


The Giant Language Fashions (LLMs) are extremely promising in Synthetic Intelligence. Nonetheless, regardless of coaching on massive datasets overlaying numerous languages
and matters, the flexibility to grasp and generate textual content is usually overstated. LLM purposes throughout a number of domains have confirmed to have little influence on enhancing human-computer interactions or creating modern options. It is because the deep layers of the LLMS don’t contribute a lot and, if eliminated, don’t have an effect on their efficiency. This underutilization of deep layers reveals inefficiency inside the fashions.
Present strategies confirmed that deeper layers of LLMs contributed little to their efficiency. Though used to stabilize coaching, methods like pre-LN and post-LN confirmed important limitations. Pre-LN decreased the magnitude of gradients in deeper layers, limiting their effectiveness, whereas post-LN induced gradients to fade in earlier layers. Regardless of efforts to deal with these points via dynamic linear mixtures and Adaptive Mannequin Initialization, these methods don’t totally optimize LLM efficiency.
To handle this subject, researchers from the Dalian College of Expertise, the College of Surrey, the Eindhoven College of Expertise, and the College of Oxford proposed Combine-LN. This normalization approach combines the strengths of Pre-LN and Put up-LN inside the similar mannequin. Combine-LN applies Put up-LN to the sooner layers and Pre-LN to the deeper layers to make sure extra uniform gradients. This method permits each shallow and deep layers to contribute successfully to coaching. The researchers evaluated the speculation that deeper layers in LLMs had been inefficient on account of pre-LN. The primary distinction between post-LN and pre-LN architectures is layer normalization (LN) placement. In post-LN, LN is utilized after the residual addition, whereas in pre-LN, it’s used earlier than.
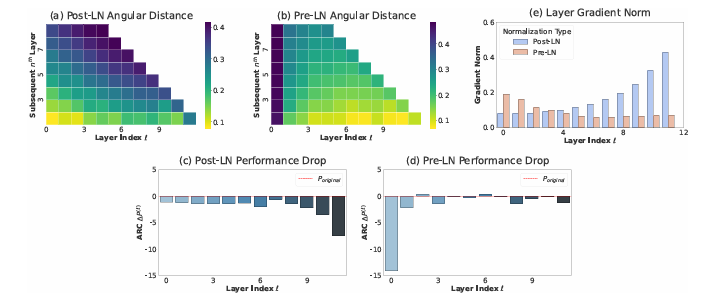
Researchers in contrast pre- and post-LN fashions in large-scale open-weight and small-scale in-house LLMs. Metrics reminiscent of angular distance and efficiency drop assessed layer effectiveness. Early layers had been much less efficient in BERT-Giant (Put up-LN) than in deeper layers. In LLaMa2-7B (Pre-LN), deeper layers had been much less efficient, and pruning them confirmed minimal efficiency influence. Researchers noticed comparable traits in LLaMa-130M, the place Pre-LN layers had been much less efficient at deeper ranges, and Put up-LN maintained higher efficiency in deeper layers. These outcomes urged that Pre-LN induced the inefficiency of deeper layers.
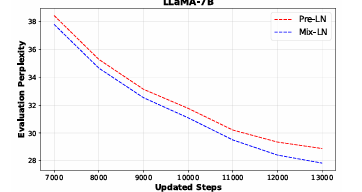
The optimum Put up-LN ratio α for Combine-LN was decided via experiments with LLaMA-1B on the C4 dataset. The perfect efficiency occurred at α = 0.25, the place perplexity was lowest. For the remaining layers, efficiency decreased however remained larger than the efficiency recorded by Pre-LN in comparison with the layers that adopted Put up-LN. Combine-LN additionally supported a broader vary of representations and maintained a more healthy gradient norm for deeper layers to contribute successfully. Combine-LN achieved considerably low perplexity scores, outperforming different normalization strategies.
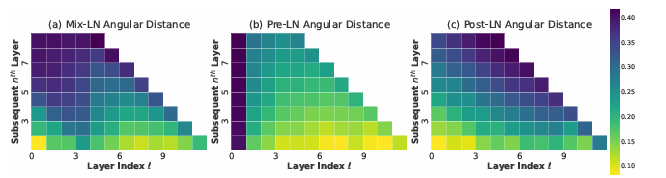
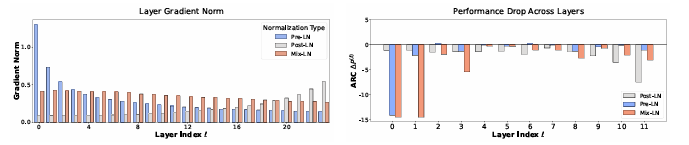
In conclusion, the researchers recognized inefficiencies brought on by Pre-LN in deep layers of enormous language fashions (LLMs) and proposed Combine-LN as an answer. Experiments confirmed that Combine-LN outperformed each Pre-LN and Put up-LN, enhancing mannequin efficiency throughout pre-training and fine-tuning with out growing mannequin measurement. This method can act as a baseline for future analysis, providing a basis for additional enhancements in coaching deep fashions and advancing mannequin effectivity and capability.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for World Management in Generative AI Excellence….
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Information Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and resolve challenges.
")

