


A serious problem within the present deployment of Giant Language Fashions (LLMs) is their lack of ability to effectively handle duties that require each era and retrieval of knowledge. Whereas LLMs excel at producing coherent and contextually related textual content, they battle to deal with retrieval duties, which contain fetching related paperwork or knowledge earlier than producing a response. This inefficiency turns into significantly pronounced in duties like question-answering, multi-hop reasoning, and entity linking, the place real-time, correct retrieval is crucial for producing significant outputs. The problem lies in the truth that these fashions sometimes deal with era and retrieval as separate processes, which will increase computational complexity, inference time, and the chance of error, particularly in multi-turn dialogues or complicated reasoning situations.
To deal with this problem, earlier approaches like Retrieval-Augmented Technology (RAG) have tried to combine retrieval into the generative course of by retrieving related knowledge after which passing it to a separate mannequin for era. Whereas this two-step course of allows fashions to generate responses primarily based on exterior data, it introduces vital limitations. First, it requires separate fashions for retrieval and era, resulting in elevated computational overhead and inefficiency. Second, the 2 fashions work in distinct representational areas, which limits their skill to work together fluidly and necessitates further ahead passes, additional slowing down the method. In multi-turn conversations or complicated queries, this separation additionally calls for question rewriting, which may propagate errors and improve the general complexity of the duty. These limitations make current strategies unsuitable for real-time functions requiring each retrieval and era.
Researchers from Zhejiang College introduce OneGen, a novel resolution that unifies the retrieval and era processes right into a single ahead go inside an LLM. By integrating autoregressive retrieval tokens into the mannequin, OneGen allows the system to deal with each duties concurrently with out the necessity for a number of ahead passes or separate retrieval and era fashions. This revolutionary strategy considerably reduces computational overhead and inference time, enhancing the effectivity of LLMs. OneGen’s key contribution is its skill to make use of particular retrieval tokens generated throughout the identical ahead go used for textual content era, guaranteeing that retrieval doesn’t compromise the mannequin’s generative efficiency. This unified strategy is a considerable enchancment over earlier strategies, offering a streamlined, environment friendly resolution for duties that require each retrieval and era.
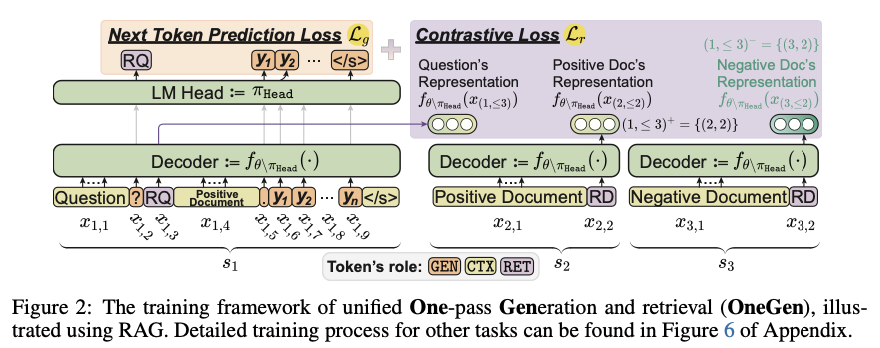
The technical basis of OneGen entails augmenting the usual LLM vocabulary with retrieval tokens. These tokens are generated throughout the autoregressive course of and are used to retrieve related paperwork or info with out requiring a separate retrieval mannequin. The retrieval tokens are fine-tuned utilizing contrastive studying throughout coaching, whereas the remainder of the mannequin continues to be educated utilizing commonplace language mannequin aims. This strategy ensures that each retrieval and era processes happen seamlessly in the identical ahead go. OneGen has been evaluated on a number of datasets, together with HotpotQA and TriviaQA for question-answering duties, in addition to Wikipedia-based datasets for entity linking. These datasets, that are commonplace benchmarks within the area, assist exhibit the flexibility and effectivity of OneGen throughout completely different NLP duties.
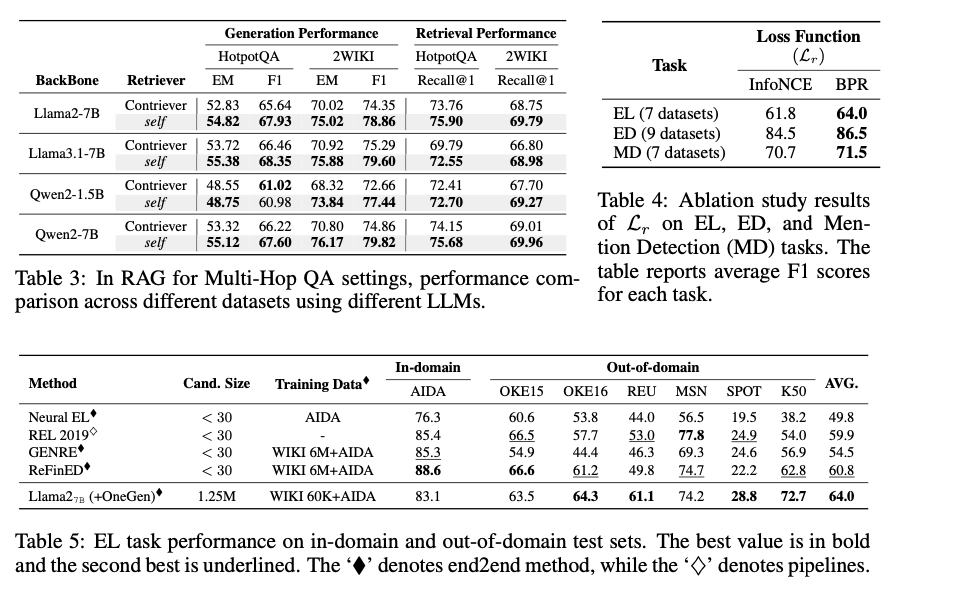
OneGen demonstrated superior efficiency in numerous duties requiring each retrieval and era when in comparison with current fashions like Self-RAG and GRIT. It achieved notable enhancements in accuracy and F1 scores, significantly in multi-hop question-answering and entity-linking duties. As an example, OneGen confirmed a 3.2-point enchancment in accuracy throughout six entity-linking datasets and a 3.3-point improve in F1 scores on multi-hop QA duties. Moreover, it maintained environment friendly efficiency in retrieval duties whereas enhancing the generative capabilities of the mannequin. These outcomes spotlight the framework’s skill to streamline each retrieval and era processes, leading to sooner and extra correct responses with out sacrificing the standard of both job.
In conclusion, OneGen introduces an environment friendly, one-pass resolution to the problem of integrating retrieval and era inside LLMs. By leveraging retrieval tokens and using contrastive studying, it overcomes the inefficiencies and complexities of earlier strategies that separated these duties into distinct fashions. This unified framework enhances each the pace and accuracy of LLMs in duties that require real-time era primarily based on retrieved info. With demonstrated enhancements in efficiency throughout a number of benchmarks, OneGen has the potential to revolutionize the way in which LLMs deal with complicated duties involving each retrieval and era, making them extra relevant to real-world, high-speed, and high-accuracy functions.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Overlook to affix our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s captivated with knowledge science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


