


Collaborative Multi-Agent Reinforcement Studying (MARL) has emerged as a strong method in varied domains, together with site visitors sign management, swarm robotics, and sensor networks. Nevertheless, MARL faces vital challenges as a result of complicated interactions between brokers, which introduce non-stationarity within the setting. This non-stationarity complicates the educational course of and makes it tough for brokers to adapt to altering circumstances. Along with that, because the variety of brokers will increase, scalability turns into a vital concern, requiring environment friendly strategies to deal with large-scale multi-agent techniques. Researchers are thus centered on growing methods that may overcome these challenges whereas enabling efficient collaboration amongst brokers in dynamic and complicated environments.
Prior makes an attempt to beat MARL challenges have predominantly centered on two essential classes: policy-based and value-based strategies. Coverage gradient approaches like MADDPG, COMA, MAAC, MAPPO, FACMAC, and HAPPO have explored optimizing multi-agent coverage gradients. Worth-based strategies like VDN and QMIX have focused on factorizing international worth features to enhance scalability and efficiency.
Lately, analysis on multi-agent communication strategies has made vital strides. One class of approaches goals to restrict message transmission throughout the community, utilizing native gating mechanisms to dynamically trim communication hyperlinks. One other class focuses on environment friendly studying to create significant messages or extract invaluable info. These strategies have employed varied methods, together with consideration mechanisms, graph neural networks, teammate modeling, and personalised message encoding and decoding schemes.
Nevertheless, these approaches nonetheless face challenges balancing communication effectivity, scalability, and efficiency in complicated multi-agent environments. Points reminiscent of communication overhead, restricted expressive energy of discrete messages, and the necessity for extra refined message aggregation schemes stay areas of energetic analysis and enchancment.
On this paper, researchers current DCMAC (Demand-aware Custom-made Multi-Agent Communication), a sturdy protocol designed to optimize using restricted communication sources, cut back coaching uncertainty, and improve agent collaboration in multi-agent reinforcement studying techniques. This state-of-the-art technique introduces a singular method the place brokers initially broadcast concise messages utilizing minimal communication sources. These messages are then parsed to grasp teammate calls for, permitting brokers to generate custom-made messages that affect their teammates’ Q-values based mostly on native info and perceived wants.
DCMAC incorporates an progressive coaching paradigm based mostly on the higher sure of most return, alternating between Prepare Mode and Take a look at Mode. In Prepare Mode, a really perfect coverage is skilled utilizing joint observations to function a steerage mannequin, serving to the goal coverage converge extra effectively. Take a look at Mode employs a requirement loss operate and temporal distinction error to replace the demand parsing and customised message technology modules.
This method goals to facilitate environment friendly communication inside constrained sources, addressing key challenges in multi-agent techniques. DCMAC’s effectiveness is demonstrated by experiments in varied environments, showcasing its potential to realize efficiency corresponding to unrestricted communication algorithms whereas excelling in situations with communication limitations.
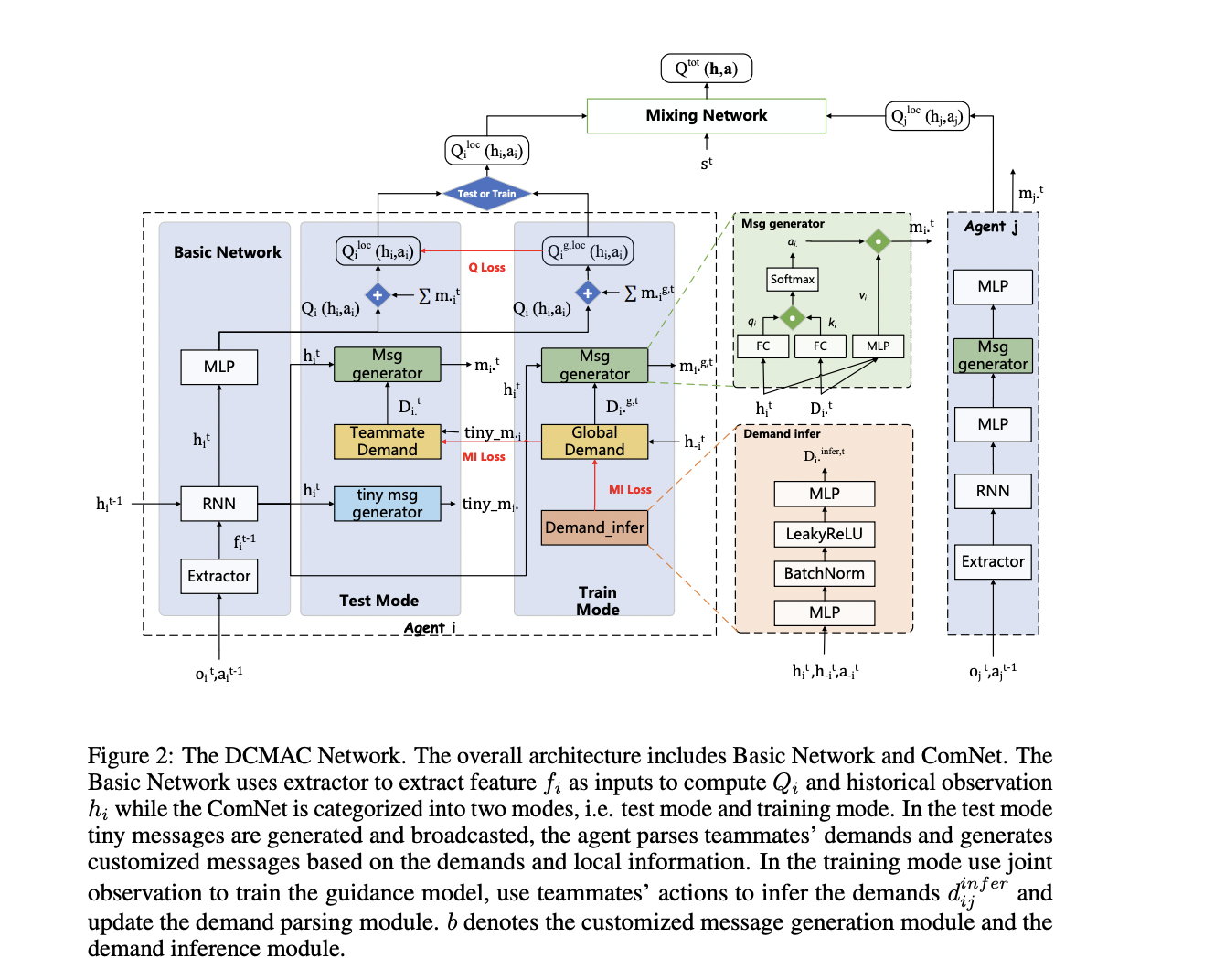
DCMAC’s structure consists of three essential modules: tiny message technology, teammate demand parsing, and customised message technology. The method begins with brokers extracting options from observations utilizing a self-attention mechanism to attenuate redundant info. These options are then processed by a GRU module to acquire historic observations.
The tiny message technology module creates low-dimensional messages based mostly on historic observations, that are periodically broadcast. The demand parsing module interprets these tiny messages to grasp teammate calls for. The custom-made message technology module then produces messages tailor-made to bias the Q-values of different brokers, based mostly on parsed calls for and historic observations.
To optimize communication sources, DCMAC employs a link-pruning operate that makes use of cross-attention to calculate correlations between brokers. Messages are despatched solely to essentially the most related brokers based mostly on communication constraints.
DCMAC introduces a most return higher sure coaching paradigm, which makes use of a really perfect coverage skilled on joint observations as a steerage mannequin. This method features a international demand module and a requirement infer module to duplicate the consequences of world statement throughout coaching. The coaching course of alternates between Prepare Mode and Take a look at Mode, utilizing mutual info and TD error to replace varied modules.
DCMAC’s efficiency was evaluated in three well-known multi-agent collaborative environments: Hallway, Degree-Primarily based Foraging (LBF), and StarCraft II Multi-Agent Problem (SMAC). The outcomes had been in contrast with baseline algorithms reminiscent of MAIC, NDQ, QMIX, and QPLEX.

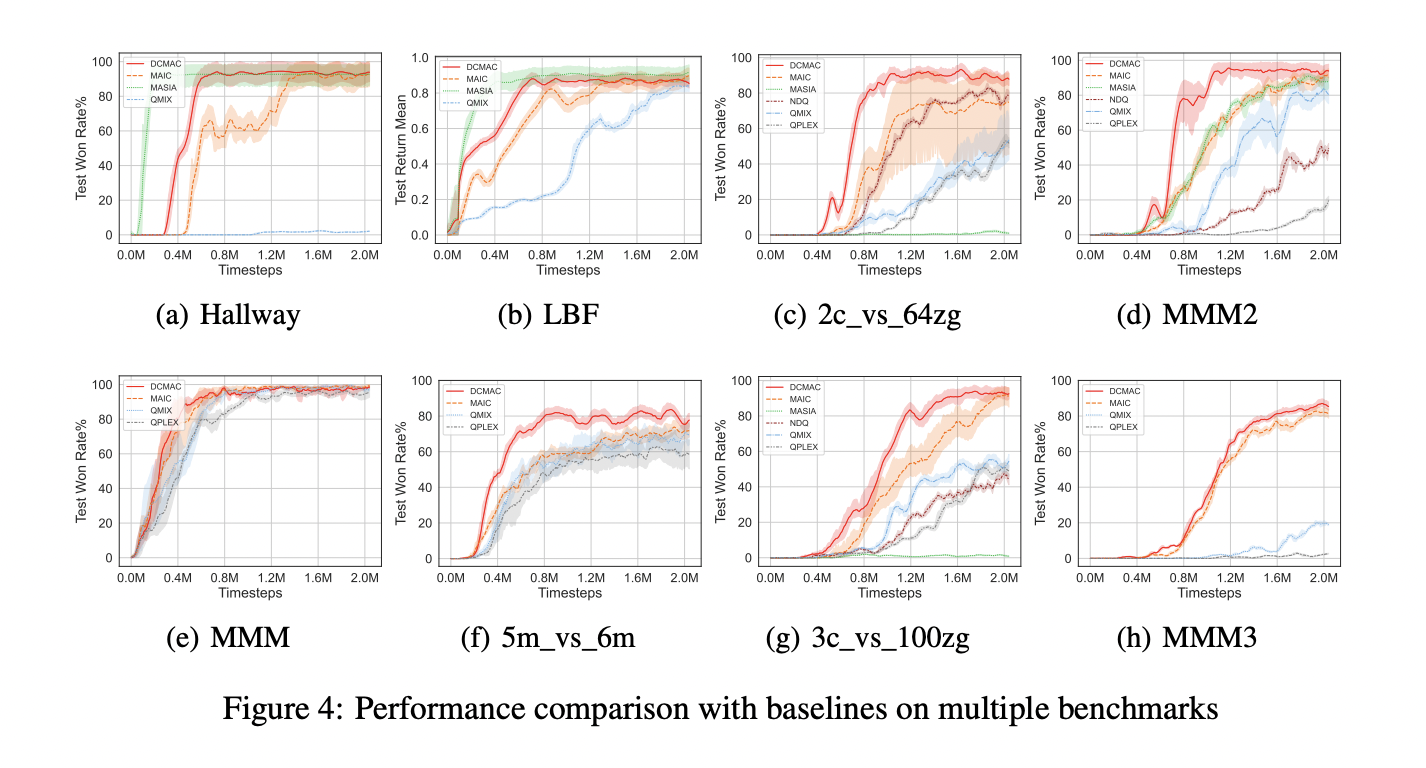
In communication efficiency assessments, DCMAC confirmed superior leads to situations with massive statement areas, reminiscent of SMAC. Whereas it carried out barely behind MASIA in smaller statement area environments like Hallway and LBF, it nonetheless successfully improved agent collaboration. DCMAC outperformed different algorithms in laborious and tremendous laborious SMAC maps, demonstrating its effectiveness in complicated environments.
The steerage mannequin of DCMAC, based mostly on the utmost return higher sure coaching paradigm, confirmed glorious convergence and better win charges in laborious and tremendous laborious SMAC maps. This efficiency validated the effectiveness of coaching a really perfect coverage utilizing joint observations and the help of the demand infer module.
In communication-constrained environments, DCMAC maintained excessive efficiency below 95% communication constraints and outperformed MAIC even below stricter limitations. At 85% communication constraint, DCMAC confirmed a big decline however nonetheless achieved greater win charges in Prepare Mode.
This examine presents DCMAC, which introduces a demand-aware custom-made multi-agent communication protocol to boost collaborative multi-agent studying effectivity. It overcomes the restrictions of earlier approaches by enabling brokers to broadcast tiny messages and parse teammate calls for, bettering communication effectiveness. DCMAC incorporates a steerage mannequin skilled on joint observations, impressed by data distillation, to boost the educational course of. In depth experiments throughout varied benchmarks, together with communication-constrained situations, reveal DCMAC’s superiority. The protocol reveals explicit energy in complicated environments and below restricted communication sources, outperforming present strategies and providing a sturdy answer for environment friendly collaboration in numerous and difficult multi-agent reinforcement studying duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


