


Video era has improved with fashions like Sora, which makes use of the Diffusion Transformer (DiT) structure. Whereas text-to-video (T2V) fashions have superior, they usually discover it onerous to create clear and constant movies with out further references. Textual content-image-to-video (TI2V) fashions tackle this limitation through the use of an preliminary picture body as grounding to enhance readability. Reaching Sora-level efficiency continues to be tough as it’s onerous to mix image-based inputs with the mannequin successfully, and higher-quality datasets are wanted to enhance the mannequin’s output, making it robust to attain the identical stage of success as Sora.
Present strategies explored integrating picture circumstances into U-Web architectures, however making use of these methods to DiT fashions remained unresolved. Whereas diffusion-based approaches dominated text-to-video era through the use of LDMs, scaling fashions, and shifting to transformer-based architectures, many research targeted on remoted points, overlooking their mixed impression on efficiency. Methods like cross-attention in PixArt-α, self-attention in SD3, and stability tips similar to QK–norm confirmed some enhancements however grew to become much less efficient as fashions scaled. Regardless of developments, no unified mannequin efficiently mixed T2V and TI2V capabilities, limiting progress towards extra environment friendly and versatile video era.
To unravel this, researchers from Apple and the College of California developed a complete framework that systematically examined the interplay between mannequin architectures, coaching strategies, and knowledge curation methods. The ensuing STIV methodology is an easy and scalable text-image-conditioned video era strategy. Utilizing body alternative, it incorporates picture circumstances right into a Diffusion Transformer (DiT) and applies textual content conditioning by way of a joint image-text conditional classifier-free steering. This design permits STIV to carry out text-to-video (T2V) and text-image-to-video concurrently (TI2V) duties. Moreover, STIV will be simply expanded to functions like video prediction, body interpolation, multi-view era, and lengthy video era.

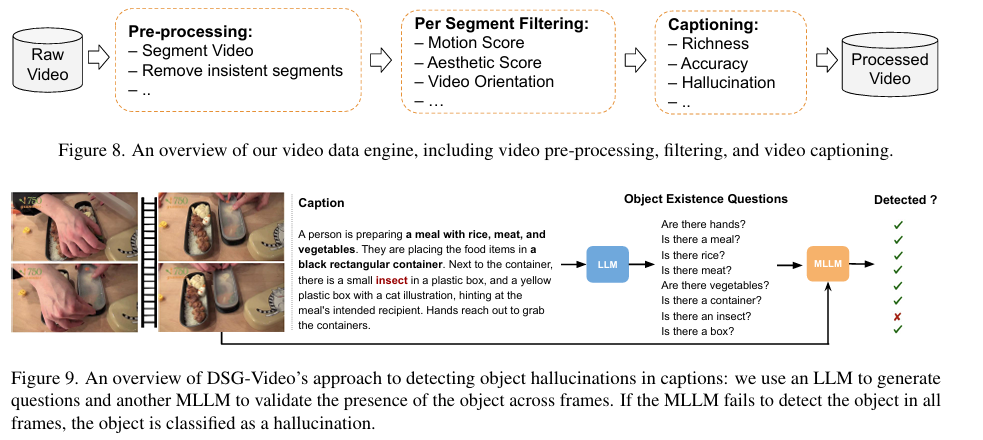
Researchers investigated the setup, coaching, and analysis course of for text-to-video (T2V) and text-to-image (T2I) fashions. The fashions used the AdaFactor optimizer, with a selected studying charge and gradient clipping, and have been skilled for 400k steps. Knowledge preparation concerned a video knowledge engine that analyzed video frames, carried out scene segmentation, and extracted options like movement and readability scores—the coaching utilized curated datasets, together with over 90 million high-quality video-caption pairs. Key analysis metrics, together with temporal high quality, semantic alignment, and video-image alignment, have been assessed utilizing VBench, VBench-I2V, and MSRVTT. The examine additionally explored ablation methods, similar to utilizing completely different architectural designs and coaching methods, together with Stream Matching, CFG-Renormalization, and AdaFactor Optimizer. Experiments on mannequin initialization confirmed that joint initialization from decrease and better decision fashions improved efficiency. Moreover, utilizing extra frames throughout coaching enhanced metrics, significantly movement smoothness and dynamic vary.
The T2V and STIV fashions considerably improved after scaling from 600M to 8.7B parameters. In T2V, the VBench-Semantic rating elevated from 72.5 to 74.8 with bigger mannequin sizes and improved to 77.0 when the decision was raised from 256 to 512. Effective-tuning with high-quality knowledge boosted the VBench-High quality rating from 82.2 to 83.9, with the most effective mannequin reaching a VBench-Semantic rating of 79.5. Equally, the STIV mannequin confirmed developments, with the STIV-M-512 mannequin reaching a VBench-I2V rating of 90.1. In video prediction, the STIV-V2V mannequin outperformed T2V with an FVD rating of 183.7 in comparison with 536.2. The STIV-TUP mannequin delivered unbelievable ends in body interpolation, with FID scores of 2.0 and 5.9 on MSRVTT and MovieGen datasets. Within the multi-view era, the proposed STIV mannequin maintained the 3D coherency and achieved comparable efficiency to Zero123++ with Pa SNR of 21.64 and LPIPS of 0.156. In lengthy video era, it generated 380 frames, which confirmed its efficiency with potential for additional progress.

In the long run, the proposed framework offered a scalable and versatile answer for video era by integrating textual content and picture conditioning inside a unified mannequin. It demonstrated robust efficiency on public benchmarks and flexibility throughout varied functions, together with controllable video era, video prediction, body interpolation, lengthy video era, and multi-view era. This strategy highlighted its potential to help future developments in video era and contribute to the broader analysis neighborhood!
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and resolve challenges.


