


Visitors forecasting is a elementary side of sensible metropolis administration, important for enhancing transportation planning and useful resource allocation. With the fast development of deep studying, complicated spatiotemporal patterns in site visitors knowledge can now be successfully modeled. Nonetheless, real-world functions current distinctive challenges because of the large-scale nature of those methods, which usually embody hundreds of interconnected sensors distributed over huge geographical areas. Conventional fashions, similar to graph neural networks (GNNs) and transformer-based architectures, have been broadly adopted in site visitors forecasting because of their potential to seize spatial and temporal dependencies. Nonetheless, as these networks develop, their computational calls for improve exponentially, making making use of these strategies to intensive networks just like the California street system tough.
One of the crucial urgent points with current fashions is their lack of ability to deal with large-scale street networks effectively. For instance, well-liked benchmarks just like the PEMS sequence and MeTR-LA include comparatively few nodes, which is manageable for traditional fashions. Nonetheless, these datasets don’t precisely symbolize the complexity of real-world site visitors methods, similar to California’s Caltrans Efficiency Measurement System, which contains almost 20,000 lively sensors. The numerous problem is sustaining computational effectivity whereas modeling native and world patterns inside such a big community. With out an efficient resolution, the restrictions of present fashions, such because the excessive reminiscence utilization and intensive computation time required, proceed to hinder their scalability and deployment in sensible eventualities.
A number of approaches have been launched to sort out these limitations, combining GNNs and Transformer-based fashions to leverage their strengths. Spatiotemporal attention-based strategies like STAEformer present high-order spatiotemporal interactions utilizing a number of stacked layers. Whereas these fashions enhance efficiency on small—to medium-sized datasets, their computational overheads make them impractical for large-scale networks. Consequently, there’s a want for novel architectures that may steadiness mannequin complexity and computational necessities whereas guaranteeing correct site visitors predictions throughout varied eventualities.
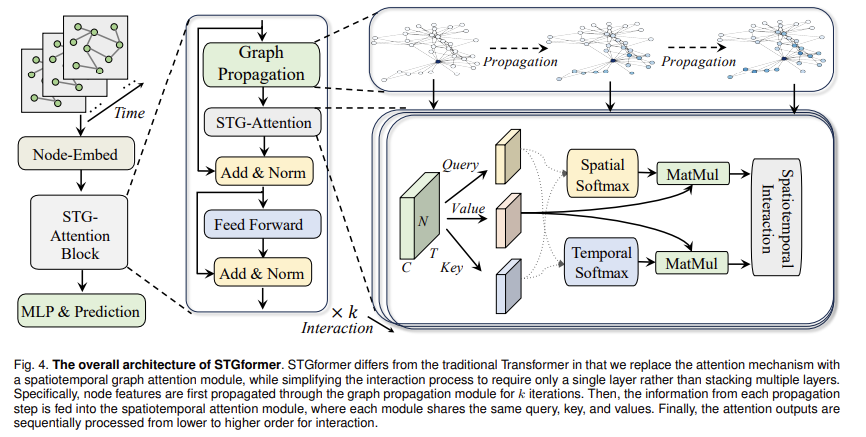
Researchers from the SUSTech-UTokyo Joint Analysis Middle on Tremendous Sensible Metropolis, Southern College of Science and Expertise (SUSTech), Jilin College, and the College of Tokyo developed the STGformer. This novel mannequin integrates spatiotemporal consideration mechanisms inside a graph construction. The analysis staff launched this mannequin to realize excessive effectivity in site visitors forecasting. The important thing innovation in STGformer lies in its structure, which mixes graph-based convolutions with Transformer-like consideration blocks in a single layer. This integration permits it to take care of the expressive energy of Transformers whereas considerably decreasing computational prices. In contrast to conventional strategies that require a number of consideration layers, the STGformer captures high-order spatiotemporal interactions in a single consideration block. This distinctive strategy ends in a 100x speedup and a 99.8% discount in GPU reminiscence utilization in comparison with the STAEformer mannequin when examined on the LargeST benchmark.
The researchers carried out a sophisticated spatiotemporal graph consideration module that processes spatial and temporal dimensions as a unified entity. This design reduces the computational complexity by adopting a linear consideration mechanism, which replaces the usual softmax operation with an environment friendly weighting operate. The effectivity of this methodology was showcased utilizing a number of large-scale datasets, together with the San Diego and Bay Space datasets, the place STGformer outperformed state-of-the-art fashions. The San Diego dataset achieved a 3.61% enchancment in Imply Absolute Error (MAE) and a 6.73% discount in Imply Absolute Share Error (MAPE) in comparison with the earlier finest fashions. Related developments have been noticed in different datasets, highlighting the mannequin’s robustness and adaptableness in numerous site visitors eventualities.
STGformer’s structure offers a breakthrough in site visitors forecasting by making it possible to deploy fashions on real-world, large-scale site visitors networks with out compromising efficiency or effectivity. When examined on the California street community, the mannequin demonstrated outstanding effectivity by finishing batch inference 100 occasions sooner than STAEformer and utilizing solely 0.2% of the reminiscence assets. These enhancements make STGformer an acceptable basis for future analysis and improvement in spatiotemporal modeling. Its generalization capabilities have been additional validated by means of cross-year state of affairs assessments, the place the mannequin maintained excessive accuracy even when utilized to unseen knowledge from the next yr.
Key Takeaways from the analysis:
- Computational Effectivity: In comparison with conventional fashions like STAEformer, STGformer achieves a 100x speedup and 99.8% discount in GPU reminiscence utilization.
- Scalability: The mannequin can deal with real-world networks with as much as 20,000 sensors, overcoming the restrictions of current fashions that fail at large-scale deployments.
- Efficiency Good points: Achieved a 3.61% enchancment in MAE and a 6.73% discount in MAPE on the San Diego dataset, outperforming state-of-the-art fashions.
- Generalization Functionality: Demonstrated strong efficiency throughout completely different datasets and maintained accuracy in cross-year testing, showcasing adaptability to altering site visitors circumstances.
- Novel Structure: Integrating spatiotemporal graph consideration with linear consideration mechanisms permits STGformer to seize native and world site visitors patterns effectively.

In conclusion, the STGformer mannequin launched by the analysis staff presents a extremely environment friendly and scalable resolution for site visitors forecasting on large-scale street networks. Addressing the restrictions of current GNNs and Transformer-based strategies allows simpler useful resource allocation and transportation planning in sensible metropolis administration. The proposed mannequin’s potential to deal with high-dimensional spatiotemporal knowledge utilizing minimal computational assets makes it a super candidate for deployment in real-world site visitors forecasting functions. The outcomes obtained throughout a number of datasets and benchmarks emphasize its potential to grow to be an ordinary instrument in city computing.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Wish to get in entrance of 1 Million+ AI Readers? Work with us right here
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.


