


Multimodal giant language fashions (MLLMs) are advancing quickly, enabling machines to interpret and purpose about textual and visible knowledge concurrently. These fashions have transformative functions in picture evaluation, visible query answering, and multimodal reasoning. By bridging the hole between imaginative and prescient & language, they play a vital function in enhancing synthetic intelligence’s capability to grasp and work together with the world holistically.
Regardless of their promise, these methods want to beat important challenges. A core limitation is the reliance on pure language supervision for coaching, typically leading to suboptimal visible illustration high quality. Whereas growing dataset measurement and computational complexity have led to modest enhancements, they want extra focused optimization for visible understanding inside these fashions to make sure they obtain the specified efficiency in vision-based duties. Present strategies ceaselessly have to stability computational effectivity and improved efficiency.
Present strategies for coaching MLLMs sometimes contain utilizing visible encoders to extract options from pictures and feeding them into the language mannequin alongside pure language knowledge. Some strategies make use of a number of visible encoders or cross-attention mechanisms to reinforce understanding. Nevertheless, these approaches come at the price of considerably larger knowledge and computation necessities, limiting their scalability and practicality. This inefficiency underscores the necessity for a more practical solution to optimize MLLMs for visible comprehension.
Researchers at SHI Labs at Georgia Tech and Microsoft Analysis launched a novel strategy known as OLA-VLM to deal with these challenges. The strategy goals to enhance MLLMs by distilling auxiliary visible data into their hidden layers throughout pretraining. As an alternative of accelerating visible encoder complexity, OLA-VLM leverages embedding optimization to reinforce the alignment of visible and textual knowledge. Introducing this optimization into intermediate layers of the language mannequin ensures higher visible reasoning with out further computational overhead throughout inference.
The expertise behind OLA-VLM entails embedding loss capabilities to optimize representations from specialised visible encoders. These encoders are skilled for picture segmentation, depth estimation, and picture era duties. The distilled options are mapped to particular layers of the language mannequin utilizing predictive embedding optimization strategies. Additional, particular task-specific tokens are appended to the enter sequence, permitting the mannequin to include auxiliary visible data seamlessly. This design ensures that the visible options are successfully built-in into the MLLM’s representations with out disrupting the first coaching goal of next-token prediction. The result’s a mannequin that learns extra strong and vision-centric representations.
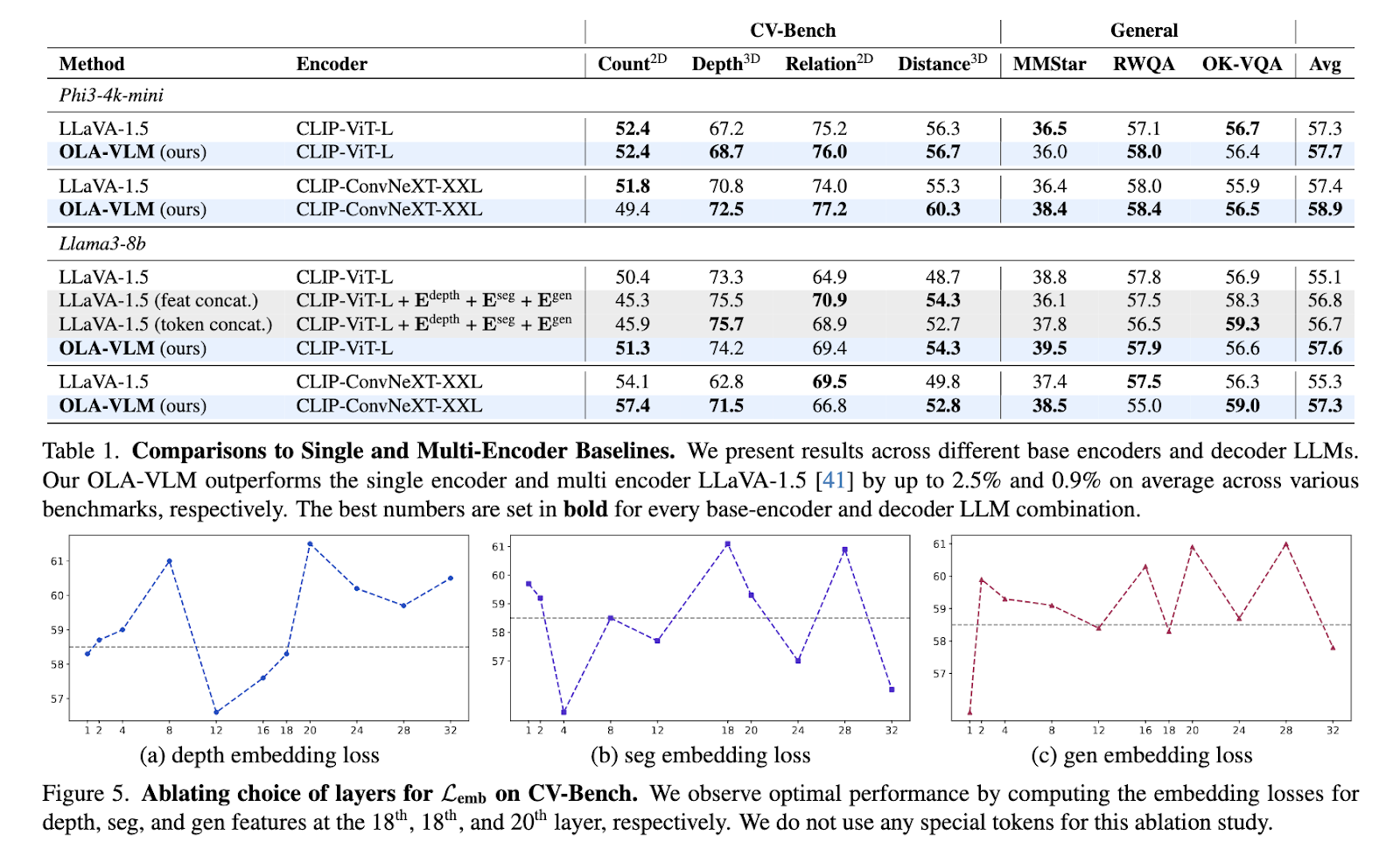
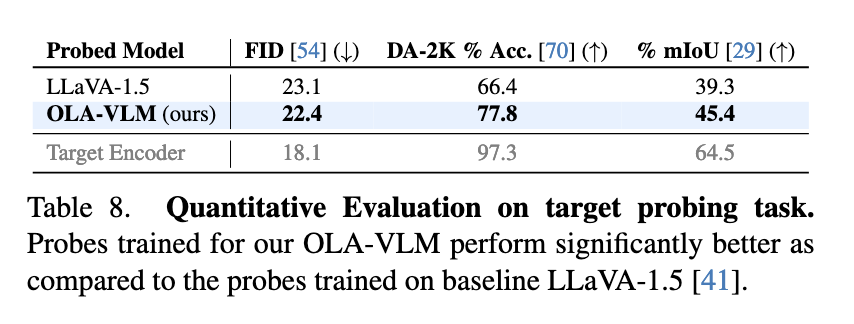
The efficiency of OLA-VLM was rigorously examined on varied benchmarks, displaying substantial enhancements over present single- and multi-encoder fashions. On CV-Bench, a vision-centric benchmark suite, OLA-VLM outperformed the LLaVA-1.5 baseline by as much as 8.7% in in-depth estimation duties, reaching an accuracy of 77.8%. For segmentation duties, it achieved a imply Intersection over Union (mIoU) rating of 45.4%, considerably enhancing over the baseline’s 39.3%. The mannequin additionally demonstrated constant good points throughout 2D and 3D imaginative and prescient duties, reaching a median enchancment of as much as 2.5% on benchmarks like distance and relation reasoning. OLA-VLM achieved these outcomes utilizing solely a single visible encoder throughout inference, making it much more environment friendly than multi-encoder methods.
To additional validate its effectiveness, researchers analyzed the representations discovered by OLA-VLM. Probing experiments revealed that the mannequin achieved superior visible function alignment in its intermediate layers. This alignment considerably enhanced the mannequin’s downstream efficiency throughout varied duties. As an illustration, the researchers famous that integrating particular task-specific tokens throughout coaching contributed to higher optimizing options for depth, segmentation, and picture era duties. The outcomes underscored the effectivity of the predictive embedding optimization strategy, proving its functionality to stability high-quality visible understanding with computational effectivity.
OLA-VLM establishes a brand new customary for integrating visible data into MLLMs by specializing in embedding optimization throughout pretraining. This analysis addresses the hole in present coaching strategies by introducing a vision-centric perspective to enhance the standard of visible representations. The proposed strategy enhances efficiency on vision-language duties and achieves this with fewer computational sources in comparison with present strategies. OLA-VLM exemplifies how focused optimization throughout pretraining can considerably enhance multimodal mannequin efficiency.
In conclusion, the analysis performed by SHI Labs and Microsoft Analysis highlights a groundbreaking development in multimodal AI. By optimizing visible representations inside MLLMs, OLA-VLM bridges a important hole in efficiency and effectivity. This technique demonstrates how embedding optimization can successfully deal with challenges in vision-language alignment, paving the way in which for extra strong and scalable multimodal methods sooner or later.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


