


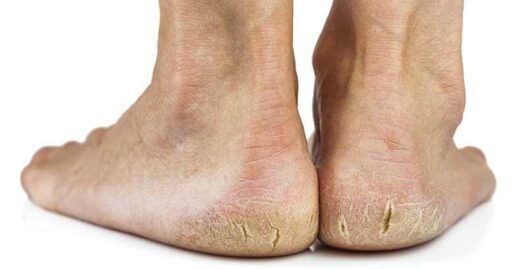
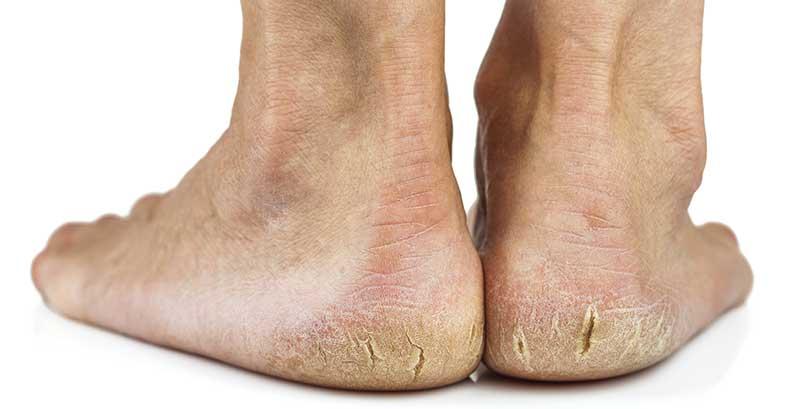
Avec l’arrivée de l’automne et de l’hiver, beaucoup remarquent une peau sèche et crevassée au niveau des talons. Ce problème affecte non seulement l’apparence des pieds mais peut devenir extrêmement douloureux s’il n’est pas traité. Les crevasses talonnières peuvent entraîner des infections et rendre la marche atroce si elles s’aggravent.
Mais quelles sont les causes des talons fissurés ? Comment prévenir ou soulager ce problème ? Examinons en détail les causes, symptômes et solutions.
Causes des talons crevassés : bien plus qu’une simple sécheresse cutanée
Les crevasses talonnières désignent des zones de peau sèche et rugueuse présentant des fissures, particulièrement au niveau du talon. Ces gerçures varient de légères à sévères, souvent accompagnées d’un épaississement cutané semblable à des callosités. Lorsque les fissures atteignent les couches profondes, elles provoquent d’intenses douleurs. 
Normalement, la peau des pieds reste souple, hydratée et élastique pour résister aux frottements et pressions de la marche. Mais en cas de déshydratation, elle devient rugueuse et sujette aux crevasses.
Principales causes :
- Sécheresse cutanée : Manque d’hydratation ou de lipides naturels
- Climat froid et sec : Aggravation saisonnière en automne/hiver
- Station debout prolongée : Pression accrue sur les talons
- Chaussures ouvertes : Sandales sans soutien talonnier
- Surpoids : Pression supplémentaire sur les talons
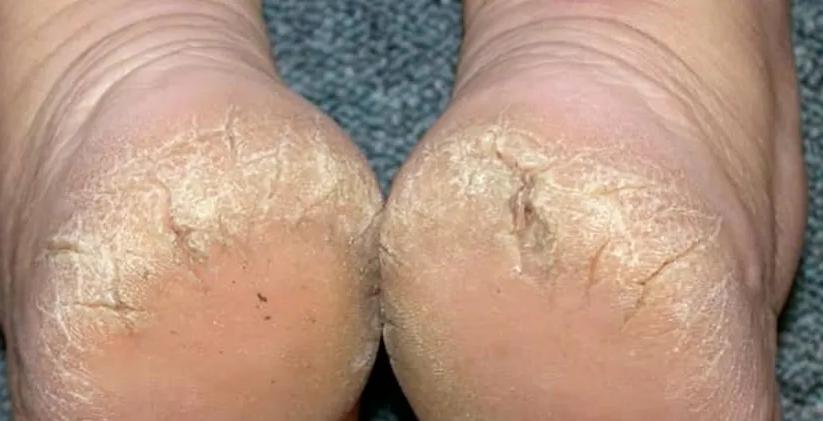
Certaines pathologies comme le diabète et l’hypothyroïdie favorisent également les crevasses talonnières. 31% des diabétiques en seraient affectés.
Les infections fongiques (pied d’athlète) peuvent aussi causer des fissures, accompagnées de démangeaisons, cloques et desquamation. Un traitement antifongique est alors nécessaire.
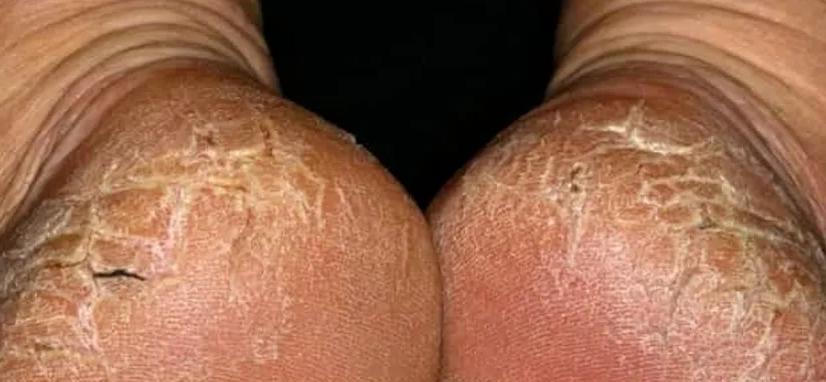
Symptômes : manifestations des talons crevassés
La sévérité varie : débutant par une peau sèche et épaissie (teinte jaunâtre/brune), les fissures s’approfondissent progressivement. Non traitées, elles provoquent des douleurs à la marche, parfois des saignements, croûtes ou infections.
Chez les diabétiques déséquilibrés, ces lésions peuvent évoluer en ulcérations chroniques.
4 méthodes maison pour soulager les talons crevassés
Solutions efficaces :
- Bains de pieds : Trempage quotidien de 10-20 minutes dans l’eau tiède pour assouplir la peau

- Éliminer les peaux mortes : Utilisez une pierre ponce ou un gommage pour pieds pour exfolier en douceur l’épaississement cutané des talons.
- Utiliser des produits efficaces : Appliquez des produits contenant des ingrédients comme l’urée, les acides alpha-hydroxyliques, l’acide salicylique ou l’acide lactique pour hydrater et assouplir la peau.

- Hydratation post-soin : Avant de dormir, appliquez une couche épaisse de vaseline ou d’un riche hydratant pour sceller l’humidité et favoriser la guérison.
Prévention : Comment maintenir la santé de vos talons
Comme pour de nombreux problèmes, la prévention vaut mieux que le traitement. Voici quelques conseils pour garder vos talons en pleine forme, surtout pendant les mois froids :
- Hydrater régulièrement : Utilisez des crèmes épaisses ou des onguents pour maintenir l’hydratation cutanée, surtout par temps froid et sec.
- Porter des chaussures adaptées : Évitez les chaussures à talons ouverts. Privilégiez des chaussures bien ajustées et soutenantes.
- Utiliser des semelles appropriées : Choisissez des semelles qui redistribuent la pression sur vos talons et évitez les modèles rigides non soutenants.
- Limiter les stations debout ou marches prolongées : Dans la mesure du possible, évitez de rester debout ou de marcher trop longtemps pour réduire la pression sur vos talons.

Conclusion : Gardez vos talons lisses et sans douleur
En suivant ces simples conseils, vous pouvez prévenir les crevasses aux talons et maintenir la santé de vos pieds toute l’année. Hydratez régulièrement, protégez vos pieds avec des chaussures soutenantes et agissez rapidement dès l’apparition de fissures. Avec les bons soins, vous profiterez de talons doux et indolores, pas à pas !









