


Massive language fashions (LLMs) have revolutionized pure language processing (NLP), notably for English and different data-rich languages. Nonetheless, this fast development has created a big improvement hole for underrepresented languages, with Cantonese being a main instance. Regardless of being spoken by over 85 million individuals and holding financial significance in areas just like the Guangdong-Hong Kong-Macau Higher Bay Space, Singapore, and North America, Cantonese stays severely underrepresented in NLP analysis. This disparity is very regarding given the language’s widespread use and the financial significance of Cantonese-speaking areas. The dearth of NLP assets for Cantonese, notably when in comparison with languages from equally developed areas, poses a vital problem for researchers and practitioners aiming to develop efficient language applied sciences for this extensively spoken language.
The event of Cantonese-specific LLMs faces important challenges on account of restricted analysis and assets. Most current Cantonese LLM expertise stays closed-source, hindering widespread progress within the subject. Whereas some small-scale neural networks have been developed for particular Cantonese NLP duties comparable to rumor detection, sentiment evaluation, machine translation, dialogue techniques, and language modeling, complete LLM options are missing. The shortage of coaching information and benchmarks for Cantonese LLMs additional complicates improvement efforts. Current information assets and analysis metrics are inadequate for comprehensively assessing the assorted capabilities of Cantonese LLMs. This lack of strong analysis instruments makes it tough to measure progress and examine totally different fashions successfully, in the end slowing down the development of Cantonese language expertise within the quickly evolving panorama of NLP and LLMs.

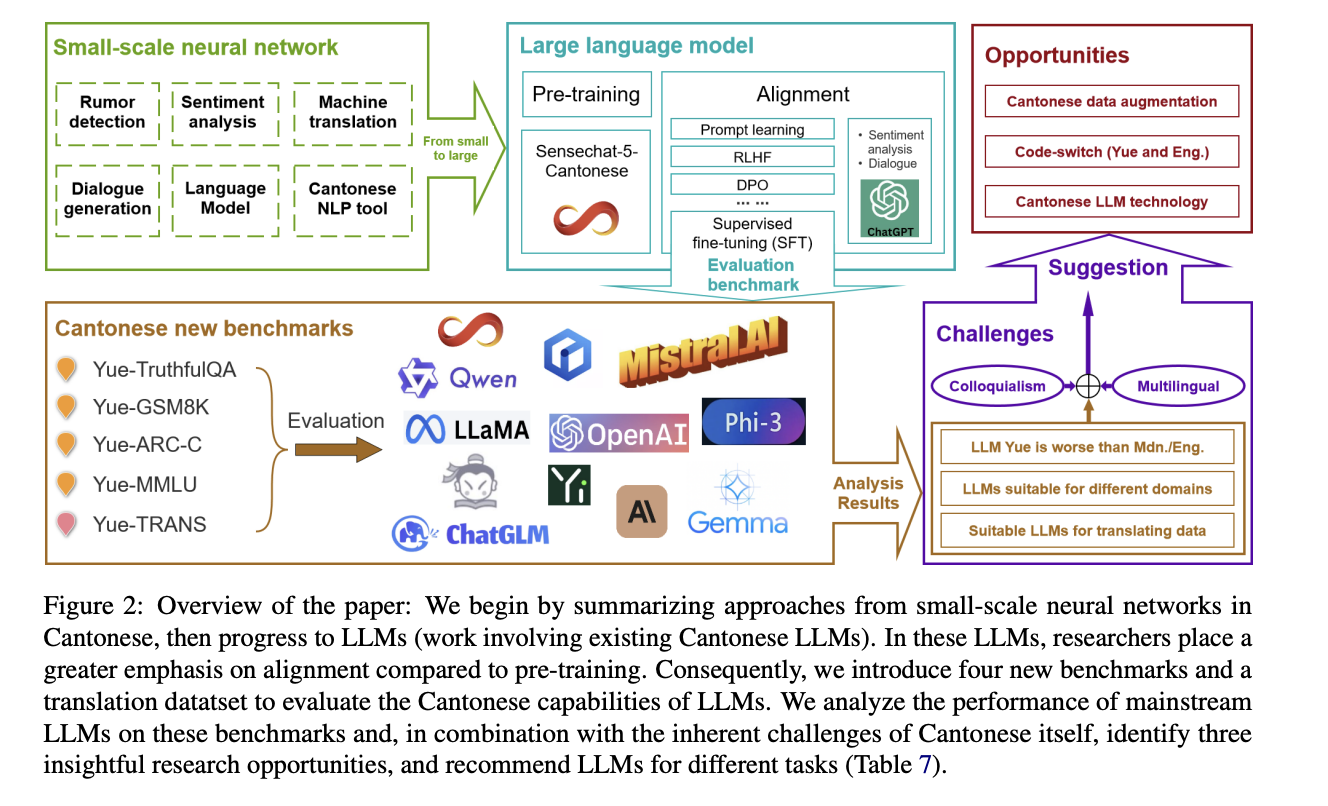
To mitigate the challenges in evaluating Cantonese language fashions, researchers from The Chinese language College of Hong Kong and The College of Hong Kong have developed a complete set of benchmarks particularly designed for Cantonese LLMs. These new analysis instruments embody YueTruthful, Yue-GSM8K, Yue-ARC-C, Yue-MMLU, and Yue-TRANS, which assess numerous facets of language mannequin efficiency in Cantonese. These benchmarks give attention to factual era, mathematical logic, advanced reasoning, normal data, and translation capabilities, respectively. Derived from current English or Mandarin datasets, these Cantonese benchmarks have undergone meticulous translation and guide assessment to make sure accuracy and cultural relevance. Utilizing these newly developed benchmarks, the researchers performed an in depth evaluation of twenty-three mainstream Cantonese and general-purpose LLMs, evaluating their proficiency in Cantonese language duties. Moreover, the examine explored which LLMs are best suited for producing high-quality Cantonese translations, offering beneficial insights for future improvement in Cantonese NLP.
Cantonese small-scale neural community
Cantonese NLP analysis encompasses numerous domains, together with rumor detection, sentiment evaluation, machine translation, and dialogue techniques. For rumor detection, specialised fashions like XGA and CantoneseBERT have been developed, incorporating consideration mechanisms and glyph-pronunciation options. Sentiment evaluation has progressed from fundamental machine studying to superior methods utilizing Hidden Markov Fashions and Transformers. Machine translation has advanced from rule-based techniques to statistical and neural approaches, with current give attention to unsupervised strategies and large-scale datasets. Dialogue summarization and era have seen developments with fine-tuned fashions like BertSum. Language modeling faces challenges on account of information shortage, whereas numerous NLP instruments cater to particular Cantonese processing wants.
Cantonese giant language mannequin
Current advances in Cantonese LLMs present promise regardless of useful resource shortage and language-specific challenges. Alignment methods like prompting, supervised fine-tuning, and reinforcement studying from human suggestions have confirmed efficient for adapting these fashions to downstream duties whereas addressing biases and cultural nuances. Notable purposes embody ChatGPT’s success in Cantonese dialogue and sentiment evaluation, as demonstrated in a Hong Kong internet counseling examine. The CanChat bot exemplifies sensible implementation, providing emotional help to college students through the COVID-19 pandemic. Whereas each general-purpose and closed-source Cantonese LLMs exhibit potential, quantifying their efficiency stays difficult. To handle this, researchers have proposed 4 new benchmarks particularly designed to judge and advance the Cantonese capabilities of huge language fashions.
The event of Cantonese language assets has a wealthy historical past, relationship again to Matteo Ricci’s bilingual dictionary within the sixteenth century. Hong Kong establishments have been instrumental in creating Cantonese corpora, together with legislative information, kids’s dialogues, and media transcriptions. Current efforts give attention to bridging the info hole between Cantonese and main languages, with initiatives like parallel treebanks and complete dictionaries. To handle the dearth of Cantonese-specific LLM analysis instruments, researchers have developed 4 new benchmarks: YueTruthfulQA for factual era, Yue-GSM8K for mathematical logic, Yue-ARC-C for advanced reasoning, and Yue-MMLU for normal data. These datasets, translated from English or Mandarin counterparts, underwent rigorous assessment by trilingual specialists to make sure accuracy and cultural relevance.
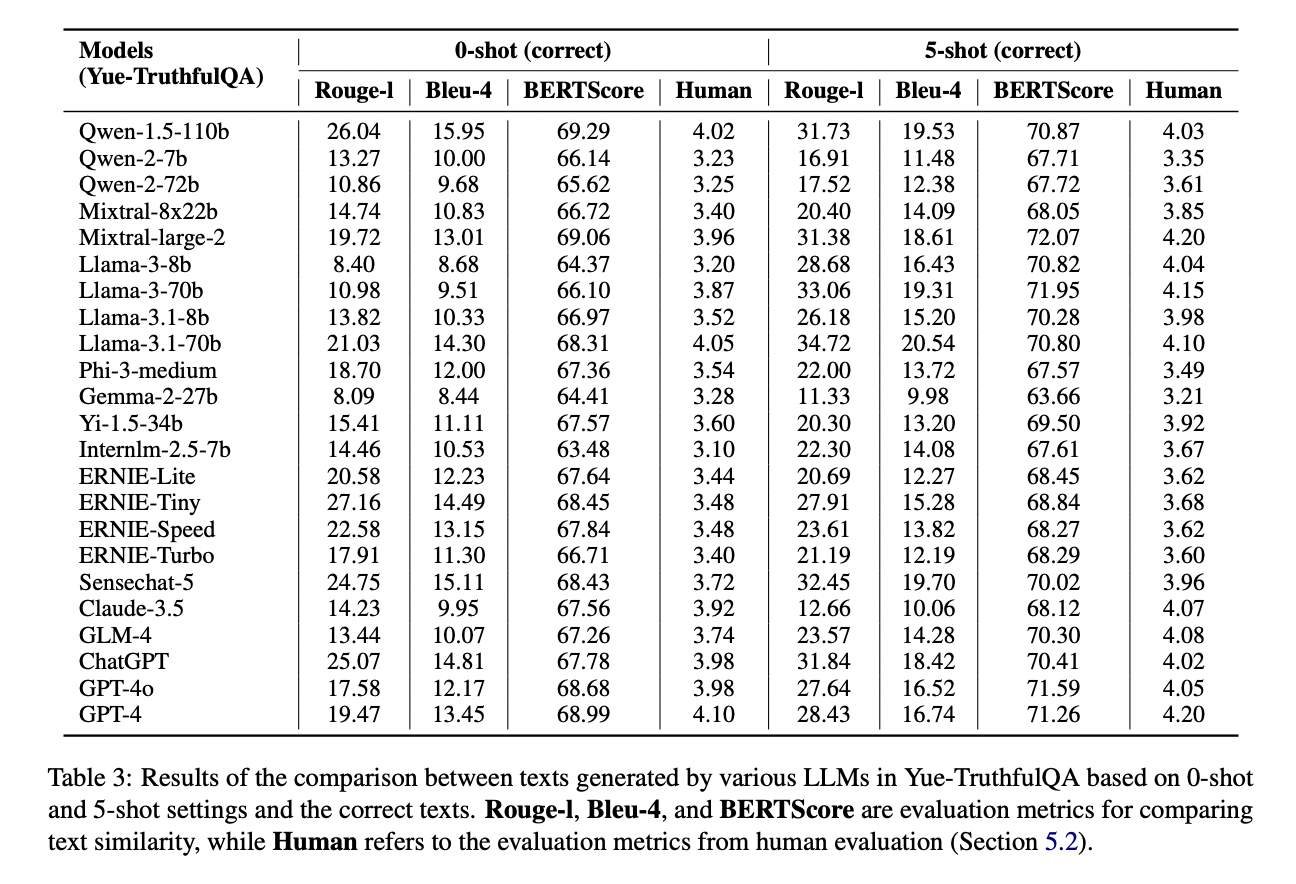
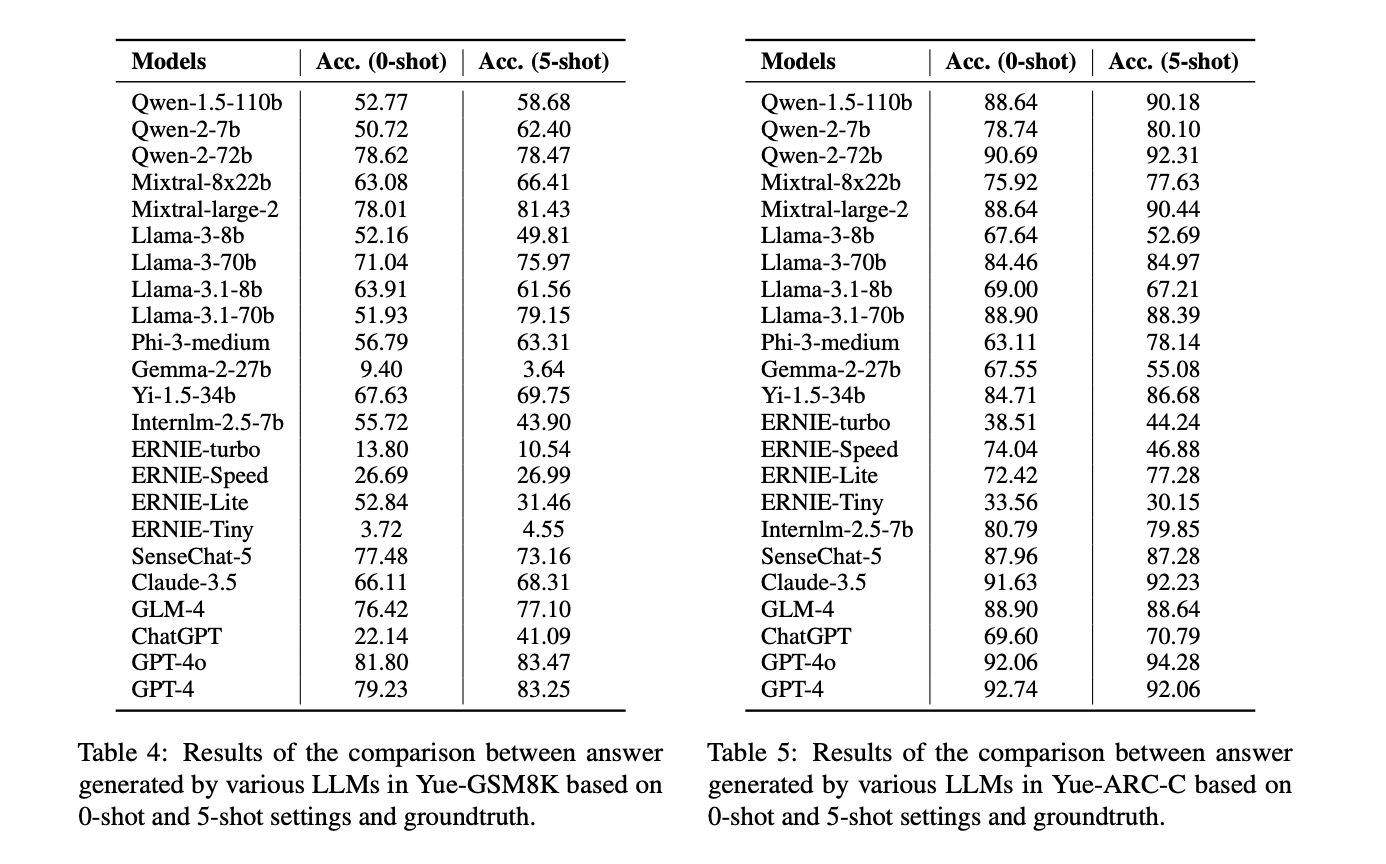
The efficiency of Cantonese LLMs lags behind their Mandarin and English counterparts. Rouge-l and Bleu-4 metrics excel in evaluating key info extraction, whereas BERTScore assesses deep semantic similarities. Typically, 5-shot settings outperform 0-shot, demonstrating the good thing about extra references. Mainstream LLMs persistently carry out higher in English than in Cantonese, highlighting the necessity for extra Cantonese-focused improvement. Totally different mannequin sequence present various strengths throughout duties. Qwen-1.5-110b and Mixtral-large-2 lead in factual era, whereas GPT-4 and GPT-4o excel in mathematical logic. For advanced reasoning, GPT-4 persistently tops efficiency charts, intently adopted by Qwen and Mixtral fashions. Qwen-2-72b reveals the most effective efficiency throughout numerous MMLU matters.
Cantonese NLP faces distinctive challenges on account of its important variations from Commonplace Chinese language, notably in colloquial utilization. The abundance of distinctive expressions, slang, and cultural nuances in Cantonese complicates the variation of Commonplace Chinese language-based fashions. Moreover, the multilingual nature of Cantonese communication, with frequent code-switching between Cantonese, Commonplace Chinese language, and English, poses additional challenges for NLP techniques.
To handle these challenges and advance Cantonese NLP, a number of alternatives emerge. Information augmentation methods, together with label-invariant and label-variant strategies, might help overcome the shortage of Cantonese-specific information. Leveraging high-capability closed-source fashions or cost-effective open-source options for dataset translation and augmentation is really useful. Researchers ought to give attention to creating fashions that may successfully deal with code-switching and multilingual contexts. Primarily based on benchmark performances, fashions from the Qwen, Mixtral, Llama, and Yi sequence are really useful for numerous Cantonese NLP duties, with particular mannequin choice relying on job necessities and accessible assets.
This examine addresses the vital hole in Cantonese NLP analysis, highlighting the language’s underrepresentation regardless of its important international speaker base and financial significance. The researchers from The Chinese language College of Hong Kong and The College of Hong Kong developed sturdy benchmarks (YueTruthful, Yue-GSM8K, Yue-ARC-C, Yue-MMLU, and Yue-TRANS) to judge Cantonese LLMs. These instruments assess factual era, mathematical logic, advanced reasoning, normal data, and translation capabilities. The examine analyzed 23 mainstream LLMs, revealing that Cantonese fashions usually lag behind their English and Mandarin counterparts. Totally different fashions excelled in numerous duties, with Qwen, Mixtral, and GPT sequence exhibiting promising outcomes. The analysis additionally recognized key challenges in Cantonese NLP, together with colloquialisms and code-switching, and proposed alternatives for development by means of information augmentation and specialised mannequin improvement.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and LinkedIn. Be a part of our Telegram Channel.
In the event you like our work, you’ll love our publication..
Don’t Overlook to affix our 50k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


