


Continuous studying is a quickly evolving space of analysis that focuses on creating fashions able to studying from sequentially arriving knowledge streams, much like human studying. It addresses the challenges of adapting to new info whereas retaining beforehand acquired information. This discipline is especially related in eventualities the place fashions should carry out effectively on a number of duties over prolonged intervals, equivalent to real-world purposes with non-stationary knowledge and restricted computational assets. Not like conventional machine studying, the place fashions are educated on static datasets, continuous studying requires fashions to adapt dynamically to new knowledge whereas managing reminiscence and computational effectivity.
A major problem in continuous studying is the issue of “catastrophic forgetting,” the place neural networks lose the flexibility to recall beforehand discovered duties when uncovered to new ones. This phenomenon is very problematic when fashions need assistance to retailer or revisit outdated knowledge, making it troublesome to steadiness studying stability and mannequin adaptability. The shortcoming to successfully combine new info with out sacrificing the efficiency of prior information stays a significant hurdle. Researchers have been attempting to design options that tackle this limitation. But, many current strategies fail to realize the specified ends in exemplar-free eventualities the place no earlier knowledge samples might be saved for future reference.
Present strategies to deal with catastrophic forgetting usually contain joint coaching of representations alongside classifiers or utilizing expertise replay and regularization strategies. These approaches, nonetheless, assume that representations derived from regularly discovered neural networks will naturally outperform predefined random features, as noticed in normal deep studying setups. The core problem is that these strategies are usually not evaluated below the constraints of continuous studying. For example, fashions usually can’t be up to date sufficiently in on-line continuous studying eventualities earlier than knowledge is discarded. This ends in suboptimal representations and lowered classification accuracy when coping with new knowledge streams.
Researchers from the College of Oxford, IIIT Hyderabad, and Apple have developed a novel strategy referred to as RanDumb. The strategy makes use of a mix of random Fourier options and a linear classifier to create efficient representations for classification with out the necessity for storing exemplars or performing frequent updates. RanDumb’s mechanism is easy—it initiatives uncooked enter pixels right into a high-dimensional characteristic area utilizing a random Fourier remodel, which approximates the Radial Foundation Operate (RBF) Kernel. This fastened random projection is adopted by a easy linear classifier that classifies the remodeled options based mostly on their nearest class means. This methodology outperforms many current strategies by eliminating the necessity for fine-tuning or complicated neural community updates, making it extremely appropriate for exemplar-free continuous studying.
RanDumb operates by embedding the enter knowledge right into a high-dimensional area, decorrelating the options utilizing Mahalanobis distance and cosine similarity for correct classification. Not like conventional strategies that replace representations alongside classifiers, RanDumb makes use of a hard and fast random remodel for embedding. It solely requires on-line updates to the covariance matrix and sophistication means, permitting it to deal with new knowledge because it arrives effectively. The strategy additionally bypasses the necessity for reminiscence buffers, making it a really perfect answer for low-resource environments. Moreover, the strategy retains computational simplicity by working on one pattern at a time, guaranteeing scalability even with massive datasets.
Experimental evaluations reveal that RanDumb persistently performs effectively throughout a number of continuous studying benchmarks. For instance, on the MNIST dataset, RanDumb achieved an accuracy of 98.3%, surpassing current strategies by 5-15% margins. In CIFAR-10 and CIFAR-100 benchmarks, RanDumb recorded accuracies of 55.6% and 28.6%, respectively, outperforming state-of-the-art strategies that depend on storing earlier samples. The outcomes spotlight the strategy’s robustness in dealing with continuous on-line and offline studying eventualities with out storing exemplars or using complicated coaching methods. Particularly, RanDumb matched or exceeded the efficiency of joint coaching on many benchmarks, bridging 70-90% of the efficiency hole between constrained continuous studying and unconstrained joint studying.
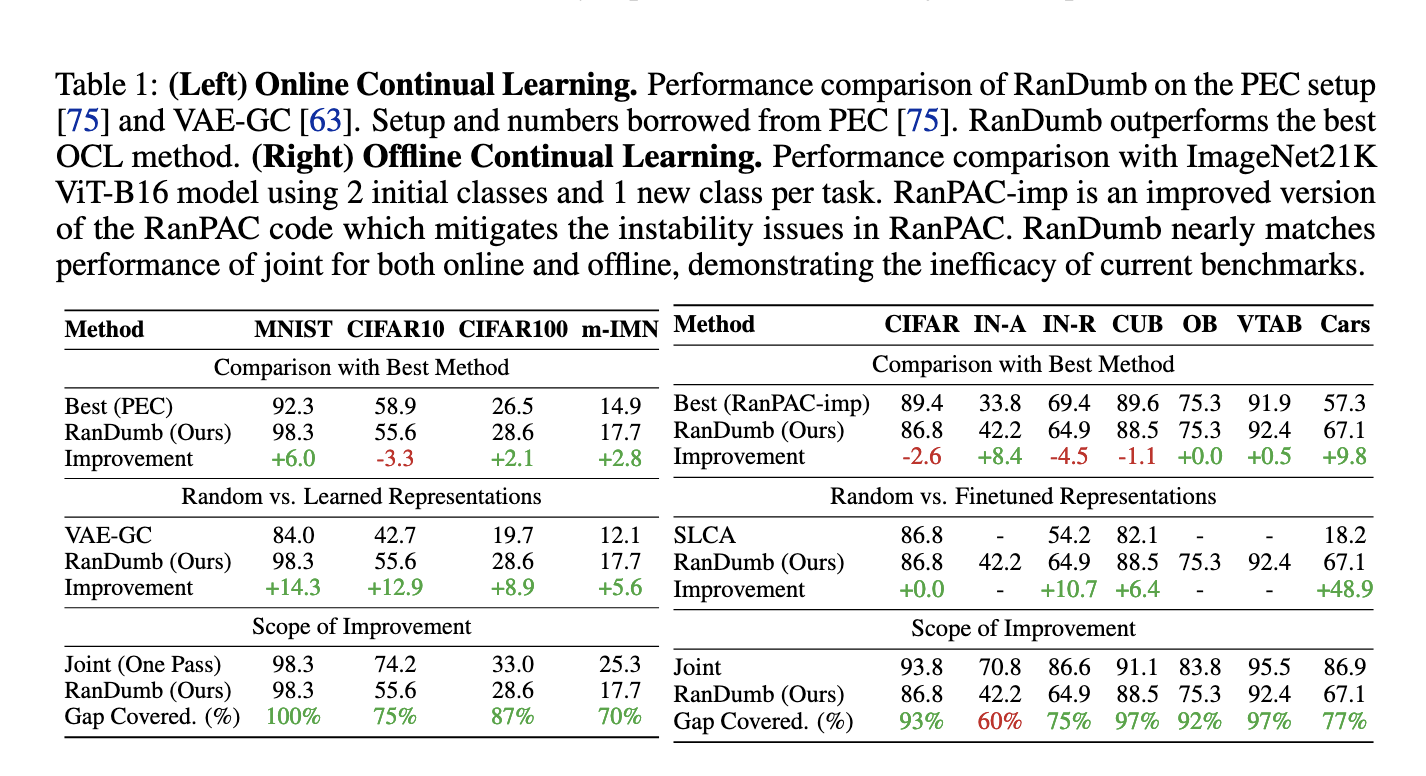
Furthermore, RanDumb’s effectivity extends to eventualities that incorporate pretrained characteristic extractors. When utilized to complicated datasets like TinyImageNet, the proposed methodology achieved close to state-of-the-art efficiency utilizing a easy linear classifier on prime of random projections. The strategy managed to bridge the efficiency hole to joint classifiers by as much as 90%, considerably outperforming most continuous fine-tuning and prompt-tuning methods. Additional, the strategy exhibits a marked efficiency achieve in low-exemplar eventualities the place knowledge storage is restricted or unavailable. For instance, RanDumb outperformed earlier main strategies by 4% on the CIFAR-100 dataset in offline continuous studying.
In conclusion, the RanDumb strategy redefines the assumptions surrounding efficient illustration studying in continuous studying. Its random feature-based methodology proves to be a less complicated but extra highly effective answer for illustration studying, difficult the traditional reliance on complicated neural community updates. The analysis addresses the constraints of present continuous studying strategies and opens up new avenues for creating environment friendly and scalable options in exemplar-free and resource-constrained environments. By leveraging the facility of random embeddings, RanDumb paves the best way for future developments in continuous studying, particularly in on-line studying eventualities the place knowledge and computational assets are restricted.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Neglect to hitch our 52k+ ML SubReddit.
We’re inviting startups, corporations, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report can be launched in late October/early November 2024. Click on right here to arrange a name!
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


