


One of many main challenges in aligning massive language fashions (LLMs) with human preferences is the problem in choosing the precise reward mannequin (RM) to information their coaching. A single RM could excel at duties like inventive writing however fail in additional logic-oriented areas like mathematical reasoning. This lack of generalization results in suboptimal efficiency and points like reward hacking. On the similar time, utilizing a number of RMs concurrently is computationally costly and introduces conflicting alerts. Overcoming these challenges is essential for creating extra adaptable and correct AI methods able to dealing with numerous real-world purposes.
Present approaches both depend on a single RM or mix a number of RMs in an ensemble. Single RMs battle to generalize throughout duties, resulting in poor efficiency, particularly when encountering advanced, multi-domain issues. Ensemble strategies mitigate this however include excessive computational prices and face difficulties in dealing with noisy or conflicting alerts from the RMs. These limitations decelerate mannequin coaching and degrade total efficiency, creating inefficiencies that hinder widespread, real-time purposes.
The researchers from UNC Chapel Hill suggest LASER (Studying to Adaptively Choose Rewards), which frames RM choice as a multi-armed bandit downside. As a substitute of loading and working a number of RMs concurrently, LASER dynamically selects essentially the most appropriate RM for every activity or occasion throughout coaching. The tactic makes use of the LinUCB bandit algorithm, which adapts RM choice based mostly on activity context and previous efficiency. By optimizing RM choice on an occasion stage, LASER reduces computational overhead whereas bettering the effectivity and accuracy of LLM coaching throughout a various set of duties, avoiding the reward hacking issues seen in single RM strategies.
LASER operates by iterating by means of duties, producing a number of responses from the LLM, and scoring them with essentially the most acceptable RM chosen by the MAB. Utilizing the LinUCB algorithm, the MAB balances exploration (testing new RMs) and exploitation (utilizing high-performing RMs). The tactic was examined on numerous benchmarks reminiscent of StrategyQA, GSM8K, and the WildChat dataset, protecting reasoning, mathematical, and instruction-following duties. LASER constantly adapts its RM choice course of, resulting in improved coaching effectivity and accuracy throughout these domains. The dynamic choice additionally permits higher dealing with of noisy or conflicting RMs, leading to extra sturdy efficiency.
The researchers demonstrated that LASER constantly enhanced LLM efficiency throughout a number of benchmarks. For reasoning duties like StrategyQA and GSM8K, LASER improved common accuracy by 2.67% in comparison with ensemble strategies. On instruction-following duties, LASER achieved a 71.45% win price, outperforming sequential RM choice. In long-context understanding duties, LASER delivered substantial enhancements, growing F1 scores by 2.64 and a couple of.42 factors in single- and multi-document QA duties, respectively. Total, LASER’s adaptive RM choice led to extra environment friendly coaching, decreased computational complexity, and improved generalization throughout a variety of duties.
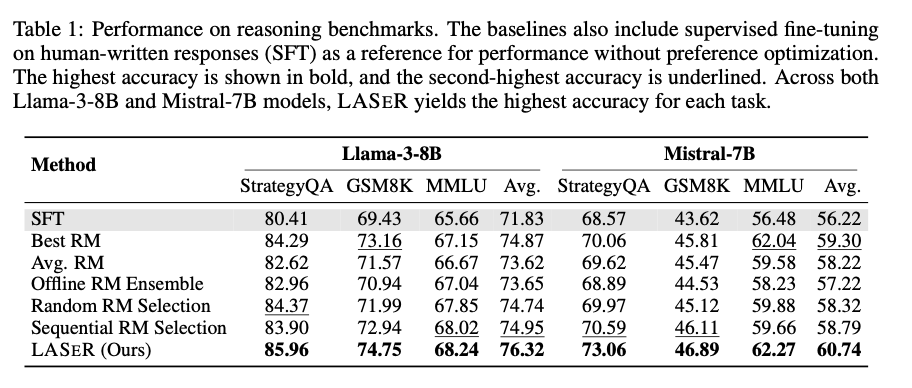
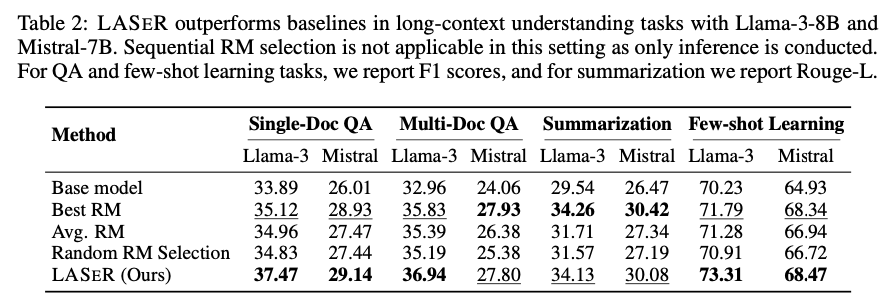
In conclusion, LASER represents a major development in reward mannequin choice for LLM coaching. By dynamically choosing essentially the most acceptable RM for every occasion, LASER improves each coaching effectivity and activity efficiency throughout numerous benchmarks. This methodology addresses the constraints of single and ensemble RM approaches, providing a sturdy resolution to optimize LLM alignment with human preferences. With its capability to generalize throughout duties and deal with noisy rewards, LASER is poised to have an enduring influence on future AI growth.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit
Serious about selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s keen about knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.

