

 Unveiled: A Revolutionary OCR-2.0 Mannequin That Streamlines Textual content Recognition Throughout A number of Codecs with Unmatched Effectivity and Precision")
Optical Character Recognition (OCR) expertise has been important in digitizing and extracting information from textual content pictures. Through the years, OCR techniques have advanced from easy strategies that might acknowledge primary textual content to extra complicated techniques able to decoding varied characters. Conventional OCR techniques, known as OCR-1.0, use modular architectures to course of pictures by detecting, cropping, and recognizing textual content. Whereas these early techniques served their goal in sure areas, the rising demand for extra clever textual content processing has uncovered their limitations. OCR-1.0 techniques, as an illustration, are sometimes designed with particular duties in thoughts, which implies a number of fashions are wanted to deal with completely different OCR necessities, growing complexity and upkeep prices.
One of many primary challenges within the OCR discipline has been the inefficiency and wish for extra versatility of those conventional techniques. OCR-1.0 fashions have excessive upkeep calls for and wrestle to generalize throughout completely different textual content sorts and codecs, reminiscent of handwritten textual content, mathematical equations, or musical notation. Every activity normally requires completely different OCR fashions to carry out particular sub-tasks, which makes it troublesome for customers to seek out the best device for a selected want. Present techniques typically require the combination of a number of fashions, which might result in errors between the completely different processing steps. This fragmentation has led researchers to hunt a extra unified strategy to OCR.
Current advances in Massive Imaginative and prescient-Language Fashions (LVLMs) have demonstrated spectacular textual content recognition capabilities. For instance, fashions like CLIP and LLaVA have proven that vision-language alignment can be utilized for OCR duties. Nonetheless, these fashions primarily deal with visible reasoning duties and will not be optimized for OCR-specific features, particularly when dealing with dense textual content or a number of languages. The big parameter sizes of those fashions, typically exceeding billions of parameters, require important computational assets for coaching and deployment. Furthermore, present LVLMs want increased deployment prices, which makes them impractical for wide-scale adoption in OCR duties, notably in situations that contain high-density textual content or specialised optical characters like geometric shapes or musical scores.
Researchers from StepFun, Megvii Know-how, the College of Chinese language Academy of Sciences, and Tsinghua College launched a brand new OCR mannequin known as GOT (General OCR Theory). This mannequin is a key part of what the researchers describe as OCR-2.0, a next-generation strategy to textual content recognition. GOT is designed to unify and simplify OCR duties right into a single, end-to-end answer. Not like its predecessors, GOT goals to sort out all OCR necessities inside one framework, providing a extra versatile and environment friendly system. The mannequin can acknowledge numerous textual content codecs, together with plain textual content, complicated formulation, charts, and even geometric shapes. It has been designed to deal with scene textual content and document-style pictures, making it relevant throughout varied use instances.
The GOT mannequin structure includes a high-compression encoder and a long-context decoder with 580 million parameters. The encoder compresses enter pictures, whether or not small slices or full-page scans, into 256 tokens of 1,024 dimensions every, whereas the decoder, outfitted with 8,000 maximum-length tokens, generates the corresponding OCR output. This mixture permits GOT to course of giant and sophisticated pictures effectively and precisely. One of many standout options of the mannequin is its potential to generate formatted outputs in Markdown or LaTeX, which is especially helpful for processing scientific papers and mathematical content material. The mannequin helps interactive OCR, enabling region-based recognition the place customers can specify areas of curiosity by way of coordinates or colours.
GOT delivers spectacular efficiency throughout varied OCR duties. In experiments, the mannequin outperformed competing fashions reminiscent of UReader and LLaVA-NeXT. For instance, GOT achieved an F1-score of 0.952 for English document-level OCR, outperforming fashions with billions of parameters whereas utilizing solely 580 million parameters. Equally, the Chinese language document-level OCR recorded an F1 rating of 0.961. In scene-text OCR duties, GOT demonstrated exceptional precision and recall, reaching precision charges of 0.926 for English and 0.934 for Chinese language, displaying broad applicability throughout languages. The mannequin’s potential to acknowledge complicated characters, reminiscent of these present in sheet music or geometric shapes, was additionally notable, with the system performing nicely on duties that concerned rendering mathematical and molecular formulation.
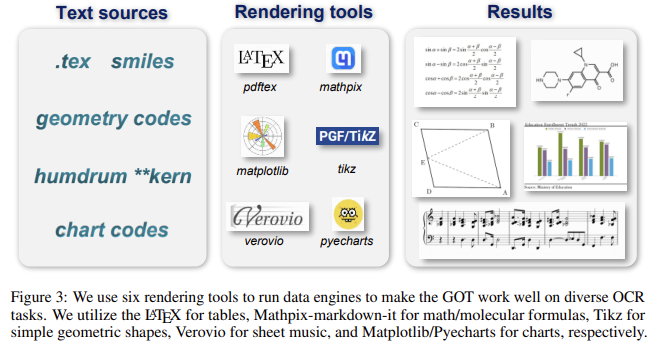
The researchers additionally included dynamic decision methods and multi-page OCR expertise into the GOT mannequin, making it extra sensible for real-world functions the place high-resolution pictures or multi-page paperwork are widespread. Utilizing a sliding window strategy, the mannequin can course of extreme-resolution pictures, like horizontally stitched two-page paperwork, with out shedding accuracy. The coaching of GOT was performed in three levels: pre-training the imaginative and prescient encoder with 80 million parameters, joint coaching with the 580-million-parameter decoder, and post-training to reinforce its generalization talents additional. All through these levels, the mannequin was educated on varied datasets, together with 5 million image-text pairs, to make sure it may deal with numerous OCR duties. These datasets included textual content from English and Chinese language sources and artificial information representing mathematical formulation, tables, and extra.

In conclusion, GOT, addressing the restrictions of conventional OCR-1.0 fashions and the inefficiencies of present LVLM-based OCR strategies, GOT introduces a unified, end-to-end system able to dealing with a wide selection of OCR duties with excessive accuracy and decrease computational prices. Its structure, constructed on the Basic OCR Idea, permits it to effectively course of varied textual content codecs, from easy plain textual content to extra complicated optical characters like geometric shapes and molecular formulation. This mannequin’s efficiency throughout completely different duties, together with scene-text and doc OCR, demonstrates its potential to redefine the usual for OCR expertise. Dynamic decision and multi-page OCR capabilities additional improve its practicality in real-world functions.
Try the Paper, Mannequin, and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


