

: A Novel Analysis Metric for Method Recognition")
Mathematical system recognition has progressed considerably, pushed by deep studying strategies and the Transformer structure. Conventional OCR strategies show inadequate because of the advanced buildings of mathematical expressions, requiring fashions to know spatial and structural relationships. The sector faces challenges in representational range, as formulation can have a number of legitimate representations. Current developments, together with business instruments like Mathpix and fashions reminiscent of UniMERNet, display the potential of deep studying in real-world functions.
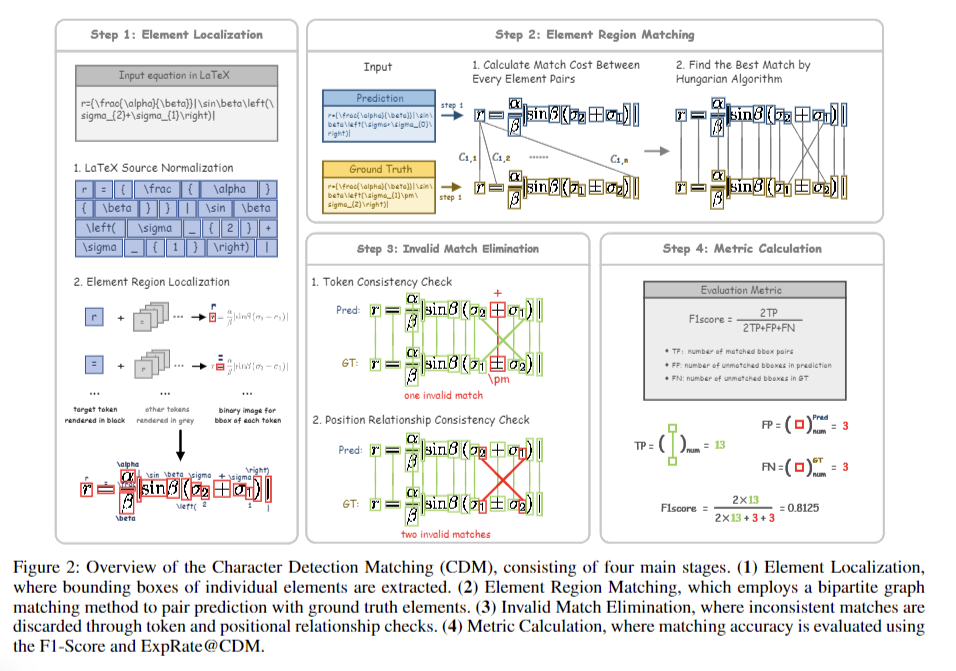
Regardless of these developments, present analysis metrics for system recognition exhibit important limitations. Generally used metrics like BLEU and Edit Distance focus totally on text-based character matching, failing to precisely replicate recognition high quality as a result of various system representations. This results in low reliability, unfair mannequin comparisons, and a scarcity of intuitive scoring. The necessity for improved analysis strategies that account for the distinctive challenges of system recognition has turn into evident, prompting the event of recent approaches, such because the Character Detection Matching (CDM) metric proposed.
Mathematical system recognition faces distinctive challenges as a result of advanced buildings and assorted notations. Regardless of developments in recognition fashions, current analysis metrics like BLEU and Edit Distance exhibit limitations in dealing with various system representations. This paper introduces CDM, a novel analysis metric that treats system recognition as an image-based object detection job. CDM renders predicted and ground-truth LaTeX formulation into photographs, using visible function extraction and localization for exact character-level matching. This spatially-aware method gives extra correct and equitable analysis, aligning carefully with human requirements and offering fairer mannequin comparisons. CDM addresses the necessity for improved analysis strategies in system recognition, enhancing objectivity and reliability in evaluation.
Researchers from Shanghai AI Laboratory and Shanghai Jiao Tong College developed a complete methodology for evaluating system recognition. Their method begins with changing PDF pages to photographs for mannequin enter, adopted by system extraction utilizing tailor-made common expressions. The method compiles acknowledged formulation into textual content recordsdata for every PDF, facilitating subsequent matching. The methodology employs extraction algorithms to establish displayed formulation from mannequin outputs, that are then matched in opposition to floor fact formulation. This systematic method allows the computation of analysis metrics, together with BLEU and the newly launched CDM metric.
Intensive experiments had been carried out to validate the effectiveness of the CDM metric. Outcomes from the Tiny-Doc-Math analysis demonstrated CDM’s reliability in 96% of circumstances, with the remaining discrepancies attributed to LaTeX points. The experimentation critically analyzed current image-based analysis strategies, illustrating particular circumstances the place conventional metrics fail to precisely replicate recognition errors. Complete testing throughout varied mainstream fashions and datasets highlighted CDM’s superiority in offering honest and intuitive assessments of system recognition efficiency. This intensive validation positions CDM as a promising various for future analysis and enhancements within the subject.
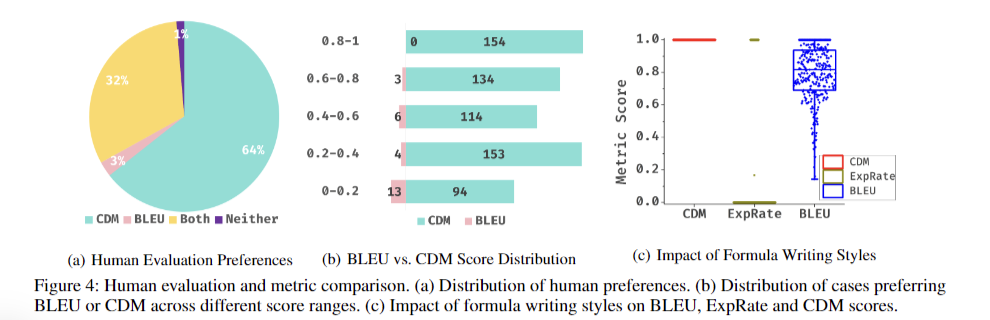
The Tiny-Doc-Math analysis revealed customers most popular the CDM rating over BLEU in 64% of circumstances, reflecting CDM’s superior accuracy in assessing prediction high quality. Evaluation of person preferences confirmed CDM excelled when predictions had been completely right however BLEU scores had been unexpectedly low. Each metrics carried out equally nicely in 32% of circumstances, whereas BLEU outperformed CDM in 3% of situations the place token illustration inconsistencies had been detected. Experiments demonstrated passable mannequin efficiency with simply 10% of coaching knowledge, suggesting potential redundancy within the full dataset. Arduous case choice recognized an extra 9,734 samples, enhancing mannequin efficiency to ranges comparable with full dataset coaching.
Conventional metrics like BLEU and Edit Distance exhibited important limitations, notably with area gaps between coaching and testing knowledge distributions. These metrics struggled with the non-unique nature of LaTeX representations for formulation, complicating correct analysis. In distinction, CDM demonstrated enhanced reliability and effectiveness in offering honest assessments of mannequin efficiency throughout varied situations. The outcomes underscore CDM’s potential to considerably enhance system recognition analysis, addressing the shortcomings of current metrics and providing a extra sturdy method to assessing mannequin accuracy in various contexts.
In conclusion, the CDM metric addresses the crucial limitations of conventional analysis strategies in system recognition. By changing predicted and ground-truth LaTeX formulation into photographs for character-level matching, CDM gives a extra dependable and goal evaluation that includes spatial info. Experimental outcomes display CDM’s superior alignment with human evaluations in comparison with BLEU and Edit Distance, offering fairer comparisons throughout fashions and successfully capturing nuances in system rendering. The analysis advocates for CDM’s adoption as a normal metric in system recognition, doubtlessly driving developments in mannequin growth. CDM’s skill to get rid of discrepancies brought on by various system representations marks a big step towards extra correct and equitable analysis on this subject.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group.
📨 Should you like our work, you’ll love our E-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit

Shoaib Nazir is a consulting intern at MarktechPost and has accomplished his M.Tech twin diploma from the Indian Institute of Expertise (IIT), Kharagpur. With a powerful ardour for Information Science, he’s notably within the various functions of synthetic intelligence throughout varied domains. Shoaib is pushed by a need to discover the newest technological developments and their sensible implications in on a regular basis life. His enthusiasm for innovation and real-world problem-solving fuels his steady studying and contribution to the sphere of AI


