


Transformers have gained vital consideration resulting from their highly effective capabilities in understanding and producing human-like textual content, making them appropriate for varied functions like language translation, summarization, and inventive content material era. They function primarily based on an consideration mechanism, which determines how a lot focus every token in a sequence ought to have on others to make knowledgeable predictions. Whereas they provide nice promise, the problem lies in optimizing these fashions to deal with giant quantities of knowledge effectively with out extreme computational prices.
A major problem in creating transformer fashions is their inefficiency when dealing with lengthy textual content sequences. Because the context size will increase, the computational and reminiscence necessities develop exponentially. This occurs as a result of every token interacts with each different token within the sequence, resulting in quadratic complexity that shortly turns into unmanageable. This limitation constrains the appliance of transformers in duties that demand lengthy contexts, similar to language modeling and doc summarization, the place retaining and processing all the sequence is essential for sustaining context and coherence. Thus, options are wanted to scale back the computational burden whereas retaining the mannequin’s effectiveness.
Approaches to deal with this concern have included sparse consideration mechanisms, which restrict the variety of interactions between tokens, and context compression strategies that cut back the sequence size by summarizing previous data. These strategies try to scale back the variety of tokens thought-about within the consideration mechanism however usually achieve this at the price of efficiency, as lowering context can result in a lack of essential data. This trade-off between effectivity and efficiency has prompted researchers to discover new strategies to keep up excessive accuracy whereas lowering computational and reminiscence necessities.
Researchers at Google Analysis have launched a novel strategy referred to as Selective Consideration, which goals to reinforce the effectivity of transformer fashions by enabling the mannequin to disregard now not related tokens dynamically. The strategy permits every token in a sequence to resolve whether or not different tokens are wanted for future computations. The important thing innovation lies in including a range mechanism to the usual consideration course of, lowering the eye paid to irrelevant tokens. This mechanism doesn’t introduce new parameters or require intensive computations, making it a light-weight and efficient resolution for optimizing transformers.
The Selective Consideration approach is applied utilizing a soft-mask matrix that determines the significance of every token to future tokens. The values on this matrix are collected over all tokens after which subtracted from the eye scores earlier than computing the weights. This modification ensures that unimportant tokens obtain much less consideration, permitting the mannequin to disregard them in subsequent computations. By doing so, transformers outfitted with Selective Consideration can function with fewer sources whereas sustaining excessive efficiency throughout totally different contexts. Additional, the context measurement may be pruned by eradicating pointless tokens, lowering reminiscence and computational prices throughout inference.
The researchers carried out intensive experiments to guage the efficiency of Selective Consideration throughout varied pure language processing duties. The outcomes confirmed that Selective Consideration transformers achieved related or higher efficiency than normal transformers whereas considerably lowering reminiscence utilization and computational prices. For instance, in a transformer mannequin with 100 million parameters, the reminiscence necessities for the eye module have been lowered by components of 16, 25, and 47 for context sizes of 512, 1,024, and a pair of,048 tokens, respectively. The proposed technique additionally outperformed conventional transformers on the HellaSwag benchmark, attaining an accuracy enchancment of as much as 5% for bigger mannequin sizes. This substantial reminiscence discount straight interprets into extra environment friendly inference, making deploying these fashions in resource-constrained environments possible.
Additional evaluation confirmed that transformers outfitted with Selective Consideration may match the efficiency of conventional transformers with twice as many consideration heads and parameters. This discovering is critical as a result of the proposed technique permits for smaller, extra environment friendly fashions with out compromising accuracy. For instance, within the validation set of the C4 language modeling process, transformers with Selective Consideration maintained comparable perplexity scores whereas requiring as much as 47 occasions much less reminiscence in some configurations. This breakthrough paves the best way for deploying high-performance language fashions in environments with restricted computational sources, similar to cellular gadgets or edge computing platforms.
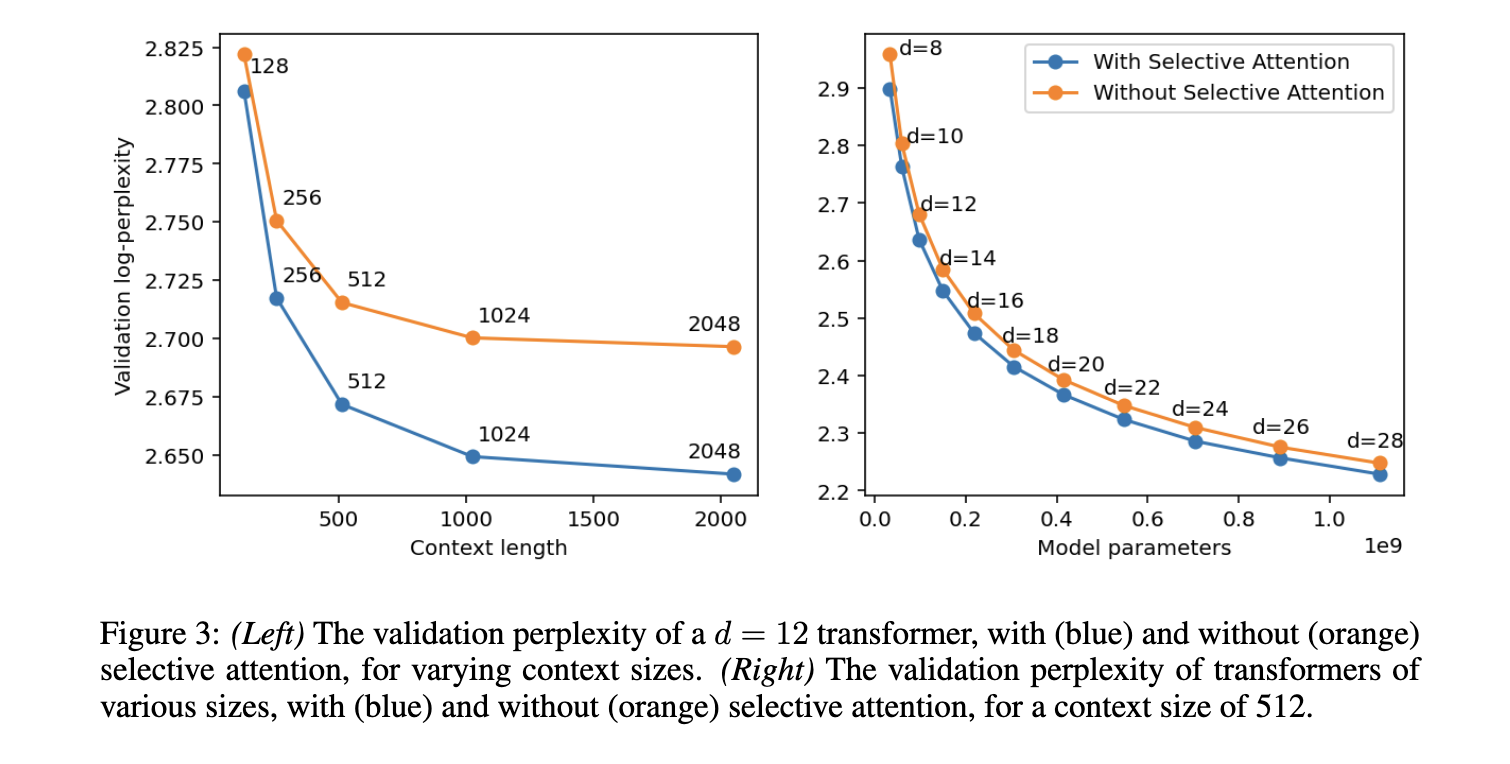
In conclusion, Google Analysis’s growth of Selective Consideration addresses the important thing problem of excessive reminiscence and computational prices in transformer fashions. The approach introduces a easy but highly effective modification that enhances the effectivity of transformers with out including complexity. By enabling the mannequin to deal with vital tokens and ignore others, Selective Consideration improves each efficiency and effectivity, making it a beneficial development in pure language processing. The outcomes achieved by way of this technique have the potential to broaden the applicability of transformers to a broader vary of duties and environments, contributing to the continued progress in synthetic intelligence analysis and functions.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 50k+ ML SubReddit
Fascinated about selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


