




¿Son los videojuegos el mejor criterio para evaluar la IA?
Durante años, la evaluación de modelos de IA se ha basado en puntos de referencia como MMLU, Chatbot Arena y SWE-Bench Verified. Pero a medida que la IA evoluciona, incluso expertos como Andrej Karpathy cuestionan si estos métodos siguen siendo válidos.
¿Su última preocupación? Los criterios de evaluación de IA están perdiendo confiabilidad, y la solución para mejores mediciones podría estar en los videojuegos.
Después de todo, la IA tiene una larga historia en los juegos. DeepMind cambió el mundo con su AlphaGo al derrotar a campeones de Go. OpenAI dominó Dota 2, demostrando que la IA puede superar a jugadores humanos en juegos de estrategia. 
Ahora, investigadores del Hao AI Lab de UC San Diego han llevado esto más lejos. Crearon una IA “agente de juegos” de código abierto para probar modelos de lenguaje grandes (LLMs) en juegos de resolución de puzzles en tiempo real, comenzando con Super Mario Bros..
¿Resultados? Claude 3.7 jugó durante 90 segundos completos, superando ampliamente al GPT-4o de OpenAI, que murió casi de inmediato.
Claude 3.7 supera a OpenAI y Google en Super Mario
El proyecto GamingAgent, disponible para descarga de código abierto, permite que los modelos de IA controlen un personaje del juego usando lenguaje natural.
🔹 Claude 3.7 Sonnet duró 90 segundos impresionantes.
🔹 GPT-4o murió en solo 20 segundos, derrotado por el primer enemigo.
🔹 El Gemini 1.5 Pro y Gemini 2.0 de Google tuvieron un rendimiento pobre, luchando con movimientos básicos.
GPT-4o: La IA que no sabe saltar
Imagina un jugador tan malo que muere en segundos. Ese es GPT-4o en Super Mario.
- 💀 Primer intento: Asesinado por el primer enemigo, como un principiante total.

- 💀 Segundo intento: Apenas progresó, deteniéndose cada dos pasos.

- 💀 Tercer intento: Quedó atascado bajo una tubería durante 10 segundos antes de morir.

Gemini 1.5 Pro también falló justo en el primer enemigo. Pero en su segundo intento, mostró cierta mejora: golpeó un bloque de interrogación y agarró un Súper Champiñón.
Sin embargo, desarrolló un hábito extraño: saltar cada dos pasos, fuera necesario o no.
- 🚀 Saltó 9 veces en una corta distancia

- 🚀 Saltó sobre tuberías, el suelo e incluso espacios vacíos

- 🚀 Avanzó más que GPT-4o pero aún cayó en un precipicio

Gemini 2.0 Flash fue ligeramente mejor, saltando con más fluidez y alcanzando una plataforma más alta. Pero aún así no logró escapar de un precipicio cerca de la cuarta tubería, terminando su partida.
Claude 3.7: ¿El prodigio de Super Mario?
A diferencia de los modelos de OpenAI y Google, Claude 3.7 jugó como un verdadero gamer.
- ✔ Solo saltaba cuando era necesario (para evitar obstáculos o vacíos)

- ✔ Esquivó enemigos con saltos precisos
¿Puede la IA dominar juegos más complejos?
Mario no es la única prueba. Los investigadores también evaluaron modelos de IA en Tetris y 2048, dos juegos de rompecabezas clásicos que requieren toma de decisiones estratégicas.
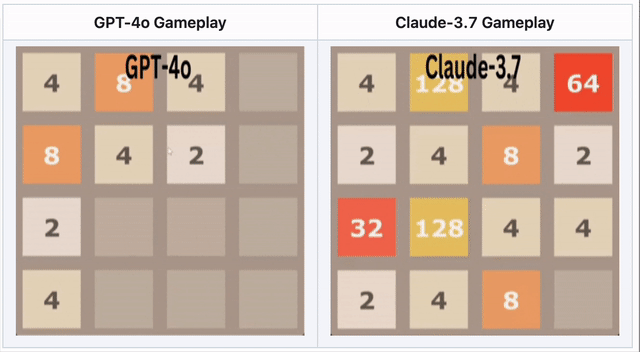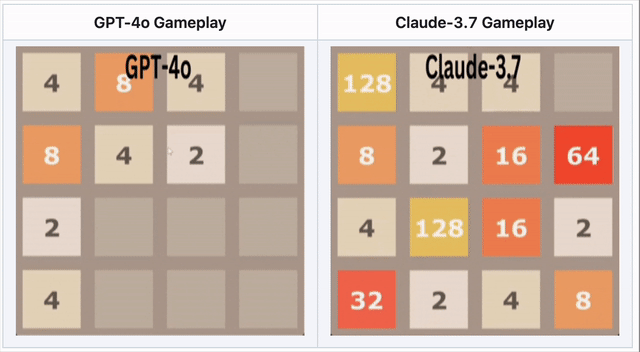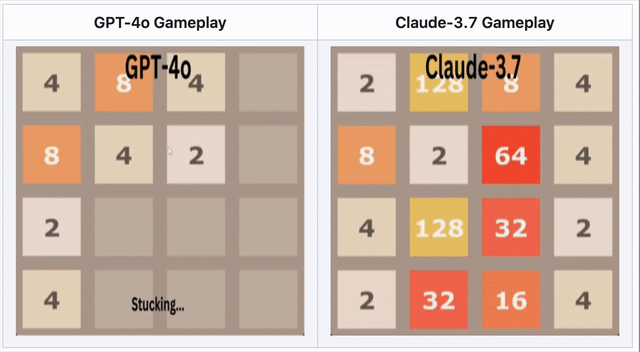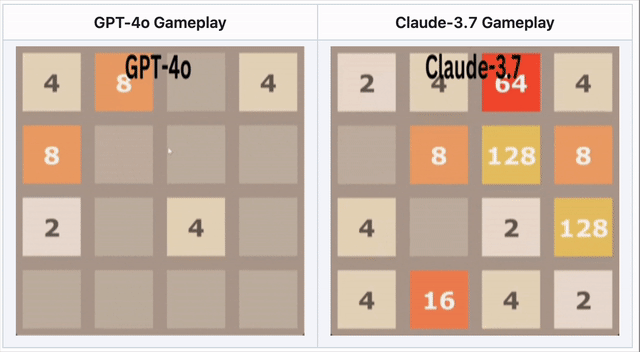
GPT-4o falla en 2048 – Claude 3.7 tiene mejor desempeño
En el rompecabezas numérico 2048, la IA necesitaba deslizar fichas y realizar movimientos estratégicos.
🔹 GPT-4o falló temprano, sobreanalizando movimientos.
🔹 Claude 3.7 duró más tiempo, fusionando fichas de manera más inteligente.
🔹 Ningún modelo ganó, pero Claude superó a GPT-4o.
El rendimiento de Claude 3.7 en Tetris impresiona a los expertos
Cuando se probó en Tetris, Claude 3.7 mostró:
✔ Estrategia decente para apilar piezas
✔ Eliminación adecuada de líneas
✔ Supervivencia más prolongada que otros modelos de IA
Alex Albert de Anthropic elogió el experimento, diciendo:
“¡Deberíamos convertir cada videojuego en un punto de referencia para la IA!”
¿Son los juegos el futuro de la evaluación de IA?
Los resultados sugieren que los videojuegos podrían ser el próximo gran punto de referencia para la IA. A diferencia de las pruebas tradicionales, los juegos requieren toma de decisiones en tiempo real, adaptabilidad y habilidades motoras.
Con los modelos de IA avanzando rápidamente, los puntos de referencia estáticos pueden dejar de ser suficientes para juzgar la verdadera inteligencia. Si los juegos demuestran ser una mejor medida, podríamos ver modelos de IA entrenando con aprendizaje por refuerzo en miles de juegos antes de su implementación.
Reflexiones finales: Claude gana esta ronda, ¿pero qué sigue?
El juego superior de Claude 3.7 sugiere un razonamiento y adaptabilidad más fuertes en comparación con GPT-4o y Gemini. Pero a medida que evoluciona la IA, ¿qué modelo será el primero en completar un juego completo como un humano?
Con agentes de juego de código abierto disponibles, espera más batallas de IA vs videojuegos pronto. ¿Quién sabe? Tal vez algún día la IA complete Super Mario sin errores, o incluso venza a jugadores humanos de esports.
Hasta entonces, Claude sigue siendo el rey de los juegos de IA, ¡mientras GPT-4o necesita mucha práctica!









