


Pure language processing (NLP) has seen speedy developments, with giant language fashions (LLMs) main the cost in remodeling how textual content is generated and interpreted. These fashions have showcased a powerful potential to create fluent and coherent responses throughout numerous purposes, from chatbots to summarization instruments. Nonetheless, deploying these fashions in essential fields comparable to finance, healthcare, and legislation has highlighted the significance of making certain that responses are coherent, correct, and contextually devoted. Inaccurate data or unsupported claims can have extreme implications in such domains, making assessing and bettering the faithfulness of LLM outputs when working inside given contexts is important.
One main challenge in LLM-generated textual content is the phenomenon of “hallucination,” the place the mannequin generates content material that both contradicts the supplied context or introduces details that aren’t current. This challenge could be categorized into two sorts: factual hallucination, the place the generated output deviates from established information, and faithfulness hallucination, the place the generated response is inconsistent with the supplied context. Regardless of ongoing analysis and growth on this discipline, there nonetheless must be a big hole in benchmarks that successfully consider how properly LLMs keep faithfulness to the context, notably in advanced situations the place the context could embody conflicting or incomplete data. This problem must be addressed to stop the erosion of consumer belief in real-world purposes.
Present strategies for evaluating LLMs give attention to making certain factuality however typically want to enhance by way of assessing faithfulness to context. These benchmarks assess correctness towards well-known details or world information however don’t measure how properly the generated responses align with the context, particularly in noisy retrieval situations the place context could be ambiguous or contradictory. Additionally, even integrating exterior data by way of retrieval-augmented era (RAG) doesn’t assure context adherence. As an illustration, when a number of related paragraphs are retrieved, the mannequin may omit essential particulars or current conflicting proof. This complexity have to be totally captured in present hallucination analysis benchmarks, making assessing LLM efficiency in such nuanced conditions difficult.
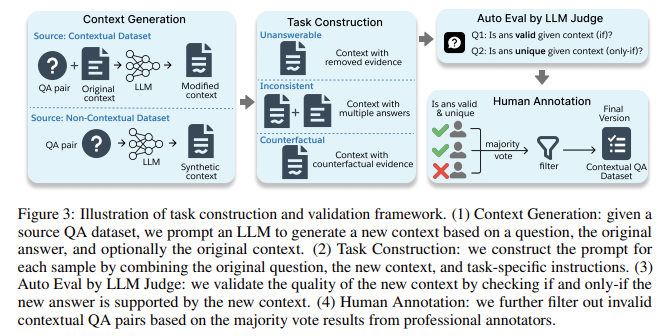
Researchers at Salesforce AI Analysis have launched a brand new benchmark named FaithEval, particularly designed to judge the contextual faithfulness of LLMs. FaithEval addresses this challenge by concentrating on three distinctive situations: unanswerable contexts, inconsistent contexts, and counterfactual contexts. The benchmark features a various set of 4.9K high-quality issues, validated by way of a rigorous four-stage context building and validation framework that mixes LLM-based auto-evaluation and human validation. By simulating real-world situations the place the retrieved context may lack vital particulars or comprise contradictory or fabricated data, FaithEval gives a complete analysis of how properly LLMs can align their responses with the context.
FaithEval employs a meticulous four-stage validation framework, making certain that each pattern is constructed and validated for high quality and coherence. The dataset covers three principal duties: unanswerable contexts, inconsistent contexts, and counterfactual contexts. For instance, within the unanswerable context activity, the context could embody related particulars however extra particular data to reply the query, making it difficult for fashions to determine when to abstain from producing a solution. Equally, within the inconsistent context activity, a number of paperwork present conflicting data on the identical subject, and the mannequin should decide which data is extra credible or whether or not a battle exists. The counterfactual context activity consists of statements contradicting frequent sense or details, requiring fashions to navigate between contradictory proof and customary information. This benchmark checks LLMs’ potential to deal with 4.9K QA pairs, together with duties that simulate situations the place fashions should stay devoted regardless of distractions and adversarial contexts.
The research outcomes reveal that even state-of-the-art fashions like GPT-4o and Llama-3-70B wrestle to keep up faithfulness in advanced contexts. As an illustration, GPT-4o, which achieved a excessive accuracy of 96.3% on normal factual benchmarks, confirmed a big decline in efficiency, dropping to 47.5% accuracy when the context launched counterfactual proof. Equally, Phi-3-medium-128k-instruct, which performs properly in common contexts with an accuracy of 76.8%, struggled in unanswerable contexts, the place it achieved solely 7.4% accuracy. This discovering highlights that bigger fashions or these with extra parameters don’t essentially assure higher adherence to context, making it essential to refine analysis frameworks and develop extra context-aware fashions.
The FaithEval benchmark emphasizes a number of key insights from the analysis of LLMs, offering invaluable takeaways:
- Efficiency Drop in Adversarial Contexts: Even top-performing fashions skilled a big drop in efficiency when the context was adversarial or inconsistent.
- Measurement Does Not Equate to Efficiency: Bigger fashions like Llama-3-70B didn’t constantly carry out higher than smaller ones, revealing that parameter rely alone isn’t a measure of faithfulness.
- Want for Enhanced Benchmarks: Present benchmarks are insufficient in evaluating faithfulness in situations involving contradictory or fabricated data, necessitating extra rigorous evaluations.

In conclusion, the FaithEval benchmark gives a well timed contribution to the continued growth of LLMs by introducing a strong framework to judge contextual faithfulness. This analysis highlights the constraints of present benchmarks and requires additional developments to make sure that future LLMs can generate contextually devoted and dependable outputs throughout numerous real-world situations. As LLMs proceed to evolve, such benchmarks might be instrumental in pushing the boundaries of what these fashions can obtain and making certain they continue to be reliable in essential purposes.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit
Considering selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

