


Agentic techniques have developed quickly lately, displaying potential to unravel complicated duties that mimic human-like decision-making processes. These techniques are designed to behave step-by-step, analyzing intermediate levels in duties like people do. Nevertheless, one of many largest challenges on this discipline is evaluating these techniques successfully. Conventional analysis strategies focus solely on the outcomes, leaving out essential suggestions that would assist enhance the intermediate steps of problem-solving. Because of this, the potential for real-time optimization of agentic techniques may very well be improved, slowing their progress in real-world functions like code technology and software program growth.
The shortage of efficient analysis strategies poses a significant issue for AI analysis and growth. Present analysis frameworks, resembling LLM-as-a-Decide, which makes use of massive language fashions to guage outputs from different AI techniques, should account for your entire task-solving course of. These fashions typically overlook intermediate levels, essential for agentic techniques as a result of they mimic human-like problem-solving methods. Additionally, whereas extra correct, human analysis is resource-intensive and impractical for large-scale duties. The absence of a complete, scalable analysis technique has restricted the development of agentic techniques, leaving AI builders needing correct instruments to evaluate their fashions all through the event course of.
Present strategies for evaluating agentic techniques rely closely on both human judgment or benchmarks that assess solely the ultimate process outcomes. Benchmarks like SWE-Bench, for instance, give attention to the success price of ultimate options in long-term automated duties however provide little perception into the efficiency of intermediate steps. Equally, HumanEval and MBPP consider code technology solely in primary, algorithmic duties, failing to mirror the complexity of real-world AI growth. Furthermore, massive language fashions (LLMs) have already proven the power to unravel 27% of duties in SWE-Bench. But, their efficiency on extra real looking, complete AI growth duties nonetheless must be improved. The restricted scope of those present benchmarks highlights the necessity for extra dynamic and informative analysis instruments that seize the complete breadth of agentic system capabilities.
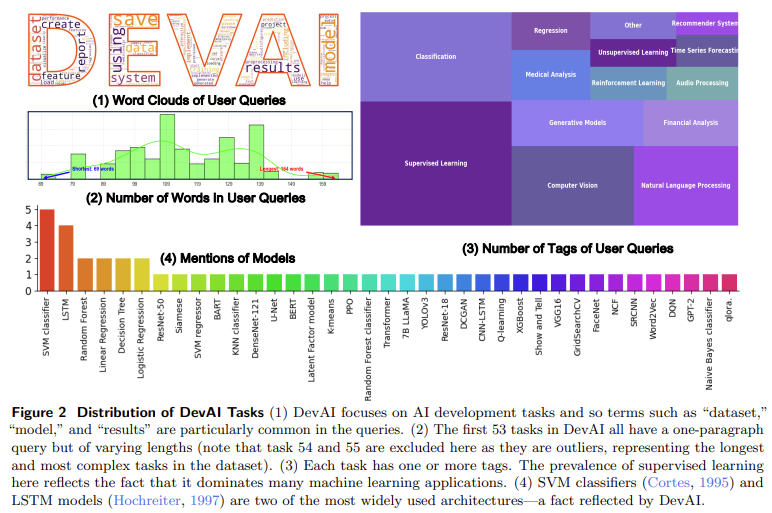
Meta AI and King Abdullah College of Science and Know-how (KAUST) researchers launched a novel analysis framework known as Agent-as-a-Decide. This progressive method makes use of agentic techniques to guage different agentic techniques, offering detailed suggestions all through the task-solving course of. The researchers developed a brand new benchmark known as DevAI, which incorporates 55 real looking AI growth duties, resembling code technology and software program engineering. DevAI options 365 hierarchical person necessities and 125 preferences, providing a complete testbed for evaluating agentic techniques in dynamic duties. The introduction of Agent-as-a-Decide permits steady suggestions, serving to to optimize the decision-making course of and considerably decreasing the reliance on human judgment.
The Agent-as-a-Decide framework assesses agentic techniques at every process stage quite than simply evaluating the end result. This method is an extension of LLM-as-a-Decide however is tailor-made to the distinctive traits of agentic techniques, permitting them to guage their efficiency whereas fixing complicated issues. The analysis staff examined the framework on three main open-source agentic techniques: MetaGPT, GPT-Pilot, and OpenHands. These techniques had been benchmarked in opposition to the 55 duties in DevAI. MetaGPT was probably the most cost-effective, with a mean value of $1.19 per process, whereas OpenHands was the most costly at $6.38. Relating to growth time, OpenHands was the quickest, finishing duties in a mean of 362.41 seconds, whereas GPT-Pilot took the longest at 1622.38 seconds.
The outcomes of the Agent-as-a-Decide framework achieved a 90% alignment with human evaluators, in comparison with LLM-as-a-Decide’s 70% alignment. Moreover, the brand new framework decreased analysis time by 97.72% and prices by 97.64% in comparison with human analysis. As an illustration, the common worth of human analysis underneath the DevAI benchmark was estimated at $1,297.50, taking on 86.5 hours. In distinction, Agent-as-a-Decide decreased this value to only $30.58, requiring solely 118.43 minutes to finish. These outcomes exhibit the framework’s potential to streamline and enhance the analysis course of for agentic techniques, making it a viable different to expensive human analysis.
The examine offered a number of key takeaways, summarizing the analysis’s implications for future AI growth. Agent-as-a-Decide introduces a scalable, environment friendly, and extremely correct technique of evaluating agentic techniques, opening the door for additional optimization of those techniques with out counting on costly human intervention. The DevAI benchmark presents a difficult however real looking set of duties, reflecting the necessities of AI growth and enabling a extra thorough analysis of agentic techniques’ capabilities.
Key Takeaways from the analysis:
- The Agent-as-a-Decide framework achieved a 90% alignment with human evaluators, outperforming LLM-as-a-Decide.
- DevAI includes 55 real-world AI growth duties that includes 365 hierarchical necessities and 125 preferences.
- Agent-as-a-Decide reduces analysis time by 97.72% and prices by 97.64% in comparison with human evaluators.
- OpenHands was the quickest at process completion, averaging 362.41 seconds, whereas MetaGPT was probably the most cost-efficient at $1.19 per process.
- The brand new framework is a scalable different to human analysis. It gives steady suggestions throughout task-solving processes, which is essential for agentic system optimization.

In conclusion, this analysis marks a big development in evaluating agentic AI techniques. The Agent-as-a-Decide framework gives a extra environment friendly and scalable analysis technique and affords deeper insights into the intermediate steps of AI growth. The DevAI benchmark enhances this course of by introducing extra real looking and complete duties, pushing the boundaries of what agentic techniques can obtain. This mixture of progressive analysis strategies and sturdy benchmarks is poised to speed up progress in AI growth, enabling researchers to optimize agentic techniques extra successfully.
Take a look at the Paper and Dataset. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Neglect to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving High-quality-Tuned Fashions: Predibase Inference Engine (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
")

