


I have been constantly following the pc imaginative and prescient (CV) and picture synthesis analysis scene at Arxiv and elsewhere for round 5 years, so traits change into evident over time, they usually shift in new instructions yearly.
Due to this fact as 2024 attracts to an in depth, I assumed it applicable to check out some new or evolving traits in Arxiv submissions within the Pc Imaginative and prescient and Sample Recognition part. These observations, although knowledgeable by lots of of hours learning the scene, are strictly anecdata.
The Ongoing Rise of East Asia
By the top of 2023, I had observed that almost all of the literature within the ‘voice synthesis’ class was popping out of China and different areas in east Asia. On the finish of 2024, I’ve to watch (anecdotally) that this now applies additionally to the picture and video synthesis analysis scene.
This doesn’t imply that China and adjoining nations are essentially at all times outputting one of the best work (certainly, there may be some proof on the contrary); nor does it take account of the excessive chance in China (as within the west) that among the most fascinating and highly effective new growing methods are proprietary, and excluded from the analysis literature.
However it does recommend that east Asia is thrashing the west by quantity, on this regard. What that is price depends upon the extent to which you consider within the viability of Edison-style persistence, which normally proves ineffective within the face of intractable obstacles.
There are a lot of such roadblocks in generative AI, and it isn’t straightforward to know which could be solved by addressing current architectures, and which is able to should be reconsidered from zero.
Although researchers from east Asia appear to be producing a higher variety of pc imaginative and prescient papers, I’ve observed a rise within the frequency of ‘Frankenstein’-style initiatives – initiatives that represent a melding of prior works, whereas including restricted architectural novelty (or probably only a totally different kind of information).
This yr a far increased variety of east Asian (primarily Chinese language or Chinese language-involved collaborations) entries gave the impression to be quota-driven moderately than merit-driven, considerably rising the signal-to-noise ratio in an already over-subscribed area.
On the identical time, a higher variety of east Asian papers have additionally engaged my consideration and admiration in 2024. So if that is all a numbers sport, it is not failing – however neither is it low-cost.
Rising Quantity of Submissions
The quantity of papers, throughout all originating nations, has evidently elevated in 2024.
The preferred publication day shifts all year long; in the mean time it’s Tuesday, when the variety of submissions to the Pc Imaginative and prescient and Sample Recognition part is commonly round 300-350 in a single day, within the ‘peak’ intervals (Might-August and October-December, i.e., convention season and ‘annual quota deadline’ season, respectively).
Past my very own expertise, Arxiv itself experiences a file variety of submissions in October of 2024, with 6000 complete new submissions, and the Pc Imaginative and prescient part the second-most submitted part after Machine Studying.
Nonetheless, for the reason that Machine Studying part at Arxiv is commonly used as an ‘extra’ or aggregated super-category, this argues for Pc Imaginative and prescient and Sample Recognition really being the most-submitted Arxiv class.
Arxiv’s personal statistics definitely depict pc science because the clear chief in submissions:
Pc Science (CS) dominates submission statistics at Arxiv over the past 5 years. Supply: https://information.arxiv.org/about/experiences/submission_category_by_year.html
Stanford College’s 2024 AI Index, although not capable of report on most up-to-date statistics but, additionally emphasizes the notable rise in submissions of educational papers round machine studying in recent times:
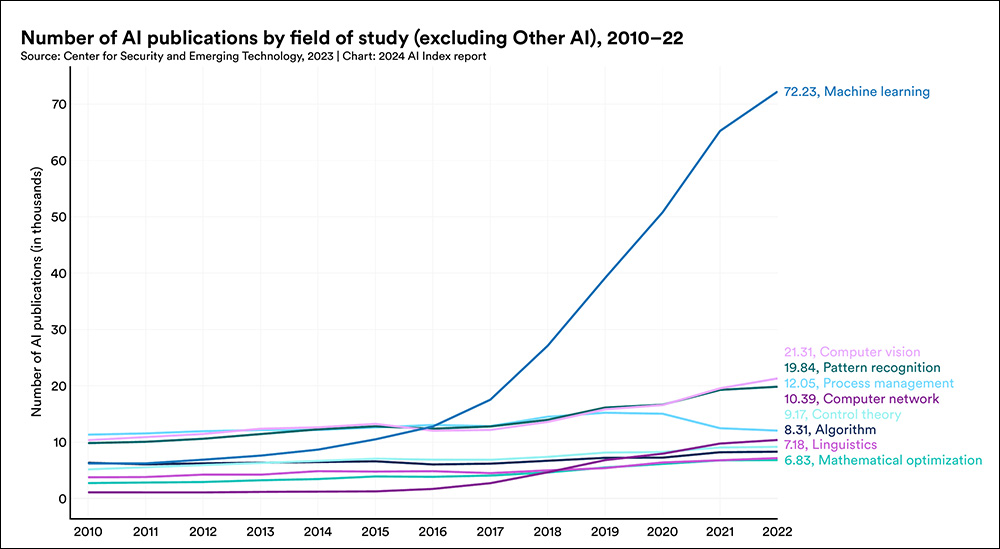
With figures not accessible for 2024, Stanford’s report nonetheless dramatically reveals the rise of submission volumes for machine studying papers. Supply: https://aiindex.stanford.edu/wp-content/uploads/2024/04/HAI_AI-Index-Report-2024_Chapter1.pdf
Diffusion>Mesh Frameworks Proliferate
One different clear pattern that emerged for me was a big upswing in papers that take care of leveraging Latent Diffusion Fashions (LDMs) as mills of mesh-based, ‘conventional’ CGI fashions.
Tasks of this kind embrace Tencent’s InstantMesh3D, 3Dtopia, Diffusion2, V3D, MVEdit, and GIMDiffusion, amongst a plenitude of comparable choices.
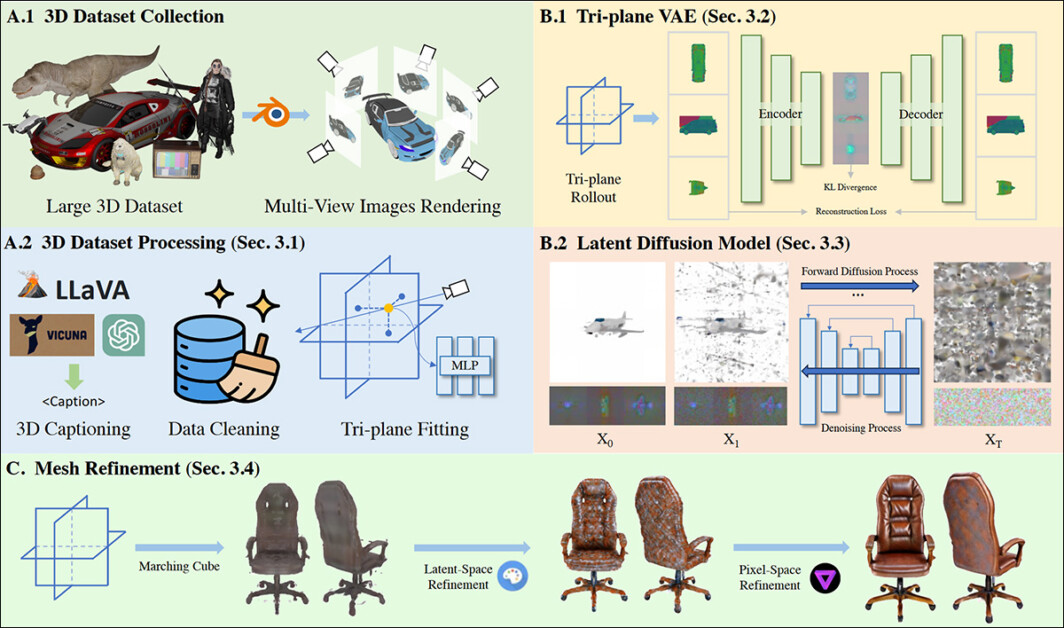
Mesh technology and refinement by way of a Diffusion-based course of in 3Dtopia. Supply: https://arxiv.org/pdf/2403.02234
This emergent analysis strand could possibly be taken as a tacit concession to the continuing intractability of generative methods comparable to diffusion fashions, which solely two years have been being touted as a possible substitute for all of the methods that diffusion>mesh fashions are actually in search of to populate; relegating diffusion to the position of a instrument in applied sciences and workflows that date again thirty or extra years.
Stability.ai, originators of the open supply Steady Diffusion mannequin, have simply launched Steady Zero123, which may, amongst different issues, use a Neural Radiance Fields (NeRF) interpretation of an AI-generated picture as a bridge to create an specific, mesh-based CGI mannequin that can be utilized in CGI arenas comparable to Unity, in video-games, augmented actuality, and in different platforms that require specific 3D coordinates, versus the implicit (hidden) coordinates of steady capabilities.
Click on to play. Photos generated in Steady Diffusion could be transformed to rational CGI meshes. Right here we see the results of a picture>CGI workflow utilizing Steady Zero 123. Supply: https://www.youtube.com/watch?v=RxsssDD48Xc
3D Semantics
The generative AI area makes a distinction between 2D and 3D methods implementations of imaginative and prescient and generative methods. For example, facial landmarking frameworks, although representing 3D objects (faces) in all circumstances, don’t all essentially calculate addressable 3D coordinates.
The favored FANAlign system, extensively utilized in 2017-era deepfake architectures (amongst others), can accommodate each these approaches:

Above, 2D landmarks are generated primarily based solely on acknowledged face lineaments and options. Beneath, they’re rationalized into 3D X/Y/Z area. Supply: https://github.com/1adrianb/face-alignment
So, simply as ‘deepfake’ has change into an ambiguous and hijacked time period, ‘3D’ has likewise change into a complicated time period in pc imaginative and prescient analysis.
For shoppers, it has sometimes signified stereo-enabled media (comparable to motion pictures the place the viewer has to put on particular glasses); for visible results practitioners and modelers, it gives the excellence between 2D art work (comparable to conceptual sketches) and mesh-based fashions that may be manipulated in a ‘3D program’ like Maya or Cinema4D.
However in pc imaginative and prescient, it merely implies that a Cartesian coordinate system exists someplace within the latent area of the mannequin – not that it might essentially be addressed or instantly manipulated by a consumer; at the least, not with out third-party interpretative CGI-based methods comparable to 3DMM or FLAME.
Due to this fact the notion of diffusion>3D is inexact; not solely can any kind of picture (together with an actual photograph) be used as enter to supply a generative CGI mannequin, however the much less ambiguous time period ‘mesh’ is extra applicable.
Nonetheless, to compound the anomaly, diffusion is wanted to interpret the supply photograph right into a mesh, within the majority of rising initiatives. So a greater description is perhaps image-to-mesh, whereas picture>diffusion>mesh is an much more correct description.
However that is a tough promote at a board assembly, or in a publicity launch designed to interact buyers.
Proof of Architectural Stalemates
Even in comparison with 2023, the final 12 months’ crop of papers reveals a rising desperation round eradicating the exhausting sensible limits on diffusion-based technology.
The important thing stumbling block stays the technology of narratively and temporally constant video, and sustaining a constant look of characters and objects – not solely throughout totally different video clips, however even throughout the quick runtime of a single generated video clip.
The final epochal innovation in diffusion-based synthesis was the creation of LoRA in 2022. Whereas newer methods comparable to Flux have improved on among the outlier issues, comparable to Steady Diffusion’s former incapability to breed textual content content material inside a generated picture, and total picture high quality has improved, nearly all of papers I studied in 2024 have been basically simply transferring the meals round on the plate.
These stalemates have occurred earlier than, with Generative Adversarial Networks (GANs) and with Neural Radiance Fields (NeRF), each of which did not reside as much as their obvious preliminary potential – and each of that are more and more being leveraged in additional standard methods (comparable to using NeRF in Steady Zero 123, see above). This additionally seems to be occurring with diffusion fashions.
Gaussian Splatting Analysis Pivots
It appeared on the finish of 2023 that the rasterization methodology 3D Gaussian Splatting (3DGS), which debuted as a medical imaging approach within the early Nineties, was set to abruptly overtake autoencoder-based methods of human picture synthesis challenges (comparable to facial simulation and recreation, in addition to identification switch).
The 2023 ASH paper promised full-body 3DGS people, whereas Gaussian Avatars supplied massively improved element (in comparison with autoencoder and different competing strategies), along with spectacular cross-reenactment.
This yr, nevertheless, has been comparatively quick on any such breakthrough moments for 3DGS human synthesis; a lot of the papers that tackled the issue have been both spinoff of the above works, or didn’t exceed their capabilities.
As an alternative, the emphasis on 3DGS has been in bettering its elementary architectural feasibility, resulting in a rash of papers that supply improved 3DGS exterior environments. Specific consideration has been paid to Simultaneous Localization and Mapping (SLAM) 3DGS approaches, in initiatives comparable to Gaussian Splatting SLAM, Splat-SLAM, Gaussian-SLAM, DROID-Splat, amongst many others.
These initiatives that did try and proceed or prolong splat-based human synthesis included MIGS, GEM, EVA, OccFusion, FAGhead, HumanSplat, GGHead, HGM, and Topo4D. Although there are others apart from, none of those outings matched the preliminary impression of the papers that emerged in late 2023.
The ‘Weinstein Period’ of Check Samples Is in (Sluggish) Decline
Analysis from south east Asia on the whole (and China specifically) usually options take a look at examples which can be problematic to republish in a assessment article, as a result of they characteristic materials that may be a little ‘spicy’.
Whether or not it’s because analysis scientists in that a part of the world are in search of to garner consideration for his or her output is up for debate; however for the final 18 months, an rising variety of papers round generative AI (picture and/or video) have defaulted to utilizing younger and scantily-clad girls and ladies in challenge examples. Borderline NSFW examples of this embrace UniAnimate, ControlNext, and even very ‘dry’ papers comparable to Evaluating Movement Consistency by Fréchet Video Movement Distance (FVMD).
This follows the final traits of subreddits and different communities which have gathered round Latent Diffusion Fashions (LDMs), the place Rule 34 stays very a lot in proof.
Movie star Face-Off
One of these inappropriate instance overlaps with the rising recognition that AI processes mustn’t arbitrarily exploit celeb likenesses – notably in research that uncritically use examples that includes engaging celebrities, usually feminine, and place them in questionable contexts.
One instance is AnyDressing, which, apart from that includes very younger anime-style feminine characters, additionally liberally makes use of the identities of traditional celebrities comparable to Marilyn Monroe, and present ones comparable to Ann Hathaway (who has denounced this type of utilization fairly vocally).

Arbitrary use of present and ‘traditional’ celebrities continues to be pretty frequent in papers from south east Asia, although the follow is barely on the decline. Supply: https://crayon-shinchan.github.io/AnyDressing/
In western papers, this explicit follow has been notably in decline all through 2024, led by the bigger releases from FAANG and different high-level analysis our bodies comparable to OpenAI. Critically conscious of the potential for future litigation, these main company gamers appear more and more unwilling to characterize even fictional photorealistic individuals.
Although the methods they’re creating (comparable to Imagen and Veo2) are clearly able to such output, examples from western generative AI initiatives now pattern in direction of ‘cute’, Disneyfied and very ‘secure’ photographs and movies.

Regardless of vaunting Imagen’s capability to create ‘photorealistic’ output, the samples promoted by Google Analysis are sometimes fantastical, ‘household’ fare – photorealistic people are rigorously prevented, or minimal examples offered. Supply: https://imagen.analysis.google/
Face-Washing
Within the western CV literature, this disingenuous method is especially in proof for customization methods – strategies that are able to creating constant likenesses of a selected particular person throughout a number of examples (i.e., like LoRA and the older DreamBooth).
Examples embrace orthogonal visible embedding, LoRA-Composer, Google’s InstructBooth, and a mess extra.

Google’s InstructBooth turns the cuteness issue as much as 11, although historical past means that customers are extra concerned about creating photoreal people than furry or fluffy characters. Supply: https://websites.google.com/view/instructbooth
Nonetheless, the rise of the ‘cute instance’ is seen in different CV and synthesis analysis strands, in initiatives comparable to Comp4D, V3D, DesignEdit, UniEdit, FaceChain (which concedes to extra real looking consumer expectations on its GitHub web page), and DPG-T2I, amongst many others.
The convenience with which such methods (comparable to LoRAs) could be created by residence customers with comparatively modest {hardware} has led to an explosion of freely-downloadable celeb fashions on the civit.ai area and neighborhood. Such illicit utilization stays potential by the open sourcing of architectures comparable to Steady Diffusion and Flux.
Although it’s usually potential to punch by the security options of generative text-to-image (T2I) and text-to-video (T2V) methods to supply materials banned by a platform’s phrases of use, the hole between the restricted capabilities of one of the best methods (comparable to RunwayML and Sora), and the limitless capabilities of the merely performant methods (comparable to Steady Video Diffusion, CogVideo and native deployments of Hunyuan), will not be actually closing, as many consider.
Somewhat, these proprietary and open-source methods, respectively, threaten to change into equally ineffective: costly and hyperscale T2V methods might change into excessively hamstrung attributable to fears of litigation, whereas the shortage of licensing infrastructure and dataset oversight in open supply methods might lock them completely out of the market as extra stringent laws take maintain.
First printed Tuesday, December 24, 2024


