

 Benchmark for Evaluating Multimodal Understanding in AI Fashions")
Multimodal massive language fashions (MLLMs) are more and more utilized in various fields similar to medical picture evaluation, engineering diagnostics, and even schooling, the place understanding diagrams, charts, and different visible information is important. The complexity of those duties requires MLLMs to seamlessly change between various kinds of data whereas performing superior reasoning.
The first problem researchers face on this space has been making certain that AI fashions genuinely comprehend multimodal duties moderately than counting on easy statistical patterns to derive solutions. Earlier benchmarks for evaluating MLLMs allowed fashions to take shortcuts, generally arriving at right solutions by exploiting predictable query constructions or correlations with out understanding the visible content material. This has raised issues concerning the precise capabilities of those fashions in dealing with real-world multimodal issues successfully.
To deal with this subject, current instruments for testing AI fashions have to be deemed inadequate. Present benchmarks didn’t differentiate between fashions that used true multimodal understanding and those who relied on text-based patterns. In consequence, the analysis workforce highlighted the necessity for a extra sturdy analysis system to check the depth of reasoning and understanding in multimodal contexts. These shortcomings indicated the need of a more difficult and rigorous strategy to assessing MLLMs.
Researchers from Carnegie Mellon College and different establishments launched a brand new benchmark referred to as MMMU-Professional, particularly designed to push the boundaries of AI programs’ multimodal understanding. This improved benchmark targets the weaknesses in earlier exams by filtering out questions solvable by text-only fashions and rising the issue of multimodal questions. The benchmark was developed with main firms, together with OpenAI, Google, and Anthropic. It introduces options like vision-only enter situations and multiple-choice questions with augmented choices, making it considerably more difficult for fashions to take advantage of easy patterns for solutions.
The methodology behind MMMU-Professional is thorough and multilayered. The benchmark’s building concerned three major steps: first, researchers filtered out questions answerable by text-only fashions by using a number of language fashions to check every query. Any query that could possibly be persistently answered with out visible enter was eliminated. Second, they elevated the variety of reply choices from 4 to 10 in lots of questions, decreasing the effectiveness of random guessing. Lastly, they launched a vision-only enter setting, the place fashions had been offered with photos or screenshots containing the question-and-answer choices. This step is essential because it mimics real-world conditions the place textual content and visible data are intertwined, difficult fashions to know each modalities concurrently.

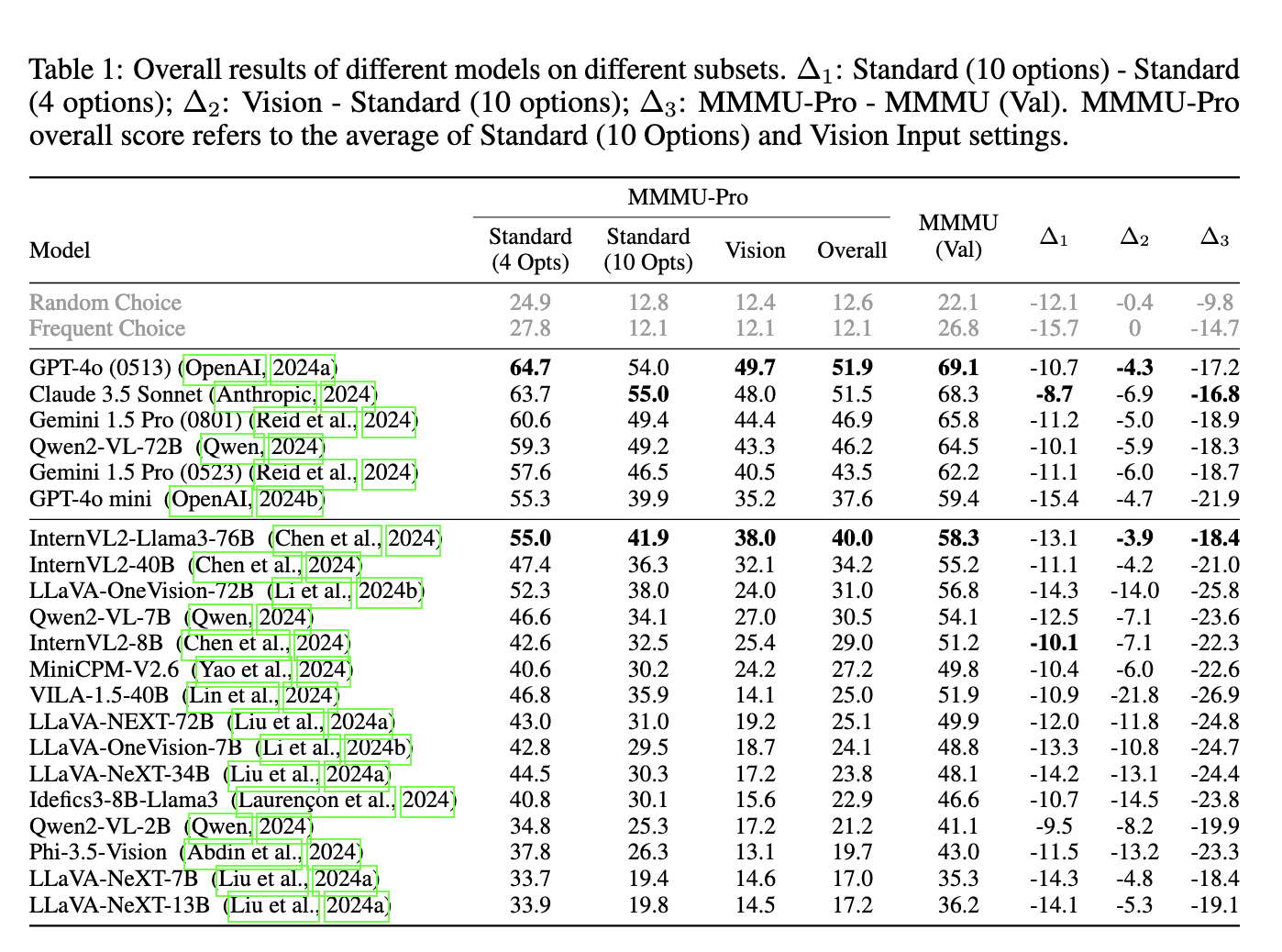
By way of efficiency, MMMU-Professional revealed the constraints of many state-of-the-art fashions. The common accuracy for fashions like GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Professional dropped considerably when examined in opposition to this new benchmark. For instance, GPT-4o noticed a drop from 69.1% on the unique MMMU benchmark to 54.0% on MMMU-Professional when evaluated utilizing ten candidate choices. In the meantime, Claude 3.5 Sonnet, developed by Anthropic, skilled a efficiency discount of 16.8%, whereas Gemini 1.5 Professional, from Google, noticed a lower of 18.9%. Probably the most drastic decline was noticed in VILA-1.5-40B, which skilled a 26.9% drop. These numbers underscore the benchmark’s skill to spotlight the fashions’ deficiencies in true multimodal reasoning.
Chain of Thought (CoT) reasoning prompts had been launched as a part of the analysis to enhance mannequin efficiency by encouraging step-by-step reasoning. Whereas this technique confirmed some enhancements, the extent of success diversified throughout fashions. For example, Claude 3.5 Sonnet’s accuracy elevated to 55.0% with CoT, however fashions like LLaVA-OneVision-72B confirmed minimal enhancements, and a few fashions even confronted efficiency drops. This highlights the complexity of MMMU-Professional and its challenges to present multimodal fashions.
The MMMU-Professional benchmark gives essential insights into multimodal AI mannequin efficiency gaps. Regardless of advances in OCR (Optical Character Recognition) and CoT reasoning, the fashions nonetheless struggled with integrating textual content and visible parts meaningfully, notably in vision-only settings the place no express textual content was supplied. This additional emphasizes the necessity for improved AI programs to deal with the complete spectrum of multimodal challenges.
In conclusion, MMMU-Professional marks a major development in evaluating multimodal AI programs. It efficiently identifies the constraints in current fashions, similar to their reliance on statistical patterns, and presents a extra real looking problem for assessing true multimodal understanding. This benchmark opens new instructions for future analysis, pushing the event of better-equipped fashions to combine complicated visible and textual information. The analysis workforce’s work represents an essential step ahead within the quest for AI programs able to performing subtle reasoning in real-world purposes.
Try the Paper and Leaderboard. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and LinkedIn. Be a part of our Telegram Channel.
In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


