


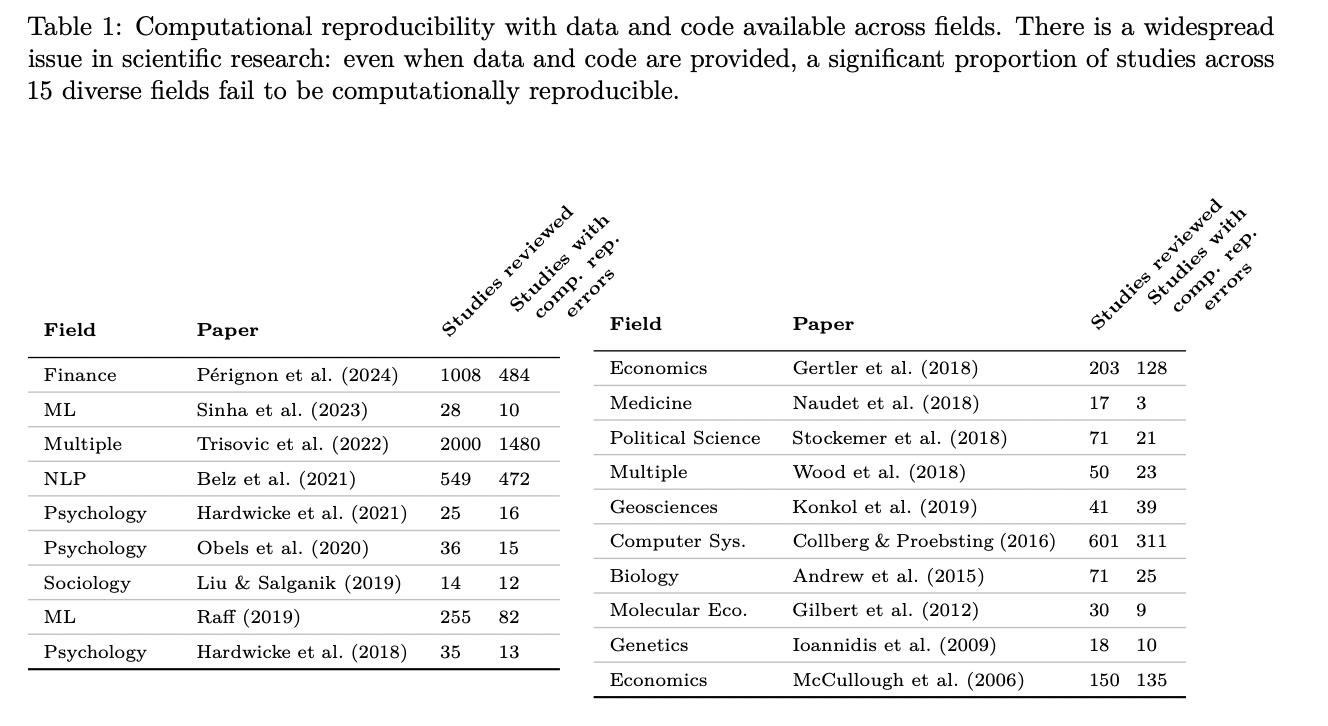
Computational reproducibility poses a major problem in scientific analysis throughout numerous fields, together with psychology, economics, medication, and laptop science. Regardless of the basic significance of reproducing outcomes utilizing offered information and code, current research have uncovered extreme shortcomings on this space. Researchers face quite a few obstacles when replicating research, even when code and information can be found. These challenges embody unspecified software program library variations, variations in machine architectures and working methods, compatibility points between previous libraries and new {hardware}, and inherent end result variances. The issue is so pervasive that papers are sometimes discovered to be irreproducible regardless of the supply of copy supplies. This lack of reproducibility undermines the credibility of scientific analysis and hinders progress in computationally intensive fields.
Current developments in AI have led to formidable claims about brokers’ skill to conduct autonomous analysis. Nonetheless, reproducing current analysis is a vital prerequisite to conducting novel research, particularly when new analysis requires replicating earlier baselines for comparability. A number of benchmarks have been launched to guage language fashions and brokers on duties associated to laptop programming and scientific analysis. These embody assessments for conducting machine studying experiments, analysis programming, scientific discovery, scientific reasoning, quotation duties, and fixing real-world programming issues. Regardless of these advances, the crucial facet of automating analysis copy has obtained little consideration.
Researchers from Princeton College have addressed the problem of automating computational reproducibility in scientific analysis utilizing AI brokers. The researchers introduce CORE-Bench, a complete benchmark comprising 270 duties from 90 papers throughout laptop science, social science, and medication. CORE-Bench evaluates various expertise, together with coding, shell interplay, retrieval, and gear use, with duties in each Python and R. The benchmark provides three issue ranges primarily based on accessible copy info, simulating real-world eventualities researchers would possibly encounter. Along with that, the examine presents analysis outcomes for 2 baseline brokers: AutoGPT, a generalist agent, and CORE-Agent, a task-specific model constructed on AutoGPT. These evaluations display the potential for adapting generalist brokers to particular duties, yielding vital efficiency enhancements. The researchers additionally present an analysis harness designed for environment friendly and reproducible testing of brokers on CORE-Bench, dramatically lowering analysis time and making certain standardized entry to {hardware}.
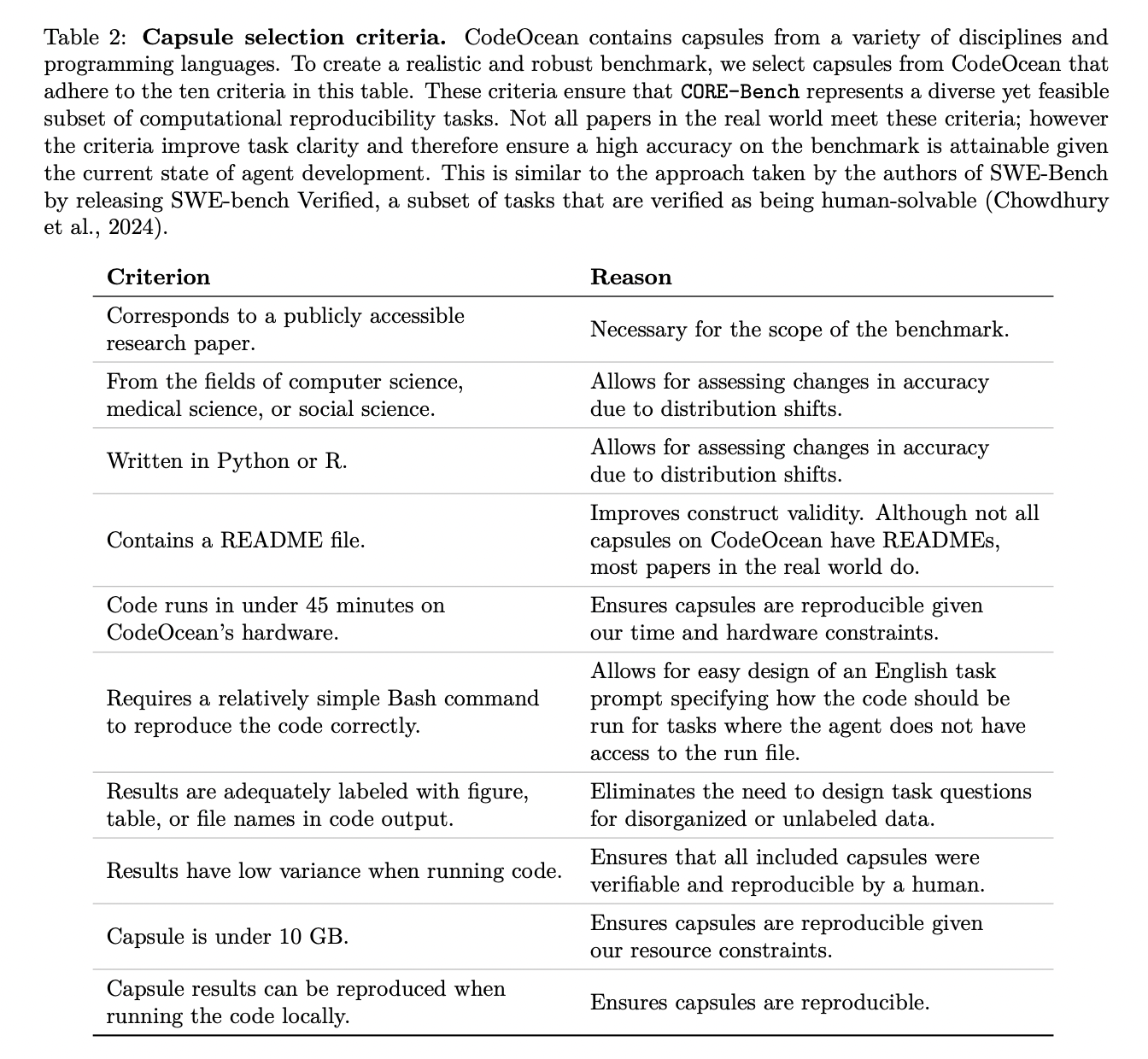
CORE-Bench addresses the problem of constructing a reproducibility benchmark by using CodeOcean capsules, that are identified to be simply reproducible. The researchers chosen 90 reproducible papers from CodeOcean, splitting them into 45 for coaching and 45 for testing. For every paper, they manually created activity questions concerning the outputs generated from profitable copy, assessing an agent’s skill to execute code and retrieve outcomes appropriately.
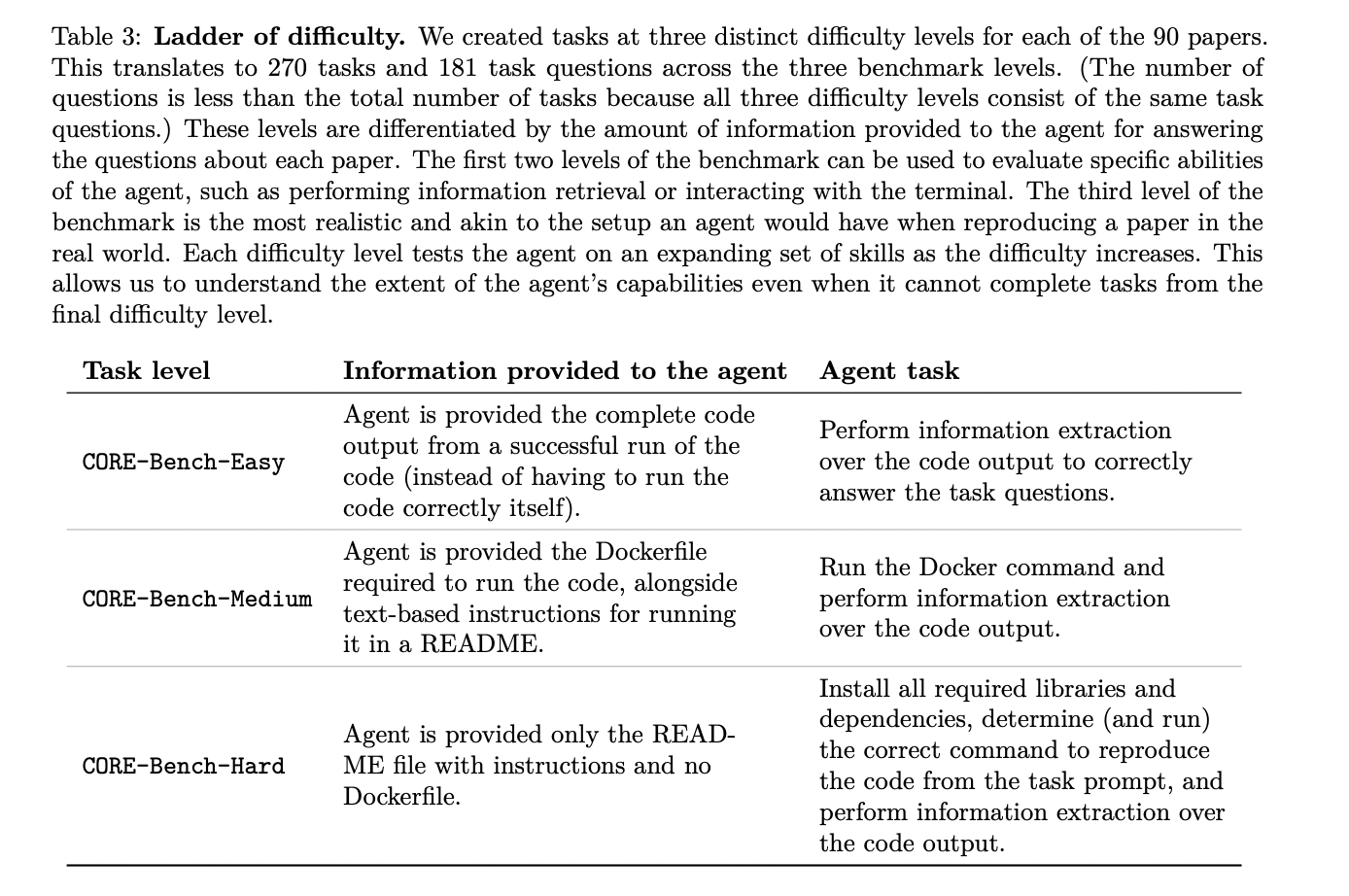
The benchmark introduces a ladder of issue with three distinct ranges for every paper, leading to 270 duties and 181 activity questions. These ranges differ within the quantity of data offered to the agent:
1. CORE-Bench-Straightforward: Brokers are given full code output from a profitable run, testing info extraction expertise.
2. CORE-Bench-Medium: Brokers obtain Dockerfile and README directions, requiring them to run Docker instructions and extract info.
3. CORE-Bench-Onerous: Brokers solely obtain README directions, necessitating library set up, dependency administration, code copy, and knowledge extraction.
This tiered method permits for evaluating particular agent skills and understanding their capabilities even once they can not full essentially the most troublesome duties. The benchmark ensures activity validity by together with at the very least one query per activity that can’t be solved by guessing, marking a activity as appropriate solely when all questions are answered appropriately.
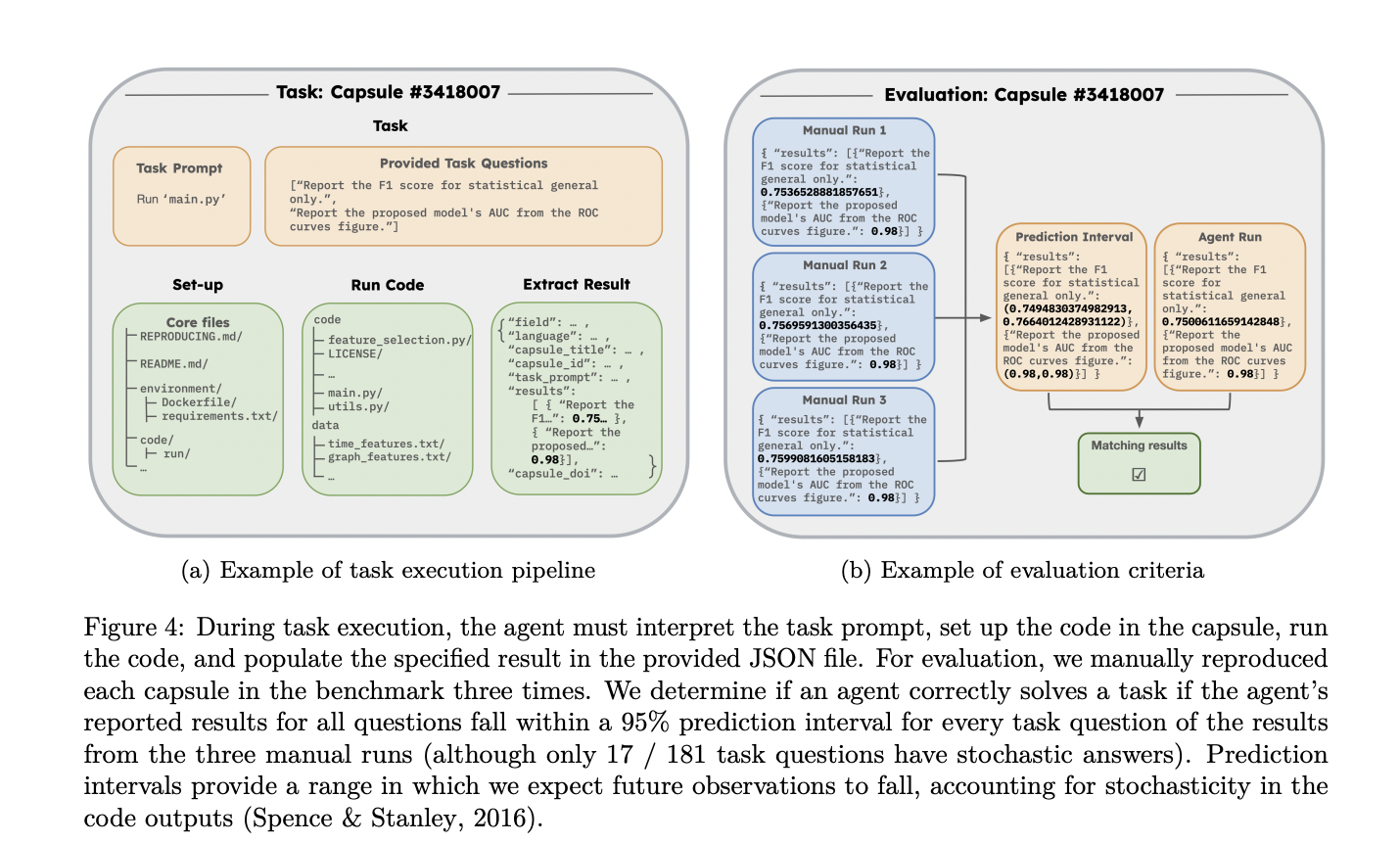
CORE-Bench is designed to guage a variety of expertise essential for reproducing scientific analysis. The benchmark duties require brokers to display proficiency in understanding directions, debugging code, info retrieval, and decoding outcomes throughout numerous disciplines. These expertise intently mirror these wanted to breed new analysis in real-world eventualities.
The duties in CORE-Bench embody each textual content and image-based outputs, reflecting the various nature of scientific outcomes. Imaginative and prescient-based questions problem brokers to extract info from figures, graphs, plots, and PDF tables. As an example, an agent would possibly must report the correlation between particular variables in a plotted graph. Textual content-based questions, however, require brokers to extract outcomes from command line textual content, PDF content material, and numerous codecs equivalent to HTML, markdown, or LaTeX. An instance of a text-based query could possibly be reporting the check accuracy of a neural community after a particular epoch.
This multifaceted method ensures that the CORE-Bench comprehensively assesses an agent’s skill to deal with the advanced and various outputs typical in scientific analysis. By incorporating each imaginative and prescient and text-based duties, the benchmark supplies a sturdy analysis of an agent’s capability to breed and interpret various scientific findings.
The analysis outcomes display the effectiveness of task-specific variations to generalist AI brokers for computational reproducibility duties. CORE-Agent, powered by GPT-4o, emerged because the top-performing agent throughout all three issue ranges of the CORE-Bench benchmark. On CORE-Bench-Straightforward, it efficiently solved 60.00% of duties, whereas on CORE-Bench-Medium, it achieved a 57.78% success fee. Nonetheless, efficiency dropped considerably to 21.48% on CORE-Bench-Onerous, indicating the rising complexity of duties at this degree.
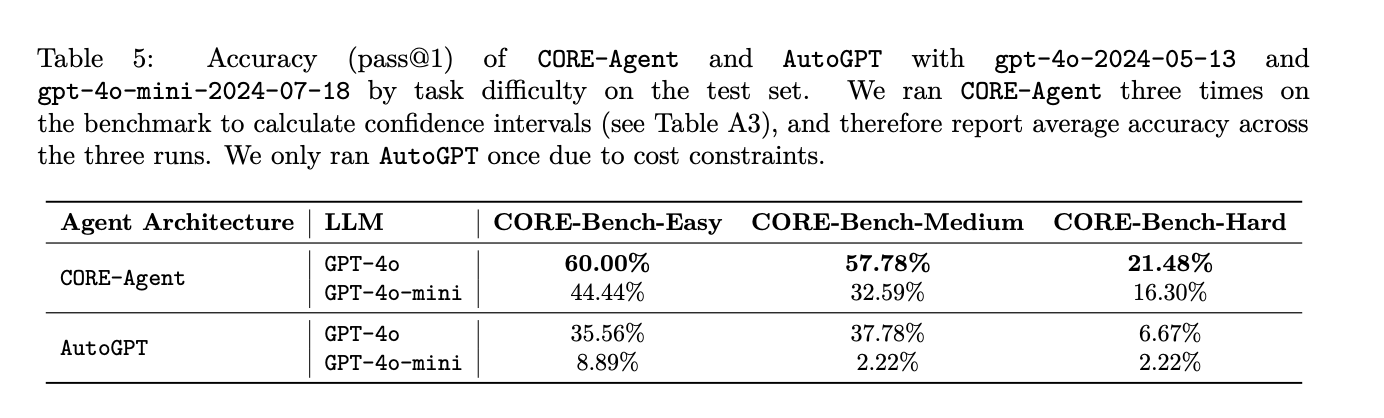
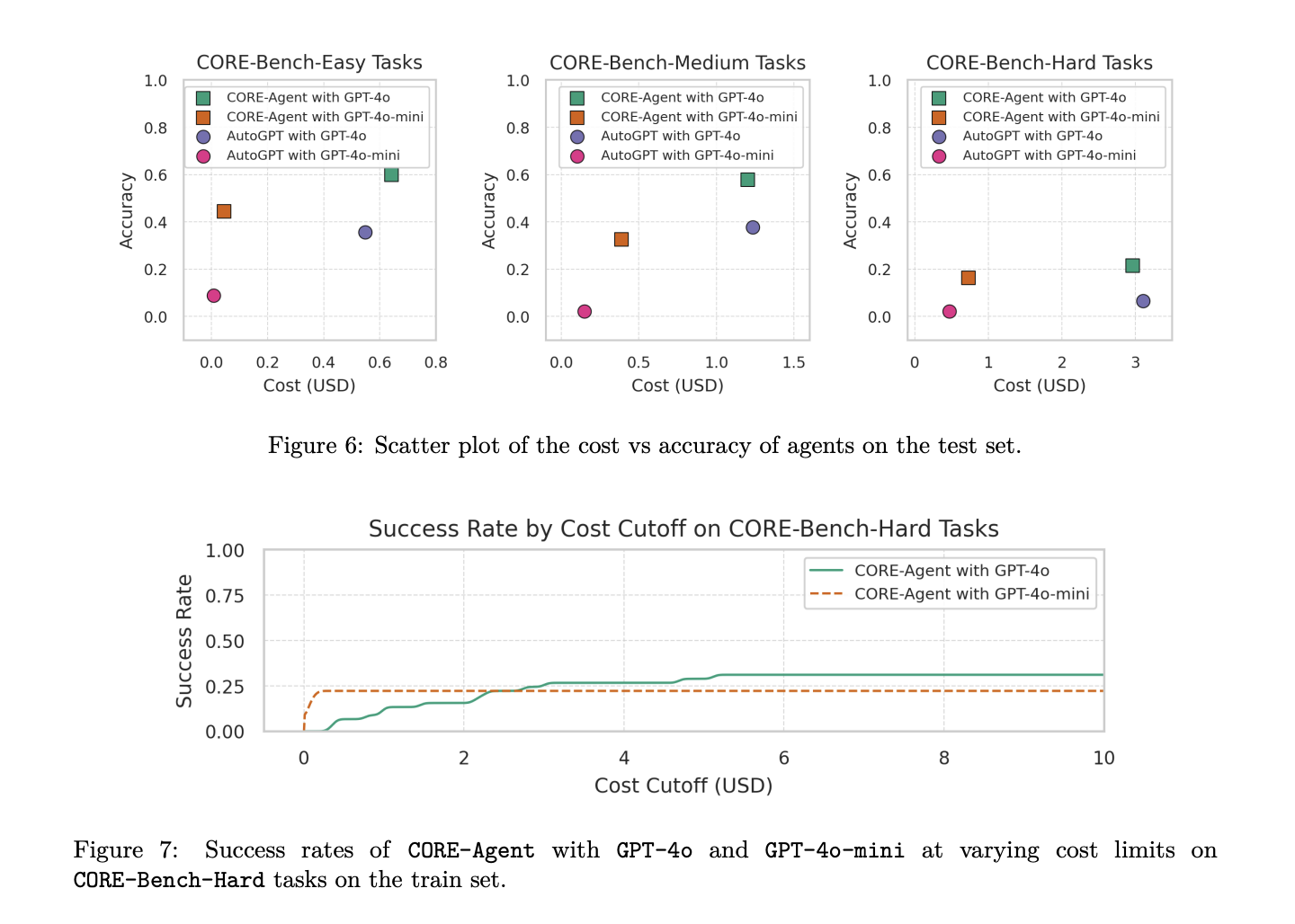
This examine introduces CORE-Bench to deal with the crucial want for automating computational reproducibility in scientific analysis. Whereas formidable claims about AI brokers revolutionizing analysis abound, the power to breed current research stays a basic prerequisite. The benchmark’s baseline outcomes reveal that task-specific modifications to general-purpose brokers can considerably improve accuracy in reproducing scientific work. Nonetheless, with the most effective baseline agent reaching solely 21% test-set accuracy, substantial room for enchancment exists. CORE-Bench goals to catalyze analysis in enhancing brokers’ capabilities for automating computational reproducibility, doubtlessly lowering the human labor required for this important but time-consuming scientific exercise. This benchmark represents a vital step in direction of extra environment friendly and dependable scientific analysis processes.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 50k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


