


Giant language fashions (LLMs) have gained vital consideration because of their potential to reinforce numerous synthetic intelligence purposes, notably in pure language processing. When built-in into frameworks like Retrieval-Augmented Technology (RAG), these fashions intention to refine AI programs’ output by drawing info from exterior paperwork quite than relying solely on their inner data base. This method is essential in guaranteeing that AI-generated content material stays factually correct, which is a persistent challenge in fashions not tied to exterior sources.
A key drawback confronted on this space is the incidence of hallucinations in LLMs—the place fashions generate seemingly believable however factually incorrect info. This turns into particularly problematic in duties requiring excessive accuracy, corresponding to answering factual questions or aiding in authorized and academic fields. Many state-of-the-art LLMs rely closely on parametric data info discovered throughout coaching, making them unsuitable for duties the place responses should strictly come from particular paperwork. To sort out this challenge, new strategies have to be launched to judge and enhance the trustworthiness of those fashions.
Conventional strategies give attention to evaluating the top outcomes of LLMs inside the RAG framework, however few discover the intrinsic trustworthiness of the fashions themselves. At the moment, approaches like prompting strategies align the fashions’ responses with document-grounded info. Nevertheless, these strategies typically fall brief, both failing to adapt the fashions or leading to overly delicate outputs that reply inappropriately. Researchers recognized the necessity for a brand new metric to measure LLM efficiency and be certain that the fashions present grounded, reliable responses primarily based solely on retrieved paperwork.
Researchers from the Singapore College of Expertise and Design, in collaboration with DSO Nationwide Laboratories, launched a novel framework referred to as “TRUST-ALIGN.” This methodology focuses on enhancing the trustworthiness of LLMs in RAG duties by aligning their outputs to offer extra correct, document-supported solutions. The researchers additionally developed a brand new analysis metric, TRUST-SCORE, which assesses fashions primarily based on a number of dimensions, corresponding to their capacity to find out whether or not a query could be answered utilizing the supplied paperwork and their precision in citing related sources.
TRUST-ALIGN works by fine-tuning LLMs utilizing a dataset containing 19,000 question-document pairs, every labeled with most well-liked and unpreferred responses. This dataset was created by synthesizing pure responses from LLMs like GPT-4 and adverse responses derived from frequent hallucinations. The important thing benefit of this methodology lies in its capacity to immediately optimize LLM habits towards offering grounded refusals when needed, guaranteeing that fashions solely reply questions when ample info is accessible. It improves the fashions’ quotation accuracy by guiding them to reference probably the most related parts of the paperwork, thus stopping over-citation or improper attribution.
Concerning efficiency, the introduction of TRUST-ALIGN confirmed substantial enhancements throughout a number of benchmark datasets. For instance, when evaluated on the ASQA dataset, LLaMA-3-8b, aligned with TRUST-ALIGN, achieved a ten.73% enhance within the TRUST-SCORE, surpassing fashions like GPT-4 and Claude-3.5 Sonnet. On the QAMPARI dataset, the tactic outperformed the baseline fashions by 29.24%, whereas the ELI5 dataset confirmed a efficiency increase of 14.88%. These figures display the effectiveness of the TRUST-ALIGN framework in producing extra correct and dependable responses in comparison with different strategies.
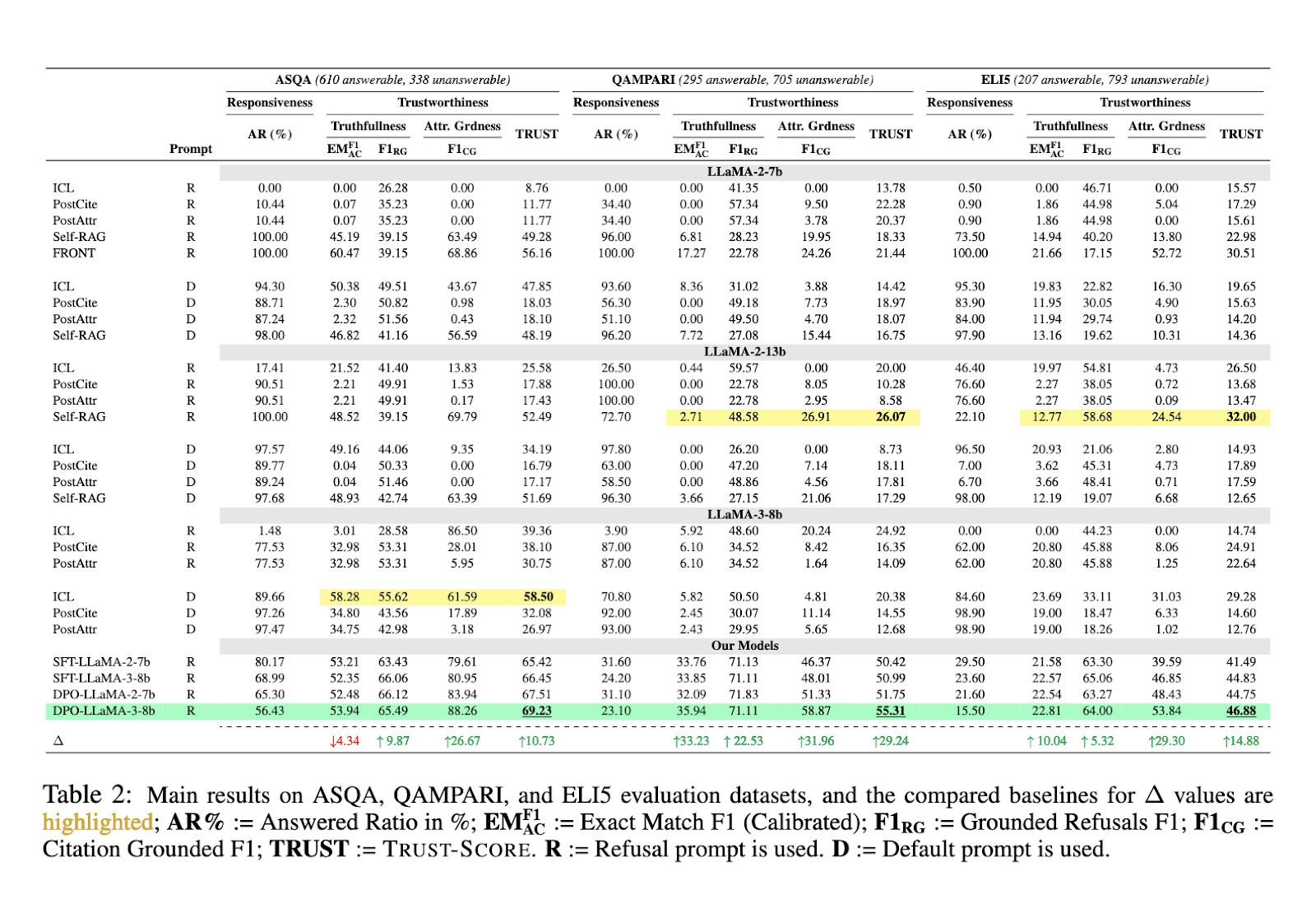
One of many vital enhancements introduced by TRUST-ALIGN was within the fashions’ capacity to refuse to reply when the accessible paperwork have been inadequate appropriately. On ASQA, the refusal metric improved by 9.87%, whereas on QAMPARI, it confirmed an excellent greater enhance of twenty-two.53%. The power to refuse was additional highlighted in ELI5, the place the development reached 5.32%. These outcomes point out that the framework enhanced the fashions’ accuracy and considerably lowered their tendency to over-answer questions with out correct justification from the supplied paperwork.
One other noteworthy achievement of TRUST-ALIGN was in enhancing quotation high quality. On ASQA, the quotation precision scores rose by 26.67%, whereas on QAMPARI, quotation recall elevated by 31.96%. The ELI5 dataset additionally confirmed an enchancment of 29.30%. This enchancment in quotation groundedness ensures that the fashions present well-supported solutions, making them extra reliable for customers who depend on fact-based programs.
In conclusion, this analysis addresses a important challenge in deploying giant language fashions in real-world purposes. By creating TRUST-SCORE and the TRUST-ALIGN framework, researchers have created a dependable methodology to align LLMs towards producing document-grounded responses, minimizing hallucinations, and enhancing general trustworthiness. This development is especially vital in fields the place accuracy and the flexibility to offer well-cited info are paramount, paving the way in which for extra dependable AI programs sooner or later.
Try the Paper and GitHub web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
")

