


Transformer fashions have revolutionized sequence modeling duties, however their commonplace consideration mechanism faces vital challenges when coping with lengthy sequences. The quadratic complexity of softmax-based commonplace consideration hinders the environment friendly processing of in depth information in fields like video understanding and organic sequence modeling. Whereas this isn’t a serious concern for language modeling throughout coaching, it turns into problematic throughout inference. The Key-Worth (KV) cache grows linearly with technology size, inflicting substantial reminiscence burdens and throughput bottlenecks because of excessive I/O prices. These limitations have spurred researchers to discover different consideration mechanisms that may preserve efficiency whereas enhancing effectivity, significantly for long-sequence duties and through inference.
Linear consideration and its gated variants have emerged as promising alternate options to softmax consideration, demonstrating sturdy efficiency in language modeling and understanding duties. These fashions will be reframed as RNNs throughout inference, reaching fixed reminiscence complexity and considerably enhancing effectivity. Nevertheless, they face two key challenges. First, linear recurrent fashions battle with duties requiring in-context retrieval or studying, going through a elementary recall-memory trade-off. Second, coaching these fashions from scratch on trillions of tokens stays prohibitively costly, regardless of supporting hardware-efficient chunkwise coaching.
On this examine, researchers from the Faculty of Pc Science and Expertise, Soochow College, Massachusetts Institute of Expertise, College of California, Tencent AI Lab, LuxiTech, and College of Waterloo revisit the Consideration with the Bounded-Reminiscence Management (ABC) mannequin, which retains the softmax operation, decreasing discrepancies between commonplace and linear consideration in training-finetuning situations. ABC allows simpler state utilization, requiring smaller state sizes for comparable efficiency. Nevertheless, its potential has been neglected because of mediocre language modeling efficiency and sluggish coaching velocity. To handle these limitations, the researchers reformulate ABC as two-pass linear consideration linked through softmax, using hardware-efficient chunkwise implementation for quicker coaching.
Constructing on this basis, they introduce Gated Slot Consideration (GSA), a gated model of ABC that follows the pattern of enhancing linear consideration with gating mechanisms. GSA not solely matches efficiency in language modeling and understanding duties but in addition considerably outperforms different linear fashions in in-context recall-intensive duties with out requiring massive state sizes. Within the T2R finetuning setting, GSA demonstrates superior efficiency when finetuning Mistral-7B, surpassing massive recurrent language fashions and outperforming different linear fashions and T2R strategies. Notably, GSA achieves comparable coaching speeds to GLA whereas providing improved inference velocity because of its smaller state dimension.
GSA addresses two key limitations of the ABC mannequin: the dearth of a forgetting mechanism and an unwarranted inductive bias favouring preliminary tokens. GSA incorporates a gating mechanism that allows forgetting of historic info and introduces a recency inductive bias, essential for pure language processing.
The core of GSA is a gated RNN replace rule for every reminiscence slot, utilizing a scalar data-dependent gating worth. This may be represented in matrix kind, harking back to HGRN2. GSA will be carried out as a two-pass Gated Linear Consideration (GLA), permitting for hardware-efficient chunkwise coaching.
The GSA structure consists of L blocks, every comprising a GSA token mixing layer and a Gated Linear Unit (GLU) channel mixing layer. It employs multi-head consideration to seize totally different enter facets. For every head, the enter undergoes linear transformations with Swish activation. A neglect gate is obtained utilizing a linear transformation adopted by a sigmoid activation with a damping issue. The outputs are then processed by way of the GSA layer and mixed to supply the ultimate output. The mannequin balances effectivity and effectiveness by rigorously controlling parameter counts, usually setting the variety of reminiscence slots to 64 and utilizing 4 consideration heads.
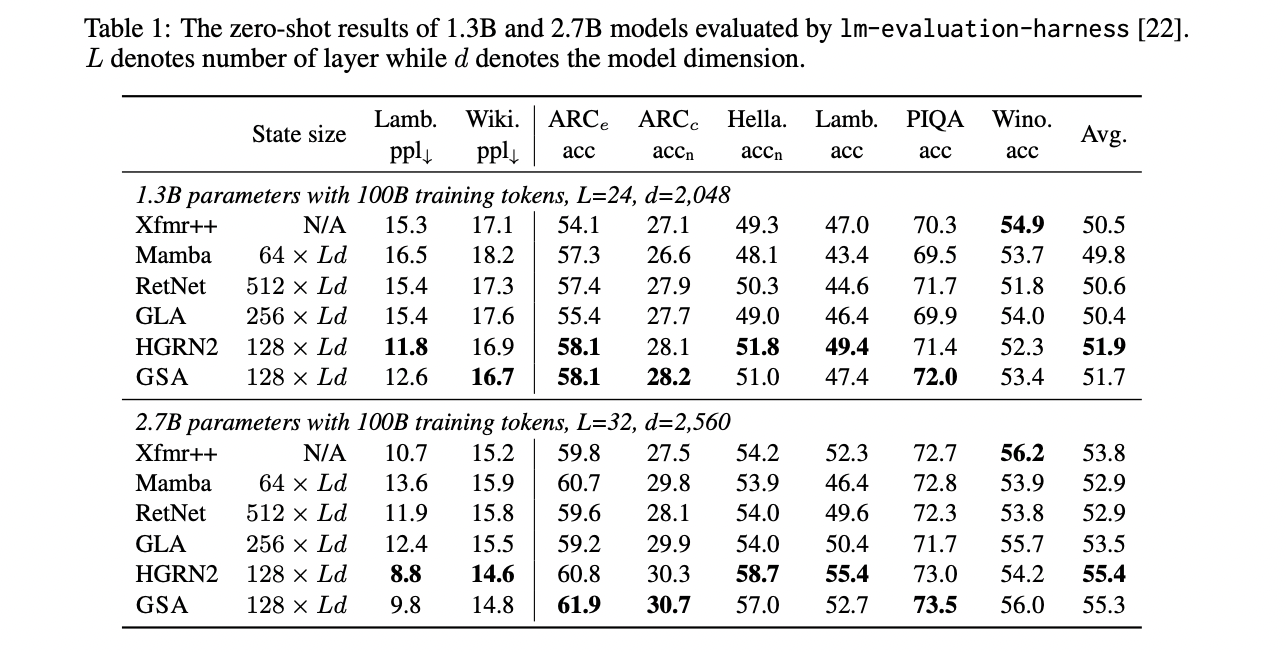
GSA demonstrates aggressive efficiency in each language modeling and in-context recall-intensive duties. In language modeling experiments on the Slimpajama corpus, GSA performs comparably to sturdy fashions like HGRN2 with equally sized hidden states, whereas outperforming GLA and RetNet even with smaller state sizes. For 1.3B and a couple of.7B parameter fashions, GSA achieves comparable or higher outcomes throughout varied commonsense reasoning duties, together with ARC, Hellaswag, Lambada, PIQA, and Winograde.
In recall-intensive duties, GSA exhibits vital enhancements over different subquadratic fashions. On the artificial Multi-Question Associative Recall (MQAR) process, GSA outperforms Mamba, GLA, RetNet, and HGRN2 throughout totally different mannequin dimensions. For real-world recall-intensive duties like FDA, SWDE, SQuAD, NQ, TriviaQA, and Drop, GSA constantly outperforms different subquadratic fashions, reaching a mean efficiency closest to the Transformer (Xfmr++) baseline.

This examine presents GSA that enhances the ABC mannequin with a gating mechanism impressed by Gated Linear Consideration. By framing GSA as a two-pass GLA, it makes use of hardware-efficient implementations for environment friendly coaching. GSA’s context-aware reminiscence studying and forgetting mechanisms implicitly enhance mannequin capability whereas sustaining a small state dimension, enhancing each coaching and inference effectivity. Intensive experiments exhibit GSA’s benefits in in-context recall-intensive duties and “finetuning pre-trained Transformers to RNNs” situations. This innovation bridges the hole between linear consideration fashions and conventional Transformers, providing a promising course for environment friendly, high-performance language modeling and understanding duties.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


