


Early makes an attempt in 3D technology centered on single-view reconstruction utilizing category-specific fashions. Current developments make the most of pre-trained picture and video turbines, significantly diffusion fashions, to allow open-domain technology. Positive-tuning on multi-view datasets improved outcomes, however challenges endured in producing complicated compositions and interactions. Efforts to boost compositionality in picture generative fashions confronted difficulties in transferring methods to 3D technology. Some strategies prolonged distillation approaches to compositional 3D technology, optimizing particular person objects and spatial relationships whereas adhering to bodily constraints.
Human-object interplay synthesis has progressed with strategies like InterFusion, which generates interactions primarily based on textual prompts. Nonetheless, limitations in controlling human and object identities persist. Many approaches battle to protect human mesh id and construction throughout interplay technology. These challenges spotlight the necessity for simpler methods that enable larger person management and sensible integration into digital atmosphere manufacturing pipelines. This paper builds upon earlier efforts to handle these limitations and improve the technology of human-object interactions in 3D environments.
Researchers from the College of Oxford and Carnegie Mellon College launched a zero-shot methodology for synthesizing 3D human-object interactions utilizing textual descriptions. The method leverages text-to-image diffusion fashions to handle challenges arising from various object geometries and restricted datasets. It optimizes human mesh articulation utilizing Rating Distillation Sampling gradients from these fashions. The strategy employs a twin implicit-explicit illustration, combining neural radiance fields with skeleton-driven mesh articulation to protect character id. This modern method bypasses in depth information assortment, enabling real looking HOI technology for a variety of objects and interactions, thereby advancing the sector of 3D interplay synthesis.
DreamHOI employs a twin implicit-explicit illustration, combining neural radiance fields (NeRFs) with skeleton-driven mesh articulation. This method optimizes skinned human mesh articulation whereas preserving character id. The strategy makes use of Rating Distillation Sampling to acquire gradients from pre-trained text-to-image diffusion fashions, guiding the optimization course of. The optimization alternates between implicit and express varieties, refining mesh articulation parameters to align with textual descriptions. Rendering the skinned mesh alongside the item mesh permits for direct optimization of express pose parameters, enhancing effectivity as a result of diminished variety of parameters.
In depth experimentation validates DreamHOI’s effectiveness. Ablation research assess the influence of assorted parts, together with regularizers and rendering methods. Qualitative and quantitative evaluations display the mannequin’s efficiency in comparison with baselines. Various immediate testing showcases the tactic’s versatility in producing high-quality interactions throughout totally different eventualities. The implementation of a steerage combination method additional enhances optimization coherence. This complete methodology and rigorous testing set up DreamHOI as a sturdy method for producing real looking and contextually applicable human-object interactions in 3D environments.
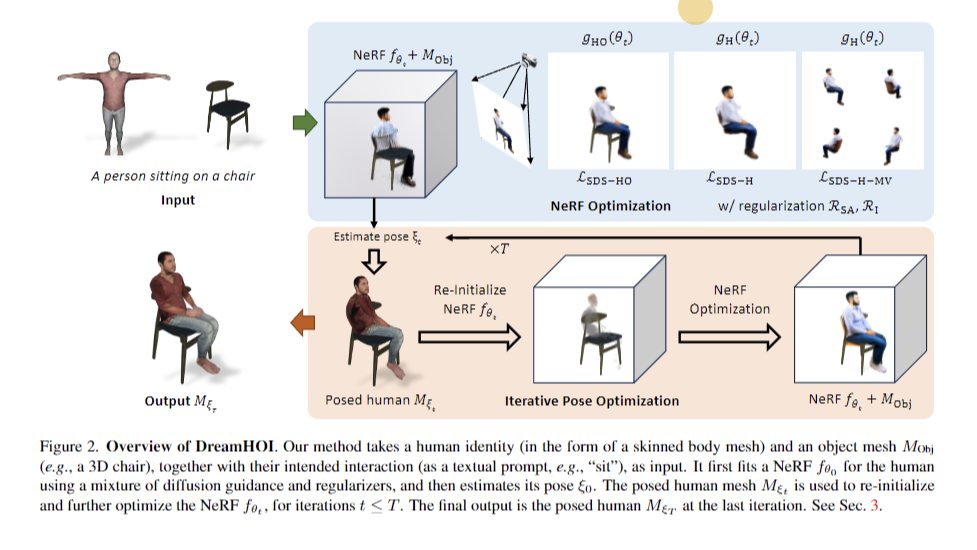
DreamHOI excels in producing 3D human-object interactions from textual prompts, outperforming baselines with greater CLIP similarity scores. Its twin implicit-explicit illustration combines NeRFs and skeleton-driven mesh articulation, enabling versatile pose optimization whereas preserving character id. The 2-stage optimization course of, together with 5000 steps of NeRF refinement, contributes to high-quality outcomes. Regularizers play an important function in sustaining correct mannequin measurement and alignment. A regressor facilitates transitions between NeRF and skinned mesh representations. DreamHOI overcomes the constraints of strategies like DreamFusion in sustaining mesh id and construction. This method exhibits promise for functions in movie and recreation manufacturing, simplifying the creation of real looking digital environments with interacting people.
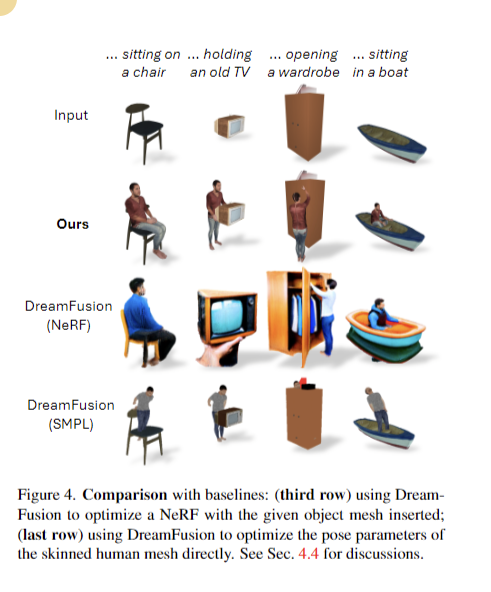
In conclusion, DreamHOI introduces a novel method for producing real looking 3D human-object interactions utilizing textual prompts. The strategy employs a twin implicit-explicit illustration, combining NeRFs with express pose parameters of skinned meshes. This method, together with Rating Distillation Sampling, optimizes pose parameters successfully. Experimental outcomes display DreamHOI’s superior efficiency in comparison with baseline strategies, with ablation research confirming the significance of every element. The paper addresses challenges in direct optimization of pose parameters and highlights DreamHOI’s potential to simplify digital atmosphere creation. This development opens up new potentialities for functions within the leisure business and past.
Try the Paper and Challenge Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit

Shoaib Nazir is a consulting intern at MarktechPost and has accomplished his M.Tech twin diploma from the Indian Institute of Expertise (IIT), Kharagpur. With a robust ardour for Knowledge Science, he’s significantly within the various functions of synthetic intelligence throughout numerous domains. Shoaib is pushed by a need to discover the newest technological developments and their sensible implications in on a regular basis life. His enthusiasm for innovation and real-world problem-solving fuels his steady studying and contribution to the sector of AI


