONE 3.5, a 3-model sequence of open-source LLMs. Combining superior instruction-following capabilities and unparalleled long-context understanding, EXAONE 3.5 is designed to satisfy the varied wants of researchers, companies, and industries. Its versatile vary of fashions, 2.4B, 7.8B, and 32B, provides tailor-made options for resource-constrained environments and high-performance purposes. These open-sourced 3-model sequence will be accessed on Hugging Face. Customers can keep related by following LG AI Analysis’s LinkedIn web page and LG AI Analysis Web site for the newest updates, insights, and alternatives to have interaction with their newest developments.
Sources
Because of the LG AI Analysis workforce for the thought management/ Assets for this text. LG AI Analysis workforce has supported us on this content material/article.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


