

 Prompting: A Complete Evaluation Reveals Restricted Effectiveness Past Math and Symbolic Reasoning")
Chain-of-thought (CoT) prompting has emerged as a well-liked method to boost massive language fashions’ (LLMs) problem-solving skills by producing intermediate steps. Regardless of its higher efficiency in mathematical reasoning, CoT’s effectiveness in different domains stays questionable. Present analysis is concentrated extra on mathematical issues, probably overlooking how CoT may very well be utilized extra broadly. In some areas, CoT exhibits restricted enchancment and even decreased efficiency. This slender give attention to mathematical reasoning raises issues concerning the generalizability of CoT and highlights the necessity for a extra detailed analysis of reasoning strategies throughout completely different downside varieties.
Current analysis consists of varied approaches to boost LLMs’ reasoning capabilities past CoT. One of many approaches is Lengthy-horizon planning which has emerged as a promising space in duties like advanced decision-making sequences. Nonetheless, the controversy on CoT’s effectiveness in planning duties stays divided, with research supporting and questioning its utility. Different strategies like tree-of-thought have been developed to handle planning challenges, leading to extra advanced methods. Theoretical analysis signifies that CoT augments Transformers, opening the door for extra superior CoT variants. Latest work on internalizing CoT additionally means that the complete potential of specific intermediate token era has but to be realized.
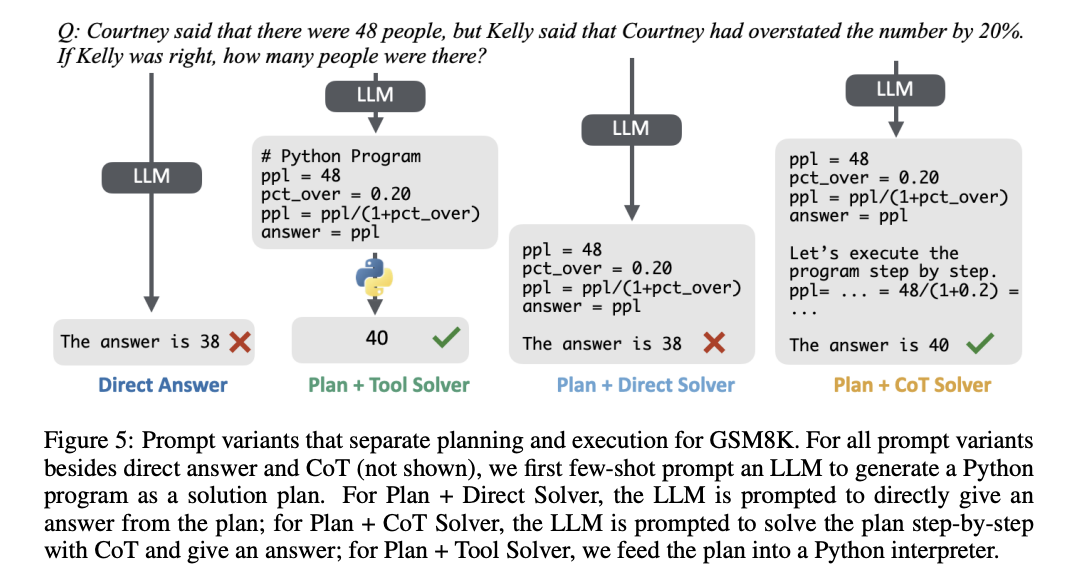
Researchers from the College of Texas at Austin, Johns Hopkins College, and Princeton College have proposed a complete analysis of CoT prompting throughout various job domains. It features a meta-analysis of over 100 CoT-related papers and authentic evaluations spanning 20 datasets and 14 fashions. The efficiency advantages of CoT are extra centered on mathematical and logical reasoning duties, with minimal enhancements in different areas. It exhibits vital benefits on the MMLU benchmark, particularly when questions or responses contain symbolic operations. The researchers additionally break down CoT’s effectiveness by analyzing its planning and execution features and evaluating it to tool-augmented LLMs.
The researchers utilized detailed methodology to judge CoT throughout varied fashions, datasets, and prompting strategies. It focuses extra on English, instruction-tuned language fashions generally used for common reasoning duties. The chosen datasets cowl varied reasoning classes, like commonsense, data, symbolic, mathematical, and tender reasoning. For implementation, researchers used vLLM, a high-throughput inference bundle, with grasping decoding utilized to all fashions. Most prompts are derived from Llama 3.1 evaluations, with changes made for consistency, and customized reply parsers are created for every dataset and mannequin to make sure correct outcome extraction and evaluation.
The analysis outcomes reveal vital variations within the effectiveness of CoT throughout various fashions and datasets. The mixture of planning and execution (both by way of CoT or a direct solver) for duties like mathematical reasoning, outperforms direct answering. Nonetheless, the planning alone doesn’t account for a lot of the efficiency positive factors. CoT and Plan + CoT solver strategies present the strongest accuracy enhancements, particularly in math-heavy datasets. Furthermore, the Plan + Software solver methodology outperforms different strategies throughout most situations, highlighting the constraints of LLMs in executing and monitoring advanced steps in comparison with specialised symbolic solvers. These findings point out that CoT’s foremost benefit lies in its capability, to deal with duties that want detailed tracing and computation.
On this paper, researchers have launched a complete analysis of CoT, prompting throughout various job domains. This analysis of CoT prompting reveals its restricted effectiveness throughout various language duties. The advantages of CoT are extra centered on mathematical and formal logic issues, no matter prompting methods or mannequin power. Additional evaluation exhibits that CoT’s efficiency enhancements are largely as a consequence of its capability to hint intermediate steps in problem-solving. Nonetheless, devoted symbolic solvers constantly outperform CoT in these areas. This research highlighted the necessity for ongoing innovation in language mannequin reasoning capabilities to handle the complete vary of challenges in pure language processing.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Neglect to affix our 50k+ ML SubReddit

Sajjad Ansari is a remaining yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a give attention to understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.


