


Graphical Consumer Interfaces (GUIs) play a elementary function in human-computer interplay, offering the medium by way of which customers accomplish duties throughout net, desktop, and cell platforms. Automation on this discipline is transformative, doubtlessly drastically bettering productiveness and enabling seamless activity execution with out requiring handbook intervention. Autonomous brokers able to understanding and interacting with GUIs may revolutionize workflows, significantly in repetitive or complicated activity settings. Nonetheless, GUIs’ inherent complexity and variability throughout platforms pose vital challenges. Every platform makes use of distinct visible layouts, motion areas, and interplay logic, making creating scalable and strong options tough. Creating techniques that may navigate these environments autonomously whereas generalizing throughout platforms stays an ongoing problem for researchers on this area.
There are a lot of technical hurdles in GUI automation proper now; one is aligning pure language directions with the varied visible representations of GUIs. Conventional strategies typically depend on textual representations, equivalent to HTML or accessibility bushes, to mannequin GUI parts. These approaches are restricted as a result of GUIs are inherently visible, and textual abstractions fail to seize the nuances of visible design. As well as, textual representations fluctuate between platforms, resulting in fragmented knowledge and inconsistent efficiency. This mismatch between the visible nature of GUIs and the textual inputs utilized in automation techniques leads to decreased scalability, longer inference occasions, and restricted generalization. Additionally, most present strategies are incapable of efficient multimodal reasoning and grounding, that are important for understanding complicated visible environments.
Present instruments and methods have tried to deal with these challenges with combined success. Many techniques rely on closed-source fashions to reinforce reasoning and planning capabilities. These fashions typically use pure language communication to mix grounding and reasoning processes, however this method introduces info loss and lacks scalability. One other widespread limitation is the fragmented nature of coaching datasets, which fail to supply complete assist for grounding and reasoning duties. For example, datasets usually emphasize both grounding or reasoning, however not each, resulting in fashions that excel in a single space whereas struggling in others. This division hampers the event of unified options for autonomous GUI interplay.
The College of Hong Kong researchers and Salesforce Analysis launched AGUVIS (7B and 72B), a unified framework designed to beat these limitations by leveraging pure vision-based observations. AGUVIS eliminates the reliance on textual representations and as an alternative focuses on image-based inputs, aligning the mannequin’s construction with the visible nature of GUIs. The framework features a constant motion area throughout platforms, facilitating cross-platform generalization. AGUVIS integrates specific planning and multimodal reasoning to navigate complicated digital environments. The researchers constructed a large-scale dataset of GUI agent trajectories, which was used to coach AGUVIS in a two-stage course of. The framework’s modular structure, which features a pluggable motion system, permits for seamless adaptation to new environments and duties.
The AGUVIS framework employs a two-stage coaching paradigm to equip the mannequin with grounding and reasoning capabilities:
- Through the first stage, the mannequin focuses on grounding and mapping pure language directions to visible parts inside GUI environments. This stage makes use of a grounding packing technique, bundling a number of instruction-action pairs right into a single GUI screenshot. This technique improves coaching effectivity by maximizing the utility of every picture with out sacrificing accuracy.
- The second stage introduces planning and reasoning, coaching the mannequin to execute multi-step duties throughout varied platforms and situations. This stage incorporates detailed internal monologues, which embody commentary descriptions, ideas, and low-level motion directions. By progressively rising the complexity of coaching knowledge, the mannequin learns to deal with nuanced duties with precision and flexibility.
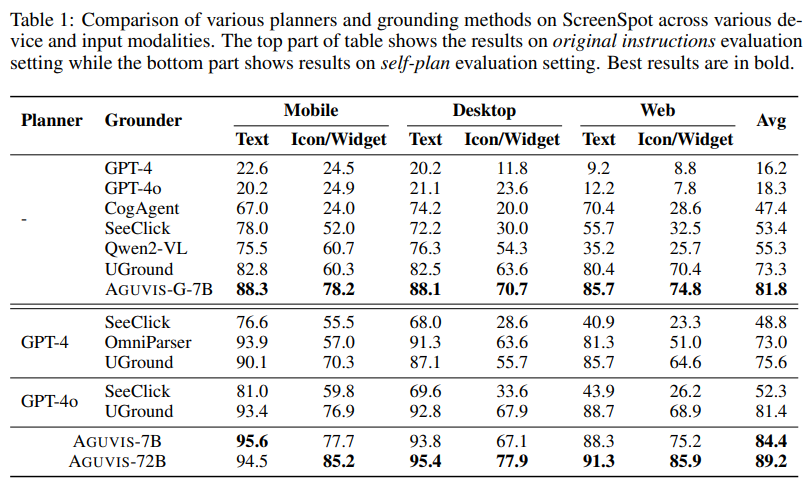
AGUVIS demonstrated nice leads to each offline and real-world on-line evaluations. In GUI grounding, the mannequin achieved a median accuracy of 89.2, surpassing state-of-the-art strategies throughout cell, desktop, and net platforms. In on-line situations, AGUVIS outperformed competing fashions with a 51.9% enchancment in step success charge throughout offline planning duties. Additionally, the mannequin achieved a 93% discount in inference prices in comparison with GPT-4o. By specializing in visible observations and integrating a unified motion area, AGUVIS units a brand new benchmark for GUI automation, making it the first absolutely autonomous pure vision-based agent able to finishing real-world duties with out reliance on closed-source fashions.
Key takeaways from the analysis on AGUVIS within the discipline of GUI automation:
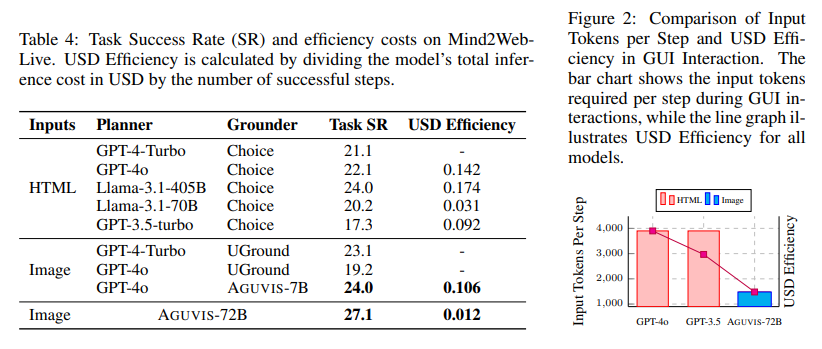
- AGUVIS makes use of image-based inputs, decreasing token prices considerably and aligning the mannequin with the inherently visible nature of GUIs. This method leads to a token value of just one,200 for 720p picture observations, in comparison with 6,000 for accessibility bushes and 4,000 for HTML-based observations.
- The mannequin combines grounding and planning phases, enabling it to carry out single- and multi-step duties successfully. The grounding coaching alone equips the mannequin to course of a number of directions inside a single picture, whereas the reasoning stage enhances its potential to execute complicated workflows.
- The AGUVIS Assortment unifies and augments present datasets with artificial knowledge to assist multimodal reasoning and grounding. This leads to a various and scalable dataset, enabling the coaching of strong and adaptable fashions.
- Utilizing pyautogui instructions and a pluggable motion system permits the mannequin to generalize throughout platforms whereas accommodating platform-specific actions, equivalent to swiping on cell units.
- AGUVIS achieved exceptional leads to GUI grounding benchmarks, with accuracy charges of 88.3% on net platforms, 85.7% on cell, and 81.8% on desktops. Additionally, it demonstrated superior effectivity, decreasing USD inference prices by 93% in comparison with present fashions.
In conclusion, the AGUVIS framework addresses crucial challenges in grounding, reasoning, and generalization in GUI automation. Its purely vision-based method eliminates the inefficiencies related to textual representations, whereas its unified motion area permits seamless interplay throughout numerous platforms. The analysis offers a sturdy answer for autonomous GUI duties, with purposes starting from productiveness instruments to superior AI techniques.
Try the Paper, GitHub Web page, and Venture. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for World Management in Generative AI Excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


