


AI has made vital strides in growing massive language fashions (LLMs) that excel in advanced duties corresponding to textual content era, summarization, and conversational AI. Fashions like LaPM 540B and Llama-3.1 405B show superior language processing skills, but their computational calls for restrict their applicability in real-world, resource-constrained environments. These LLMs are sometimes cloud-based, requiring in depth GPU reminiscence and {hardware}, which raises privateness considerations and prevents fast on-device deployment. In distinction, small language fashions (SLMs) are being explored as an environment friendly and adaptable different, able to performing domain-specific duties with decrease computational necessities.
The first problem with LLMs, as addressed by SLMs, is their excessive computational value and latency, notably for specialised functions. As an example, fashions like Llama-3.1, containing 405 billion parameters, require over 200 GB of GPU reminiscence, rendering them impractical for deployment on cell units or edge methods. In real-time eventualities, these fashions endure from excessive latency; processing 100 tokens on a Snapdragon 685 cell processor with the Llama-2 7B mannequin, for instance, can take as much as 80 seconds. Such delays hinder real-time functions, making them unsuitable for settings like healthcare, finance, and private assistant methods that demand fast responses. The operational bills related to LLMs additionally prohibit their use, as their fine-tuning for specialised fields corresponding to healthcare or regulation requires vital assets, limiting accessibility for organizations with out massive computational budgets.
Numerous strategies presently handle these limitations, together with cloud-based APIs, knowledge batching, and mannequin pruning. Nevertheless, these options usually fall brief, as they need to totally alleviate excessive latency points, dependence on in depth infrastructure, and privateness considerations. Methods like pruning and quantization can cut back mannequin measurement however continuously lower accuracy, which is detrimental for high-stakes functions. The absence of scalable, low-cost options for fine-tuning LLMs for particular domains additional emphasizes the necessity for an alternate strategy to ship focused efficiency with out prohibitive prices.
Researchers from Pennsylvania State College, College of Pennsylvania, UTHealth Houston, Amazon, and Rensselaer Polytechnic Institute have carried out a complete survey on SLMs and appeared into a scientific framework to develop SLMs that steadiness effectivity with LLM-like capabilities. This analysis aggregates developments in fine-tuning, parameter sharing, and data distillation to create fashions tailor-made for environment friendly and domain-specific use instances. Compact architectures and superior knowledge processing methods allow SLMs to function in low-power environments, making them accessible for real-time functions on edge units. Institutional collaborations contributed to defining and categorizing SLMs, making certain that the taxonomy helps deployment in low-memory, resource-limited settings.
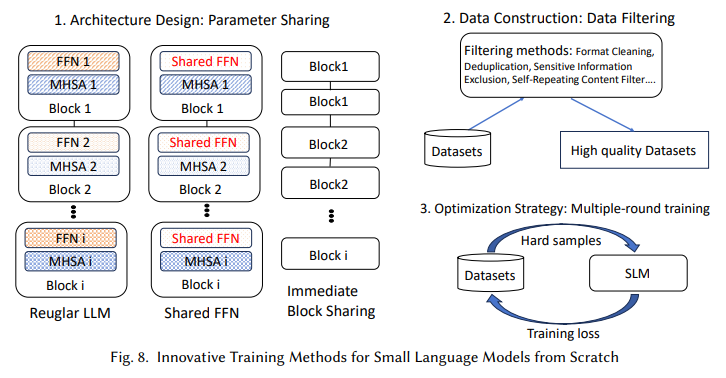
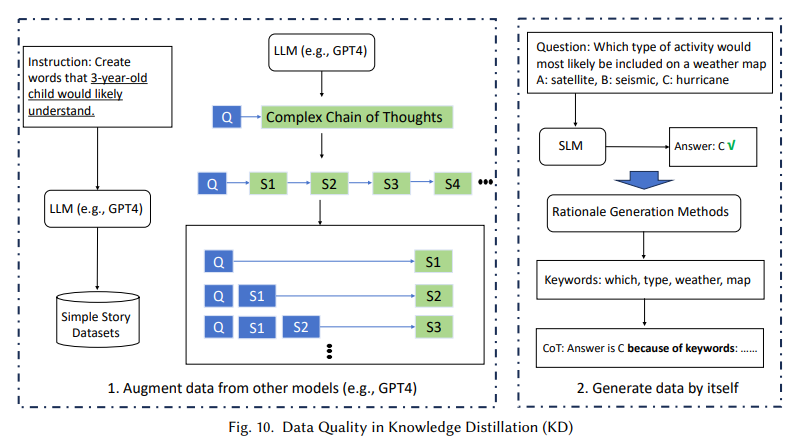
The technical strategies proposed on this analysis are integral to optimizing SLM efficiency. For instance, the survey highlights grouped question consideration (GQA), multi-head latent consideration (MLA), and Flash Consideration as important memory-efficient modifications that streamline consideration mechanisms. These enhancements permit SLMs to take care of excessive efficiency with out requiring the in depth reminiscence typical of LLMs. Additionally, parameter sharing and low-rank adaptation methods be sure that SLMs can handle advanced duties in specialised fields like healthcare, finance, and buyer assist, the place fast response and knowledge privateness are essential. The framework’s emphasis on knowledge high quality additional enhances mannequin efficiency, incorporating filtering, deduplication, and optimized knowledge buildings to enhance accuracy and velocity in domain-specific contexts.
Empirical outcomes underscore the efficiency potential of SLMs, as they’ll obtain effectivity near that of LLMs in particular functions with decreased latency and reminiscence use. In benchmarks throughout healthcare, finance, and customized assistant functions, SLMs present substantial latency reductions and enhanced knowledge privateness resulting from native processing. For instance, latency enhancements in healthcare and safe native knowledge dealing with supply an environment friendly answer for on-device knowledge processing and safeguarding delicate affected person info. The strategies utilized in SLM coaching and optimization permit these fashions to retain as much as 90% of LLM accuracy in domain-specific functions, a notable achievement given the discount in mannequin measurement and {hardware} necessities.
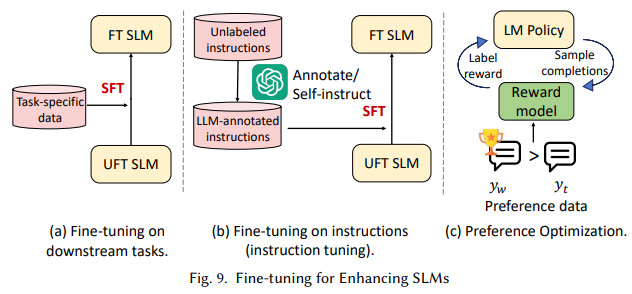
Key takeaways from the analysis:
- Computational Effectivity: SLMs function with a fraction of the reminiscence and processing energy required by LLMs, making them appropriate for units with constrained {hardware} like smartphones and IoT units.
- Area-Particular Adaptability: With focused optimizations corresponding to fine-tuning and parameter sharing, SLMs retain roughly 90% of LLM efficiency in specialised domains, together with healthcare and finance.
- Latency Discount: In comparison with LLMs, SLMs cut back response instances by over 70%, offering real-time processing capabilities important for edge functions and privacy-sensitive eventualities.
- Knowledge Privateness and Safety: SLM permits native processing, which reduces the necessity for knowledge switch to cloud servers and enhances privateness in high-stakes functions like healthcare and finance.
- Price-Effectiveness: By reducing {hardware} and computational necessities, SLMs current a possible answer for organizations with restricted assets, democratizing entry to AI-powered language fashions.

In conclusion, the survey on small language fashions presents a viable framework that addresses the vital problems with deploying LLMs in resource-constrained environments. The proposed SLM strategy provides a promising path for integrating superior language processing capabilities into low-power units, extending the attain of AI know-how throughout numerous fields. By optimizing latency, privateness, and computational effectivity, SLMs present a scalable answer for real-world functions the place conventional LLMs are impractical, making certain language fashions’ broader applicability and sustainability in trade and analysis.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
[AI Magazine/Report] Learn Our Newest Report on ‘SMALL LANGUAGE MODELS‘
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

